
ปัจจัยที่แตกต่างของ Hadoop: ความสามารถในการปรับขนาดแบบโอเพ่นซอร์สและความทนทานต่อความผิดพลาด
เผยแพร่แล้ว: 2022-11-18Hadoop เป็นเฟรมเวิร์กซอฟต์แวร์โอเพ่นซอร์สสำหรับการจัดเก็บข้อมูลแบบกระจายและการประมวลผลชุดข้อมูลขนาดใหญ่ในคลัสเตอร์ของคอมพิวเตอร์ ได้รับการออกแบบมาเพื่อเพิ่มขนาดจากเซิร์ฟเวอร์เครื่องเดียวไปจนถึงเครื่องหลายพันเครื่อง โดยแต่ละเครื่องมีการคำนวณและการจัดเก็บภายในเครื่อง เฟรมเวิร์กนี้ออกแบบมาเพื่อตรวจจับและจัดการกับความล้มเหลวที่ชั้นแอปพลิเคชัน แทนที่จะพึ่งพาฮาร์ดแวร์เพื่อให้มีความพร้อมใช้งานสูง Hadoop เป็นฐานข้อมูล nosql เนื่องจากใช้สถาปัตยกรรมที่แตกต่างอย่างสิ้นเชิงจากฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม Hadoop ได้รับการออกแบบให้ปรับขนาดในแนวนอน ซึ่งหมายความว่าสามารถปรับขนาดเพื่อรองรับข้อมูลได้มากขึ้นโดยการเพิ่มเซิร์ฟเวอร์สินค้าโภคภัณฑ์ในคลัสเตอร์ Hadoop ยังได้รับการออกแบบมาให้ทนต่อข้อผิดพลาด ซึ่งหมายความว่าหากเซิร์ฟเวอร์ในคลัสเตอร์หยุดทำงาน ระบบจะทำงานต่อไปได้โดยไม่มีเซิร์ฟเวอร์นั้น
Hadoop ไม่ได้ใช้สำหรับการจัดเก็บข้อมูล และไม่จำเป็นต้องใช้พื้นที่เก็บข้อมูลเชิงสัมพันธ์ ค่อนข้างใช้เพื่อเก็บข้อมูลจำนวนมหาศาลบนเซิร์ฟเวอร์แบบกระจาย ฐานข้อมูล Hadoop เป็นข้อมูลประเภทหนึ่งแทนที่จะเป็นระบบซอฟต์แวร์ที่เปิดใช้งานการประมวลผลแบบขนานจำนวนมาก เป็นประเภทการเชื่อมโยงของฐานข้อมูล NoSQL (เช่น HBase) ที่ช่วยให้ผู้ใช้สามารถค้นหาและค้นหาฐานข้อมูลในหลากหลายขอบเขต RDBMS ในรูปแบบปัจจุบันจะไม่สามารถแข่งขันกับ Hadoop ได้เนื่องจากสามารถจัดการทั้งข้อมูลที่เกี่ยวข้องและข้อมูลธุรกรรมได้ Hadoop มีความสามารถในการจัดการข้อมูลประเภทใดก็ได้ ไม่ว่าจะเป็นแบบมีโครงสร้าง กึ่งโครงสร้าง หรือไม่มีโครงสร้าง และรองรับวิธีการที่หลากหลาย การวิเคราะห์ข้อมูลขนาดใหญ่ ช่วยให้ธุรกิจมีความได้เปรียบในการแข่งขันในโลกแห่งความเป็นจริงโดยการให้ข้อมูลเชิงลึกที่ลึกขึ้น Hadoop เป็นบริการที่รองรับการใช้การประมวลผลการวิเคราะห์ออนไลน์ (OLAP) ในการประมวลผลข้อมูล สิ่งสำคัญคือต้องจำไว้ว่าความเร็วของการประมวลผลข้อมูลนั้นพิจารณาจากจำนวนคำขอข้อมูล คุณสามารถใช้ Hadoop หากคุณไม่ต้องการให้ธุรกรรม ACID หรือการสนับสนุน OLAP เป็นต้น
Hadoop และฐานข้อมูลในหน่วยความจำเป็นสองเทคโนโลยีที่แตกต่างกันโดยสิ้นเชิงซึ่งทับซ้อนกัน พวกเขาไม่เหมือนกัน แต่พวกเขาเห็นด้วยในบางสิ่ง
แอปพลิเคชันการวิเคราะห์ที่ใช้ SQL บน Hadoop รวมวิธีการสืบค้นแบบ SQL ที่สร้างไว้แล้วเข้ากับ องค์ประกอบกรอบข้อมูล Hadoop ที่ใหม่กว่า SQL-on- Hadoop ช่วยให้นักพัฒนาองค์กรและนักวิเคราะห์ธุรกิจทำงานร่วมกันบนคลัสเตอร์ Hadoop ด้วยคำสั่ง SQL ที่คุ้นเคย
เป็นฐานข้อมูล NoSQL ที่มีวิธีการจัดเก็บและเรียกใช้ข้อมูล ไม่ใช่เชิงสัมพันธ์/ไม่ใช่ SQL เป็นหนึ่งในคำศัพท์ที่ใช้กันทั่วไปในพื้นที่นี้
ข้อมูลได้รับการจัดการในรูปแบบต่างๆ โดย Hadoop และ SQL SQL เป็นภาษาโปรแกรม ในขณะที่ Hadoop เป็นเฟรมเวิร์กของส่วนประกอบในซอฟต์แวร์ เครื่องมือทั้งสองมีประโยชน์สำหรับข้อมูลขนาดใหญ่ แต่มีข้อเสีย แพลตฟอร์ม Hadoop สามารถจัดการชุดข้อมูลที่มีขนาดใหญ่กว่ามาก แต่จะเขียนข้อมูลเพียงครั้งเดียวเท่านั้น
อะไรคือความแตกต่างระหว่าง Hadoop และ Nosql?
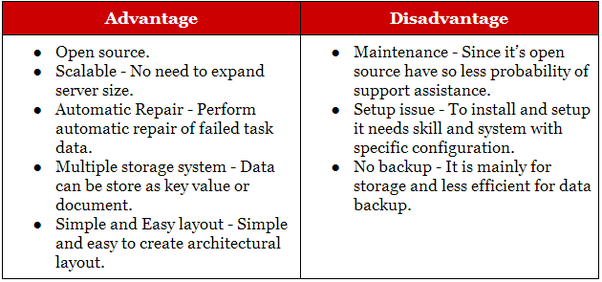
Hadoop เหมาะสำหรับแอปพลิเคชันการวิเคราะห์และการเก็บถาวรเชิงประวัติ ในขณะที่ NoSQL นั้นเหมาะสำหรับปริมาณงานเชิงปฏิบัติที่เสริมส่วนสัมพันธ์กัน ฐานข้อมูล NoSQL เริ่มต้นจากการเป็น ฐานข้อมูลที่เก็บคีย์-ค่า แต่ต่อมา ฐานข้อมูลเอกสาร/json และกราฟก็เข้าร่วมด้วย
การประมวลผลตามเวลาจริง ข้อมูลขนาดใหญ่ และข้อมูลที่ไม่มีโครงสร้างเป็นเพียงไม่กี่สถานการณ์ที่สามารถใช้เทคโนโลยี NoSQL ได้ ด้วยเหตุนี้ จึงสามารถจัดการกับความท้าทายเหล่านี้ เช่น ความสามารถในการปรับขนาดและความพร้อมใช้งานได้ ฐานข้อมูล NoSQL มีข้อดีหลายประการเหนือฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม พวกเขาสามารถประมวลผลชุดข้อมูลได้อย่างรวดเร็วและปรับขนาดได้มากกว่าเดิม ระบบการจัดการฐานข้อมูลยังใช้ความรู้และความเชี่ยวชาญน้อยกว่า ฐานข้อมูลแบบเดิม ซึ่งทำให้ใช้งานได้ง่ายขึ้น ฐานข้อมูล NoSQL มีข้อดีหลายประการเหนือฐานข้อมูลเชิงสัมพันธ์แบบดั้งเดิม สิ่งที่สำคัญที่สุดที่ต้องพิจารณาคือคุณต้องการการประมวลผลตามเวลาจริงและชุดข้อมูลขนาดใหญ่หรือไม่
ฐานข้อมูล Nosql เป็นตัวเลือกที่ดีกว่าสำหรับธุรกิจที่มีเวิร์กโหลดข้อมูลขนาดใหญ่
หากปริมาณงานข้อมูลของคุณมุ่งเน้นไปที่การวิเคราะห์และประมวลผลข้อมูลที่หลากหลายและไม่มีโครงสร้างจำนวนมาก เช่น Big Data ฐานข้อมูล NoSQL เป็นตัวเลือกที่ดีกว่า ตรงกันข้ามกับ ฐานข้อมูลเชิงสัมพันธ์ ฐานข้อมูล NoSQL ไม่อาศัยโมเดลสคีมาคงที่ RDBMS มีความยืดหยุ่นมากกว่า RDBMS แบบดั้งเดิมในแง่ของการจัดเก็บ ประมวลผล และจัดการข้อมูล ทำให้เป็นตัวเลือกที่ดีกว่าสำหรับธุรกิจที่ต้องการความสามารถในการเข้าถึงข้อมูลจำนวนมากอย่างรวดเร็ว และจำเป็นต้องจัดเก็บข้อมูลนั้นอย่างไม่มีกำหนด
Big Data Sql หรือ Nosql คืออะไร?

หากปริมาณงานข้อมูลของคุณเกี่ยวข้องกับการประมวลผลอย่างรวดเร็วและการวิเคราะห์ข้อมูลที่หลากหลายและไม่มีโครงสร้างจำนวนมาก เช่น Big Data อย่างรวดเร็ว NoSQL คือทางเลือกที่ดีที่สุดของคุณ โมเดลฐานข้อมูล NoSQL มีลักษณะเฉพาะตรงที่ไม่อาศัยโครงสร้างสคีมาเดียวกันกับฐานข้อมูลเชิงสัมพันธ์
ไม่มีคำถามอีกต่อไปว่าข้อมูลขนาดใหญ่จะช่วยปรับปรุงการผลิตหรือไม่ มันเป็นเรื่องของเมื่อไหร่ ในข้อมูลขนาดใหญ่มีข้อมูลที่มีโครงสร้างและไม่มีโครงสร้างจำนวนมหาศาล หลากหลาย และซับซ้อน สามารถใช้เซ็นเซอร์ กล้องในพื้นที่การผลิต และอุปกรณ์สำหรับผู้บริโภคเพื่อรวบรวมข้อมูลขนาดใหญ่ในการผลิต เนื่องจากข้อมูลส่วนใหญ่ในการผลิตไม่มีโครงสร้าง สถาปัตยกรรม NoSQL จึงไม่สามารถแข่งขันกับแนวทางที่ตายตัวเช่น SQL ได้ ฐานข้อมูล NoSQL ไม่จำเป็นต้องมี schema เพื่อจัดเก็บข้อมูลในตารางฐานข้อมูลเดียวกัน ทำให้ผู้ใช้สามารถจัดเก็บข้อมูลในโครงสร้างต่างๆ ได้ เส้นแบ่งของบริษัทสามารถกำหนดได้จากจำนวนข้อมูลที่ต้องการใช้ ธุรกรรมต้องเป็นไปตามหลักการพื้นฐานสี่ประการจึงจะถือว่าเป็นธุรกรรมฐานข้อมูลเชิงสัมพันธ์
เนื่องจากระบบ NoSQL และระบบคลาวด์สามารถรวมเข้าด้วยกันได้ จึงเป็นความคิดที่ดีที่จะใช้เฟรมเวิร์กการประมวลผลแบบคลาวด์เพื่อสนับสนุนระบบ NoSQL การเพิ่มประสิทธิภาพกระบวนการผลิตแบบเรียลไทม์ผ่าน NoSQL สามารถทำได้ผ่านการผสานรวมกับ Manufacturing Execution Systems (MES) ความสำเร็จนี้เกิดขึ้นได้จากการใช้การวิเคราะห์ข้อมูลขนาดใหญ่เพื่อสร้างการตอบสนองที่รวดเร็วยิ่งขึ้นต่อสภาวะที่เปลี่ยนแปลง MongoDB เป็นฐานข้อมูล NoSQL ที่ดีเพราะตั้งค่าได้ง่ายและสามารถนำไปใช้ในการวิเคราะห์ได้ การใช้สถาปัตยกรรมฐานข้อมูลที่ตอบสนองเร็วขึ้น เช่น NoSQL ช่วยให้ฝ่ายบริหารดำเนินการจำลองสถานการณ์ได้ดีขึ้น ทำให้พวกเขาตัดสินใจเกี่ยวกับผลิตภัณฑ์ได้ดีขึ้นในโลกแห่งความเป็นจริง ฐานข้อมูล B2B มีความเสี่ยงต่อการโจมตีข้ามไซต์ เช่นเดียวกับการโจมตีแบบฉีดและการโจมตีด้วยกำลังดุร้าย การโจมตีแบบฉีดเกิดขึ้นเมื่อผู้โจมตีเพิ่มข้อมูลไปยังคำสั่งการสืบค้น NoSQL หรือคำสั่งหน่วยเก็บข้อมูล

ภาคการผลิตมีความกังวลเป็นพิเศษเกี่ยวกับความปลอดภัยของสถาปัตยกรรม NoSQL หากมีการส่งมอบการโจมตีแบบปฏิเสธบริการหรือการโจมตีแบบฉีดได้สำเร็จ ผู้ผลิตอาจสามารถปรับเปลี่ยนข้อกำหนดได้ ด้วยเหตุนี้คู่แข่งอาจได้เปรียบในตลาดที่มีการแข่งขันสูง
กระบวนการทางธุรกิจที่อาศัยข้อมูลเรียลไทม์กลายเป็นเรื่องธรรมดามากขึ้น เนื่องจากบริษัทต่าง ๆ แสวงหาวิธีปรับปรุงประสิทธิภาพและตอบสนองต่อความต้องการของลูกค้า ฐานข้อมูล NoSQL บนระบบคลาวด์ เช่น Cloud Bigtable มอบวิธีที่รวดเร็วและมีประสิทธิภาพในการจัดเก็บและเข้าถึงชุดข้อมูลขนาดใหญ่ ทำให้เป็นโซลูชันที่ยอดเยี่ยมสำหรับแอปพลิเคชันประเภทนี้
Cloud Bigtable เป็นบริการฐานข้อมูล NoSQL ที่ได้รับการจัดการเต็มรูปแบบและให้เวลาทำงาน 99.999% เหมาะอย่างยิ่งสำหรับปริมาณงานด้านการวิเคราะห์และการปฏิบัติงาน เนื่องจากมีความเร็วในการป้อนข้อมูลสูง และปรับขนาดขึ้นและลงได้ง่าย ด้วยเหตุนี้ จึงเป็นตัวเลือกที่ยอดเยี่ยมสำหรับการประมวลผลข้อมูลแบบเรียลไทม์ในแอปพลิเคชันต่างๆ เช่น เกมมือถือและการวิเคราะห์การค้าปลีก
Nosql เป็นฐานข้อมูลที่ดีที่สุดสำหรับข้อมูลขนาดใหญ่หรือไม่?
ตัวอย่างเช่น MongoDB เป็นตัวเลือกที่ยอดเยี่ยมสำหรับการจัดเก็บข้อมูลจำนวนมาก พวกเขาเปิดใช้งานสถานการณ์การประมวลผลที่คล่องตัวและมีประสิทธิภาพสูงที่หลากหลาย นอกจากนี้ ข้อมูลที่ไม่มีโครงสร้างจะถูกจัดเก็บไว้ในฐานข้อมูล NoSQL บนโหนดการประมวลผลหลายโหนดและบนเซิร์ฟเวอร์หลายเครื่อง ด้วยเหตุนี้ ฐานข้อมูล NoSQL จึงเป็นตัวเลือกเริ่มต้นของ คลังข้อมูลที่ใหญ่ที่สุด ในโลกบางแห่ง ฐานข้อมูลใดดีที่สุดสำหรับข้อมูลขนาดใหญ่ เมื่อพูดถึงคำถามนี้ เป็นไปไม่ได้ที่จะคาดเดาว่าฐานข้อมูลใดดีที่สุดสำหรับข้อมูลขนาดใหญ่ เนื่องจากความต้องการที่แตกต่างกันขององค์กร Amazon Redshift, Azure Synapse Analytics, Microsoft SQL Server, Oracle Database, MySQL, IBM DB2 และฐานข้อมูลอื่นๆ เป็นตัวเลือกยอดนิยมสำหรับการจัดเก็บข้อมูลขนาดใหญ่
Hadoop เป็นฐานข้อมูล
Hadoop เป็นระบบไฟล์แบบกระจายและเฟรมเวิร์กสำหรับการเรียกใช้แอปพลิเคชันบนคลัสเตอร์ขนาดใหญ่ของฮาร์ดแวร์สินค้า Hadoop ไม่ใช่ฐานข้อมูล
Hadoop ซึ่งเป็นเฟรมเวิร์กแบบโอเพ่นซอร์สช่วยให้สามารถจัดเก็บและประมวลผลชุดข้อมูลขนาดใหญ่ได้อย่างมีประสิทธิภาพ สามารถสร้างตาราง Hive และ Imperative ได้โดยใช้ไฟล์ข้อความใน HDFS รองรับรูปแบบไฟล์หลักสามรูปแบบ ได้แก่ ไฟล์ลำดับ ไฟล์ข้อมูล Avro และไฟล์ Parquet ชุดของไบต์แสดงโดยการทำให้เป็นอนุกรมข้อมูลเป็นหน่วยหน่วยความจำ Avro กรอบการจัดลำดับข้อมูลที่มีประสิทธิภาพได้รับการสนับสนุนอย่างกว้างขวางจาก Hadoop และระบบนิเวศของมัน
การใช้ไฟล์ข้อความเป็นรูปแบบการจัดเก็บสำหรับตาราง Hive และ Implicit ทำให้การจัดการและจัดการข้อมูลง่ายขึ้น ด้วยเหตุนี้จึงเป็นทางเลือกที่ดีสำหรับการประมวลผลเป็นชุดหรือการจัดเก็บข้อมูลในรูปแบบต่างๆ นอกจากนี้ การทำให้เป็นอนุกรมข้อมูลผ่าน Avro ช่วยให้สามารถจัดเก็บและดึงข้อมูลที่มีประสิทธิภาพและสะดวก ด้วยเหตุนี้จึงเป็นตัวเลือกที่ดีสำหรับการจัดเก็บข้อมูลในรูปแบบต่างๆ หรือดำเนินการประมวลผลแบบขนาน
Hadoop กับ Nosql
Hadoop จัดการข้อมูลขนาดใหญ่สำหรับคลัสเตอร์ของฮาร์ดแวร์สินค้าโภคภัณฑ์ หากฟังก์ชันการทำงานไม่ตรงตามความต้องการของคุณหรือใช้งานไม่ได้ คุณสามารถแก้ไขได้ สิ่งนี้เรียกว่า NoSQL และเป็น ระบบจัดการฐานข้อมูล ประเภทหนึ่งที่เก็บข้อมูลที่มีโครงสร้าง กึ่งโครงสร้าง และไม่มีโครงสร้าง
MongoDB เป็นฐานข้อมูล NoSQL (ไม่ใช่ SQL เท่านั้น) ถูกสร้างขึ้นในปี 2550 อันเป็นผลมาจากการพัฒนา C ++ Hadoop คือชุดของโปรแกรมซอฟต์แวร์โอเพ่นซอร์สที่เขียนด้วยภาษาจาวาเป็นหลักสำหรับการประมวลผลข้อมูลขนาดใหญ่ แพลตฟอร์มนี้ยังประกอบด้วยการค้นหาข้อความแบบเต็ม เครื่องมือวิเคราะห์ขั้นสูง และภาษาที่ใช้สืบค้นที่ใช้งานง่าย แม้ว่า Hadoop จะเป็นที่รู้จักดีที่สุดในด้านความสามารถในการจัดเก็บและประมวลผลข้อมูลจำนวนมาก แต่ก็ทำเช่นนั้นเป็นชุดเล็กๆ MongoDB มีเครื่องมือประมวลผลข้อมูลแบบเรียลไทม์ที่หลากหลาย ตัวเชื่อมต่อของ MongoDB สำหรับเครื่องมือภายนอก เช่น Kafka และ Spark ช่วยให้การนำเข้าและประมวลผลข้อมูลเป็นเรื่องง่าย เมื่อพูดถึงการจัดการข้อมูล Hadoop และ MongoDB มอบข้อได้เปรียบที่หลากหลายเหนือฐานข้อมูลแบบเดิม Hadoop เป็นเครื่องมือที่ยอดเยี่ยมสำหรับการจัดการกับโครงสร้างข้อมูลขนาดใหญ่เนื่องจากระบบไฟล์แบบกระจาย MongoDB เป็นฐานข้อมูลเดียวที่สามารถใช้แทนฐานข้อมูลแบบเดิมได้
เป็นฐานข้อมูล Spark A Nosql
ในเอกสารระบุว่า NoSQL DataFrame เป็น Spark DataFrame ตามรูปแบบ Spark สำหรับการจัดเก็บข้อมูล ตรงกันข้ามกับแหล่งข้อมูลก่อนหน้านี้ แหล่งข้อมูลนี้รองรับการตัดข้อมูลและการกรอง (การเลื่อนลงของเพรดิเคต) ทำให้การสืบค้น Spark สามารถสืบค้นข้อมูลน้อยลงและโหลดเฉพาะข้อมูลที่จำเป็นตามความจำเป็น
สิ่งสำคัญคือต้องรักษาการรับรู้ทางยุทธวิธีเมื่อใช้ฐานข้อมูล Apache Spark และ NoSQL ( Apache Cassandra และ MongoDB) ร่วมกันในแอปพลิเคชัน บล็อกนี้มุ่งเน้นไปที่วิธีใช้ Apache Spark ในแอปพลิเคชัน NoSQL CassandraLand และ MongoLand ที่ TCP/IP sPark เป็นเครื่องเล่นสองแห่งที่ได้รับความนิยมมากที่สุด และเป็นสถานที่ยอดเยี่ยมหากคุณชอบสวนสนุก ขณะค้นหาข้อมูลของกระทรวงพลังงาน แอปพลิเคชัน Spark ของเราเริ่มหมุนวงล้อ ต่อไปนี้เป็นบทเรียนสั้น ๆ ว่าลำดับคีย์ของ Cassandra มีความสำคัญเพียงใดในการสืบค้น นอกจากนี้ยังมีรถไฟเหาะ Partitioner ที่ CassandraLand ลูกค้าที่ชื่นชอบรถไฟเหาะสามารถแบ่งปันข้อมูลของตนกับผู้ควบคุมเครื่องเล่น เพื่อให้ติดตามได้ว่าใครเคยขี่บ้างในแต่ละวัน
บทเรียนแรกใน MongoDB บทที่ 1 คือการจัดการการเชื่อมต่อ MongoDB อย่างเหมาะสม เมื่อคุณต้องการอัพเดทข้อมูลเกี่ยวกับสถานะสมาชิกใหม่ของกรมพลังงาน ดัชนี Mongo มีประโยชน์อย่างมาก ในฐานะลูกค้า MongoDB หรือ Spark คุณควรรักษาการเชื่อมต่อและดัชนีที่เหมาะสมไว้ในกรณีที่มีการอัปเดตระบบ