
Pig: แพลตฟอร์มระดับสูงสำหรับ Apache Hadoop
เผยแพร่แล้ว: 2023-02-22Pig เป็นแพลตฟอร์มระดับสูงสำหรับสร้างโปรแกรมที่ทำงานบน Apache Hadoop คำว่า “Pig” หมายถึงชั้นโครงสร้างพื้นฐานของแพลตฟอร์ม ซึ่งประกอบด้วยคอมไพเลอร์และสภาพแวดล้อมการดำเนินการ ตลอดจนชุดของผู้ปฏิบัติงานระดับสูง เลเยอร์โครงสร้างพื้นฐานของ Pig มีชุดเครื่องมือสำหรับนักพัฒนาในการสร้าง บำรุงรักษา และดำเนินการโปรแกรม Pig ของตน Pig เป็นโครงการโอเพ่นซอร์สที่เป็นส่วนหนึ่งของ ระบบนิเวศ Apache Hadoop โมเดลการเขียนโปรแกรมของ Pig ขึ้นอยู่กับการไหลของข้อมูล ซึ่งทำให้ง่ายต่อการเขียนโปรแกรมที่ประมวลผลข้อมูลจำนวนมาก โปรแกรม Pig ประกอบด้วยชุดตัวดำเนินการที่ดำเนินการในกราฟวงกลมกำกับ Pig เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการประมวลผลข้อมูลจำนวนมาก เนื่องจากปรับขนาดได้ มีประสิทธิภาพ และใช้งานง่าย
ในฐานะโซลูชัน NoSQL คุณต้องใช้วิธีเฉพาะที่กำหนดไว้ล่วงหน้าในการวิเคราะห์และเข้าถึงข้อมูล SQL (UNION, INTERSECT ฯลฯ) เป็นนิพจน์คิวรีทั่วไปที่ไม่ได้ใช้บ่อยนักในโลกของข้อมูลขนาดใหญ่ เนื่องจาก Hive ได้รับการปรับให้เหมาะสมสำหรับการประมวลผลเป็นชุดและบิ๊กดาต้า จึงควรสัมผัสทุกแถว Hive ใช้เวลาและเงินในการดำเนินงานน้อยกว่า Hadoop ซึ่งมีข้อได้เปรียบในด้านขนาด แม้แต่ข้อความค้นหาเล็กๆ บนระบบ dev ก็อาจมีลำดับความสำคัญช้ากว่าข้อความค้นหาที่คล้ายกันบน RDBMS Hive ไม่แคชผลลัพธ์การค้นหา การส่งแบบสอบถามซ้ำเป็นเรื่องปกติใน MapReduce
ไฮฟ์มีสองประเภท: 1) ไฮฟ์ไม่ใช่ฐานข้อมูล แต่เป็นเอ็นจิ้นการสืบค้นที่สนับสนุนส่วน SQL เฉพาะสำหรับข้อมูลการสืบค้น b) Hive เป็นฐานข้อมูลที่สนับสนุน SQL c) Hive เป็นฐานข้อมูลเฉพาะ SQL Hive เป็นระบบคลังข้อมูลที่ใช้ SQL สำหรับ Hadoop ซึ่งรวมถึง Pig และ Python เหนือสิ่งอื่นใด Hive ใช้สำหรับเก็บ ข้อมูล Hadoop
หมูเป็น sql หรือไม่?
ไม่มีคำตอบที่ถูกหรือผิดสำหรับคำถามนี้ เนื่องจากขึ้นอยู่กับความคิดเห็นส่วนบุคคล บางคนอาจเชื่อว่าหมูเป็น sql ในขณะที่คนอื่นอาจไม่ สุดท้ายก็ขึ้นอยู่กับแต่ละคนที่จะตัดสินใจว่าหมูจะเป็น sql หรือไม่
ปัจจุบัน Apache Hive และ Pig เป็นคำศัพท์สองคำที่มีความหมายเหมือนกันกับข้อมูลขนาดใหญ่อย่างรวดเร็ว ด้วยเครื่องมือเหล่านี้ นักพัฒนาข้อมูลและนักวิเคราะห์สามารถใช้เครื่องมือเหล่านี้เพื่อลดความซับซ้อนของ MapReduce ในขณะที่ยังคงรักษาความสมบูรณ์ของข้อมูลในระดับสูง Hive เป็นโครงสร้างพื้นฐานของคลังข้อมูลที่เรียกอีกอย่างว่าเครื่องมือ ETL (การแยก การโหลด และการแปลง) Apache Hive, Pig และ SQL เป็นสามเครื่องมือยอดนิยมสำหรับการวิเคราะห์และจัดการข้อมูล คุณต้องตระหนักว่าแพลตฟอร์มใดจะเหมาะกับความต้องการของคุณมากที่สุด และคุณควรใช้แพลตฟอร์มนั้นบ่อยเพียงใด มาดูสามวิธีในการใช้ Hive, Pig และ SQL ในบริบทของเทคโนโลยีทั้งสามนี้ SQL ยังคงเป็นราชาแห่งการจัดการข้อมูลขนาดใหญ่และการวิเคราะห์ แม้ว่า Apache Hive และ Apache Pig จะมีความโดดเด่น เนื่องจากแต่ละคนทำหน้าที่เฉพาะ ความต้องการจึงได้รับการปรับให้เหมาะกับธุรกิจ Apache Pig ใช้สคริปต์และต้องการความรู้พิเศษ ในขณะที่ Apache Hive เป็นโซลูชันฐานข้อมูลเดียวที่เป็นของนักพัฒนา
หมูเป็นสัตว์อเนกประสงค์ที่มีความยืดหยุ่นสูง ตัวอย่างเช่น Pig สามารถประมวลผลล็อกไฟล์ที่มีข้อมูล JSON หรือ XML ทำให้คุณสามารถอ่านข้อมูลได้ นอกจากนี้ยังสามารถเก็บข้อมูลจากบริการเว็บใน Pig
ชนิดข้อมูลแผนที่ ทูเพิล และชนิดข้อมูลกระเป๋าสามารถใช้แทนกันได้ พวกเขาสามารถจัดการข้อมูลจากแหล่งใด ๆ

Pig An Etl Tool คืออะไร?
ไม่มีคำตอบที่ชัดเจนสำหรับคำถามนี้ เนื่องจากขึ้นอยู่กับว่าคุณกำหนดเครื่องมือ ETL อย่างไร โดยทั่วไปแล้ว เครื่องมือ ETL คือแอปพลิเคชันซอฟต์แวร์ที่ช่วยให้คุณดึงข้อมูลจากแหล่งข้อมูลตั้งแต่หนึ่งแหล่งขึ้นไป แปลงเป็นรูปแบบที่เข้ากันได้กับระบบเป้าหมายของคุณ และโหลดลงในระบบนั้น บางคนจะบอกว่า pig เป็นเครื่องมือ ETL เพราะมันสามารถทำหน้าที่เหล่านี้ได้ทั้งหมด คนอื่นอาจโต้แย้งว่า pig ไม่ใช่เครื่องมือ ETL เนื่องจากไม่ได้ออกแบบมาโดยเฉพาะสำหรับการแปลงข้อมูล ท้ายที่สุดแล้ว คำตอบสำหรับคำถามนี้ขึ้นอยู่กับคำจำกัดความของเครื่องมือ ETL ของคุณเอง
คุณจะใช้หมูสำหรับการประมวลผล Etl ได้อย่างไร
แอปพลิเคชัน Pig สามารถอธิบายได้ว่าเป็นรูปแบบธุรกรรม ETL ซึ่งอธิบายถึงวิธีที่กระบวนการดึงข้อมูลจากวัตถุและแปลงเป็น datastore ตามชุดกฎ ผู้ใช้กำหนด User Defined Functions (UDF) ของ Pig เพื่อนำเข้าข้อมูลจากไฟล์ สตรีม และแหล่งข้อมูลอื่นๆ
เครื่องมือหมูคืออะไร?
แพลตฟอร์มหรือเครื่องมือที่เรียกว่า Pig ประมวลผลชุดข้อมูลขนาดใหญ่ ไลบรารีนี้มีนามธรรมระดับสูงสำหรับการประมวลผลข้อมูลในกระบวนการ MapReduce Pig Latin เป็นภาษาสคริปต์ระดับสูงที่ใช้ในกระบวนการเข้ารหัสเพื่อพัฒนาโค้ดการวิเคราะห์ข้อมูล
ความแตกต่างระหว่างหมูกับ sql คืออะไร?
SQL Pig Latin และ Apache Pig เป็นภาษาขั้นตอน SQL เป็นภาษาสคริปต์ที่มีลักษณะการประกาศ ขึ้นอยู่กับ Apache Pig ทั้งหมดว่าจะใช้สคีมาหรือไม่ สามารถจัดเก็บข้อมูลได้โดยไม่ต้องใช้สคีมา (ประเภทค่าจะถูกจัดเก็บใน $, $ และอื่นๆ)
หมูเป็นส่วนหนึ่งของ Hadoop หรือไม่
แอปพลิเคชัน Pig Hadoop เป็นภาษาโปรแกรมระดับสูงที่สามารถใช้เพื่อวิเคราะห์ชุดข้อมูลขนาดใหญ่ โครงการ Pig Hadoop ของ Yahoo! เป็นหนึ่งใน โครงการ Hadoop แรกๆ โดยทั่วไป จะดำเนินการจัดการข้อมูลจำนวนมากเมื่อเรียกใช้ Hadoop
ในด้านการวิเคราะห์ข้อมูลขนาดใหญ่ Pig Hadoop เป็นภาษาโปรแกรมระดับสูง ในการวิเคราะห์ข้อมูลโดยใช้ Apache Pig ก่อนอื่นเราต้องเขียนสคริปต์โดยใช้ Pig Latin สคริปต์ที่จะแปลงเป็น งาน MapReduce สิ่งนี้ทำได้โดยใช้ Pig Engine ซึ่งเป็นส่วนขยายของ Apache Pig เมื่อทำตามขั้นตอนด้านล่าง คุณจะสามารถติดตั้ง Apache Pig บน Linux/CentOS/Windows (ผ่าน VM หรือ Cloudera) ขั้นตอนแรกคือการดาวน์โหลดและติดตั้ง Apache Pig ขั้นตอนที่สองคือการเปลี่ยนตัวแปรสภาพแวดล้อม Apache Pig โดยใช้ไฟล์ bashrc
ในขั้นตอนที่ 3 กำหนด เวอร์ชัน Pig ไฟล์นี้สามารถบันทึกในไดเร็กทอรีอื่นได้หลังจากย้ายแล้ว ขั้นตอนที่ห้าคือการเรียกใช้ Grunt Shell (สคริปต์ที่ใช้ในการเรียกใช้ Pig Latin) โดยคลิกคำสั่ง Pig
เหตุใด Pig Latin จึงเป็นภาษาสคริปต์ระดับสูงที่ดีที่สุดสำหรับการวิเคราะห์ข้อมูล
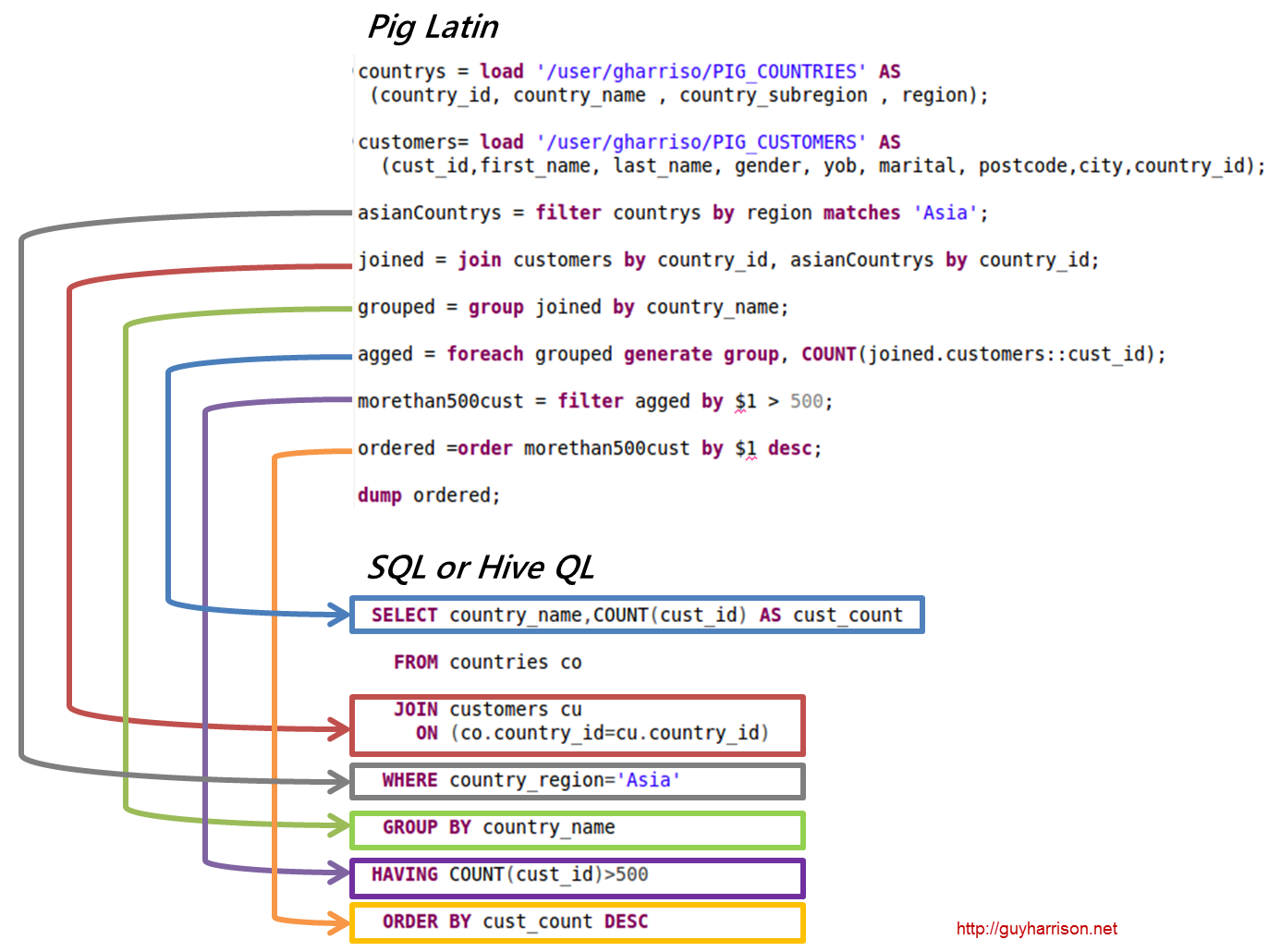
รหัสการวิเคราะห์ข้อมูล Pig Latin เขียนด้วยภาษาสคริปต์ระดับสูง เป็นภาษาที่คล้ายกับ SQL ซึ่งมีจุดประสงค์เพื่อประมวลผลกระแสข้อมูลแบบขนาน
ตัวอย่างอาปาเช่หมู
Pig เป็นแพลตฟอร์มระดับสูงสำหรับสร้างโปรแกรมที่ทำงานบน Apache Hadoop ภาษาสำหรับแพลตฟอร์มนี้เรียกว่า Pig Latin Pig สามารถเรียกใช้งาน Hadoop ใน MapReduce, Tez หรือ Spark Pig Latin สรุปการเขียนโปรแกรมจากสำนวน Java MapReduce ให้เป็นสัญกรณ์ซึ่งทำให้การเขียนโปรแกรม MapReduce ง่ายขึ้น ตัวอย่างเช่น คำสั่ง Pig Latin ต่อไปนี้เทียบเท่ากับโค้ด Java MapReduce ด้านบน: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); การถ่ายโอนข้อมูล A;