
ฐานข้อมูล NoSQL: ความพร้อมใช้งานสูงและความสามารถในการปรับขนาดผ่านการจำลองแบบ
เผยแพร่แล้ว: 2022-11-19ฐานข้อมูล NoSQL มีหลายประเภท แต่ละประเภทมีความสามารถและคุณลักษณะเฉพาะของตนเอง อย่างไรก็ตาม ลักษณะทั่วไปประการหนึ่งของฐานข้อมูล NoSQL จำนวนมากคือความสามารถในการทำซ้ำข้อมูลข้ามเซิร์ฟเวอร์หลายเครื่อง การจำลองแบบเป็นกระบวนการคัดลอกข้อมูลจากเซิร์ฟเวอร์หนึ่งไปยังอีกเซิร์ฟเวอร์หนึ่ง เพื่อให้ข้อมูลพร้อมใช้งานบนเซิร์ฟเวอร์หลายเครื่อง การจำลองสามารถเพิ่มความพร้อมใช้งานและประสิทธิภาพโดยอนุญาตให้อ่านข้อมูลจากเซิร์ฟเวอร์หลายเครื่อง โดยทั่วไปแล้ว ฐานข้อมูล NoSQL จะใช้โมเดลการจำลองมาสเตอร์-สเลฟ ซึ่งเซิร์ฟเวอร์หนึ่งถูกกำหนดให้เป็นมาสเตอร์และเซิร์ฟเวอร์อื่นๆ ทั้งหมดเป็นทาส เซิร์ฟเวอร์หลักจะรักษาสำเนาของข้อมูลและจำลองการเปลี่ยนแปลงไปยังสเลฟ สามารถใช้สเลฟเพื่ออ่านข้อมูลได้ แต่การเขียนทั้งหมดต้องผ่านมาสเตอร์ ข้อดีอย่างหนึ่งของการจำลองแบบคือสามารถช่วยปรับปรุงประสิทธิภาพโดยการกระจายการอ่านไปยังเซิร์ฟเวอร์หลายเครื่อง การจำลองแบบยังสามารถปรับปรุงความพร้อมใช้งานโดยการจัดเตรียมสำเนาข้อมูลหลายชุดในกรณีที่เซิร์ฟเวอร์เครื่องหนึ่งล้มเหลว โดยทั่วไปแล้ว ฐานข้อมูล NoSQL จะมีความพร้อมใช้งานสูงและสามารถปรับขนาดได้เนื่องจากความสามารถในการทำซ้ำข้อมูลในเซิร์ฟเวอร์หลายเครื่อง
ในทำนองเดียวกัน NoSQL Data Replication เป็นคุณลักษณะที่มีประสิทธิภาพที่ช่วยให้คุณสามารถคัดลอกและจัดเก็บข้อมูลที่มีโครงสร้าง ไม่มีโครงสร้าง และกึ่งโครงสร้างได้อย่างราบรื่น รวมทั้งป้องกันข้อมูลสูญหายเมื่อเซิร์ฟเวอร์ล่ม เรียนรู้เพิ่มเติมเกี่ยวกับฐานข้อมูล NoSQL ที่ไซต์นี้
ทั้งการจำลองแบบมาสเตอร์-สเลฟและการรันแบบทาส และการจำลองแบบมาสเตอร์-สเลฟจะกำหนดโหนดเป็นสำเนาที่เชื่อถือได้ซึ่งสามารถจัดการทั้งการเขียนและการอ่าน กระบวนการจำลองแบบเพีย ร์ทูเพียร์ช่วยให้โหนดเขียนถึงกัน และแต่ละโหนดจะคัดลอกข้อมูลไปยังโหนดถัดไป
การจำลองแบบ MongoDB หมายถึงการสร้างชุดแบบจำลองที่แบ่งปันชุดข้อมูลทั่วไปกับ อินสแตนซ์ MongoDB อื่นๆ ชุดแบบจำลองประกอบด้วยโหนดจำนวนหนึ่งที่มีข้อมูล และโหนดที่เป็นอนุญาโตตุลาการเป็นทางเลือก มีโหนดหกโหนดในสภาพแวดล้อมที่มีข้อมูล โดยสมาชิกหนึ่งคนถูกกำหนดให้เป็นโหนดหลักและสมาชิกอื่น ๆ ที่จัดประเภทเป็นโหนดรอง
โดยทั่วไปแล้ว การทดลองหรือขั้นตอนที่ให้ผลลัพธ์มากกว่าจำนวนหนึ่งถือเป็นความสำเร็จ ในกรณีนี้ การจำลองแบบของ DNA จะถูกคัดลอกหรือทำซ้ำ การทำซ้ำบางสิ่งเรียกว่าการจำลองแบบ
การจำลองข้อมูล Nosql คืออะไร?
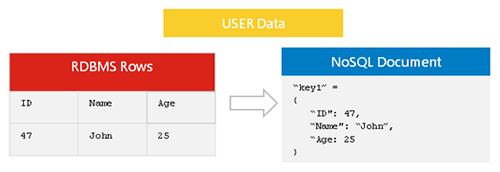
การจำลองข้อมูล Nosql เป็นกระบวนการคัดลอกข้อมูลจาก ฐานข้อมูล nosql หนึ่งไปยังอีกฐานข้อมูลหนึ่ง ซึ่งสามารถทำได้ด้วยเหตุผลหลายประการ เช่น การสร้างข้อมูลสำรอง หรือการกระจายข้อมูลไปยังเซิร์ฟเวอร์หลายเครื่อง โดยทั่วไปแล้วการจำลองข้อมูล Nosql จะดำเนินการแบบอะซิงโครนัส หมายความว่าสำเนาของข้อมูลไม่จำเป็นต้องเป็นสำเนาที่แน่นอนของข้อมูลต้นฉบับ
เป็นเวลาหลายปีที่การจำลองแบบข้อมูลเป็นองค์ประกอบสำคัญของโครงสร้างพื้นฐานข้อมูลขององค์กรใดๆ ระบบการจำลองข้อมูลจะปกป้องข้อมูลของคุณโดยรับประกันความพร้อมใช้งานสูง การสำรองข้อมูล และการกู้คืนระบบ นอกจากนี้ การจำลองแบบยังช่วยในความสามารถขององค์กรในการปรับปรุงความสอดคล้องและความถูกต้องของข้อมูล เป็นวิธีการปรับปรุงความน่าเชื่อถือของข้อมูลผ่านกระบวนการจำลองแบบ ด้วยการจำลองข้อมูล คุณสามารถมั่นใจได้ว่าข้อมูลนั้นจะพร้อมใช้งานอยู่เสมอ สำรองข้อมูล และในกรณีที่เกิดภัยพิบัติ การทำซ้ำข้อมูลยังสามารถปรับปรุงความสอดคล้องและความแม่นยำได้อีกด้วย เมื่อออกแบบโครงสร้างพื้นฐานข้อมูล การพิจารณาการจำลองแบบข้อมูลเป็นสิ่งสำคัญ
Sharding และการจำลองแบบใน Nosql คืออะไร
อะไรคือความแตกต่างระหว่างการแบ่งส่วนย่อยและการจำลองแบบ? โหนดเซิร์ฟเวอร์หลักคัดลอกข้อมูลจากโหนดเซิร์ฟเวอร์รองซึ่งเป็นส่วนหนึ่งของการจำลองข้อมูล คุณสามารถเพิ่มความพร้อมใช้งานของข้อมูลและทำให้เป็นข้อมูลสำรองฉุกเฉินในกรณีที่เซิร์ฟเวอร์หลักล้มเหลว จัดการการปรับขนาดเซิร์ฟเวอร์บนพื้นผิวแนวนอนโดยใช้คีย์ชาร์ด

ฐานข้อมูล Nosql มีความซ้ำซ้อนของข้อมูลหรือไม่
เมื่อมีปริมาณข้อมูลจำนวนมากและสามารถทนต่อ ความซ้ำซ้อนของข้อมูล ได้ ฐานข้อมูล NoSQL จึงเหมาะสมที่สุดสำหรับแอปพลิเคชันบางประเภทและกรณีการใช้งานเฉพาะ
Nosql สามารถแยกชิ้นส่วนได้หรือไม่?
การแบ่งพาร์ติชันตามรูปแบบ microservices ใช้ในสภาพแวดล้อม NoSQL รูปแบบดังกล่าวจะแบ่งแต่ละพาร์ติชันออกเป็นหลายเซิร์ฟเวอร์ ซึ่งอาจหรือไม่ได้อยู่ในตำแหน่งเดียวกันทั่วโลก การปรับสเกลนี้ใช้งานได้ดีกับผู้คนจากทั่วโลกที่ต้องการเข้าถึงส่วนต่างๆ ของชุดข้อมูลและบรรลุประสิทธิภาพสูง
การจำลองแบบในฐานข้อมูลคืออะไร?
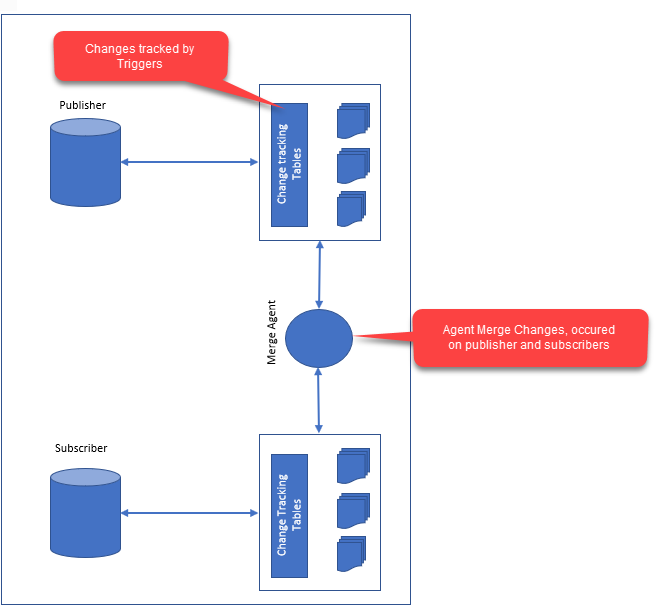
การจำลองแบบในฐานข้อมูลเป็นกระบวนการคัดลอกข้อมูลจากฐานข้อมูลต้นทางไปยังฐานข้อมูลเป้าหมาย ฐานข้อมูลทั้งสองสามารถอยู่บนเซิร์ฟเวอร์เดียวกันหรือบนเซิร์ฟเวอร์ที่แตกต่างกัน การจำลองแบบสามารถใช้เพื่อสร้างข้อมูลสำรอง กระจายข้อมูลไปยังเซิร์ฟเวอร์หลายเครื่อง หรืออนุญาตให้ผู้ใช้หลายคนเข้าถึงข้อมูลได้
ความสมบูรณ์ของข้อมูลและประสิทธิภาพเป็นสิ่งสำคัญของ การจำลองข้อมูลในปัจจุบัน การเขียนข้อมูลซ้ำสามารถทำได้ง่ายๆ เพียงแค่ส่งไปยังสมาชิก หรือซับซ้อนพอๆ กับการทำการทดลองหลายๆ ครั้งพร้อมกัน รูปแบบการจำลองแบบที่พบบ่อยที่สุดคือการจำลองแบบสแนปชอต เมื่อมีข้อมูลจำนวนมากหรือหากผู้ใช้บริการอยู่ไกล ก็จะส่งข้อมูลทั้งชุดไปให้พวกเขา เป็นรูปแบบขั้นสูงของการจำลองแบบมากกว่าการจำลองแบบของทรานแซกชัน ในบางกรณี จะส่งการแก้ไขข้อมูลไปยังสมาชิกหรือข้อมูลเท่านั้น ซึ่งอาจเป็นประโยชน์ในไฟล์ขนาดเล็กหรือในเครื่อง นี่เป็นเทคนิคการจำลองแบบที่ซับซ้อนมากขึ้น รายการสามารถแก้ไขได้ทั้งผู้เผยแพร่และผู้สมัครสมาชิก ซึ่งจะมีประโยชน์ในสถานการณ์ที่ข้อมูลมีขนาดใหญ่หรือผู้เผยแพร่และผู้สมัครสมาชิกอยู่ห่างไกลกัน การจำลองแบบของข้อมูลที่ต่างกันจึงเป็นไปได้ที่จะเข้าถึงผลิตภัณฑ์ฐานข้อมูลที่หลากหลาย สิ่งนี้มีประโยชน์อย่างยิ่งสำหรับข้อมูลที่มีขนาดใหญ่และมีเครื่องหลายประเภท เช่น ผู้เผยแพร่และผู้สมัครสมาชิก
การจำลองแบบใน Mongodb หมายความว่าอย่างไร
การจำลองแบบ MongoDB เป็นวิธีจำลองชุดข้อมูลของเซิร์ฟเวอร์ MongoDB หลายเครื่อง คุณสามารถทำได้โดยใช้ชุดจำลอง ชุดจำลองคือชุดของอินสแตนซ์ MongoDB ที่ให้บริการชุด ข้อมูล MongoDB เดียวกันและเชื่อมโยงกับกระบวนการเดียวกัน
เมื่อสร้าง Replica Set โหนดหลักจะถูกเลือกโดยอัตโนมัติ เมื่อพร้อมใช้งาน โหนดรองจะเป็นโหนดหลัก โดยมีการกำหนดชุดเรพพลิกาสูงสุด ชุดการจำลองแบบ MongoDB ระบุบทบาทของโหนดหลักและโหนดรอง และถ้าทั้งสองโหนดพร้อมใช้งาน MongoDB จะกำหนดค่าโหนดหลักโดยอัตโนมัติ เป็นชุดของอินสแตนซ์ MongoDB ที่เหมือนกันในแง่ของชุดข้อมูลและกระบวนการ ผู้ดูแลระบบฐานข้อมูลสามารถเสนอความซ้ำซ้อนของข้อมูลได้โดยการจำลองข้อมูล ข้อมูลมีอยู่ทั่วไป ชุดแบบจำลองคือชุดของโหนด MongoDB ที่จัดเป็นกลุ่มสำหรับการจำลองแบบ ชุดการจำลองต้องมีโหนด MongoDB อย่างน้อยสามโหนด: หนึ่งในสามโหนดถือเป็นโหนดหลักที่รับผิดชอบในการรับการดำเนินการเขียนทั้งหมด เมื่อสร้าง Replica Set ชุดแรก โหนดหลักจะถูกเลือกโดยอัตโนมัติ