
รูปแบบข้อมูล HDF5: ตัวเลือกที่น่าสนใจสำหรับการจัดเก็บและจัดการชุดข้อมูลขนาดใหญ่
เผยแพร่แล้ว: 2023-02-13HDF5 เป็นรูปแบบข้อมูลที่ออกแบบมาเพื่อจัดเก็บและจัดการคอลเล็กชันข้อมูลขนาดใหญ่และซับซ้อน มักใช้ในงานด้านวิทยาศาสตร์และวิศวกรรม และความนิยมเพิ่มขึ้นในช่วงไม่กี่ปีที่ผ่านมา HDF5 ไม่ใช่ฐานข้อมูล แต่สามารถใช้เพื่อจัดเก็บข้อมูลใน รูปแบบลำดับชั้น ที่คล้ายกับระบบไฟล์ สิ่งนี้ทำให้ HDF5 เป็นตัวเลือกที่น่าสนใจสำหรับแอปพลิเคชันที่ต้องจัดเก็บและจัดการข้อมูลจำนวนมาก
คุณสามารถดึงข้อมูลเมตาและ ข้อมูลดิบ จากไฟล์ HDF5 และ netCDF4 และใช้การสตรีม Hadoop เพื่อวิเคราะห์ข้อมูล Hadoop โดยใช้ Hadoop Distributed File System (HDFS) HDF5 Connector Virtual File Driver (VFD)
Hdf5 เป็นฐานข้อมูลหรือไม่
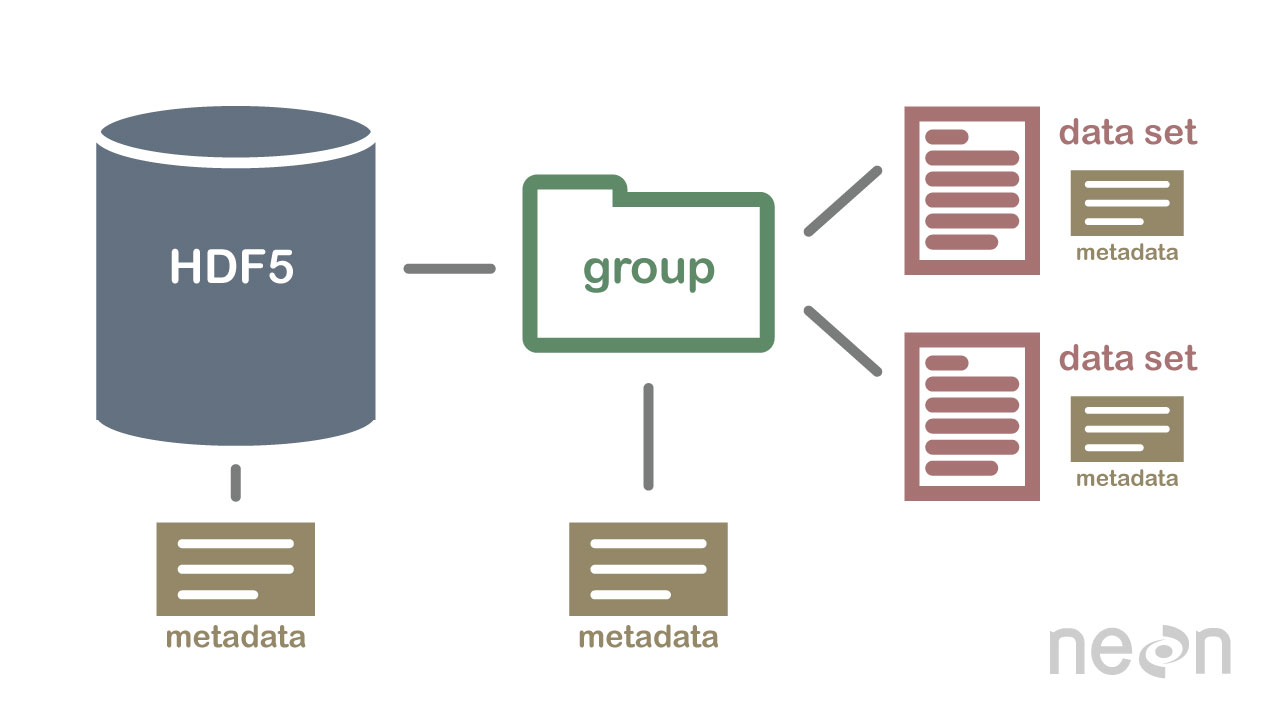
HDF5 ไม่ใช่ฐานข้อมูล แต่สามารถใช้เพื่อจัดเก็บข้อมูลในโครงสร้างแบบลำดับชั้น คล้ายกับระบบไฟล์ สามารถใช้ HDF5 เพื่อจัดเก็บข้อมูลในรูปแบบต่างๆ รวมถึงข้อความ รูปภาพ และ ข้อมูลไบนารี
ข้อมูลในรูปแบบลำดับชั้น (HDF5) มีประโยชน์อย่างมากในการวิจัยทางวิทยาศาสตร์ ระบบไฟล์ HDF5 เนื่องจากมีความคล้ายคลึงกับระบบไฟล์ในลักษณะที่มีประสิทธิภาพมาก จึงเป็นรูปแบบที่ยอดเยี่ยม เมื่อพูดถึงข้อมูลที่เข้ารหัสในรูปแบบนี้ อาจเข้าถึงได้ยาก คู่มือนี้จะแนะนำคุณว่า Apache Drill สามารถช่วยให้คุณเข้าถึงและสืบค้นชุดข้อมูล HDf5 ได้อย่างไร Drill สามารถเข้าถึงไฟล์ HDF5 แต่ละไฟล์ผ่านตัวเลือก defaultPath สิ่งนี้ทำได้โดยเรียกใช้ฟังก์ชัน table() โดยตรงระหว่างเวลาสืบค้นหรือผ่านการกำหนดค่า ผลลัพธ์ของแบบสอบถามนี้อยู่ในตารางด้านล่าง จากนั้นดริลล์สามารถเลือกคอลัมน์และกรองทีละคอลัมน์ กรอง รวม หรือรวมกับข้อมูลอื่นที่สามารถสืบค้นได้
ข้อกำหนด HDF5 กำหนดรูปแบบไฟล์เพื่อจัดเก็บอาร์เรย์ข้อมูล อาร์เรย์ข้อมูลสามารถประกอบด้วยข้อมูลประเภทใดก็ได้ รวมถึงข้อมูลสตริง ข้อมูลลอย ข้อมูลเชิงซ้อน และข้อมูลจำนวนเต็ม อาร์เรย์สามารถบรรจุข้อมูลจากขนาดใดก็ได้ และสามารถมีรูปร่างใดก็ได้ ใน HDF5 ก่อนอื่นต้องสร้างไฟล์ส่วนหัวเพื่อสร้างชุดข้อมูล ไฟล์ส่วนหัวมีข้อมูลเกี่ยวกับชุดข้อมูลและข้อมูลเมตา ไฟล์ส่วนหัวมีข้อมูลสำคัญสองส่วน ได้แก่ ชื่อของชุดข้อมูลและหมายเลขรุ่นของชุดข้อมูล อาร์เรย์ข้อมูลใช้เพื่อเก็บข้อมูลของชุดข้อมูล บล็อกประกอบด้วยข้อมูลในอาร์เรย์ข้อมูล ในอาร์เรย์ข้อมูล แต่ละบล็อกของข้อมูลประกอบด้วยชุดข้อมูลที่ต่อเนื่องกัน จำนวนบล็อกของชุดข้อมูลถูกกำหนดโดยจำนวนไบต์ในชุดนั้น สามารถเข้าถึงข้อมูลได้หลายวิธีตามข้อกำหนด HDF5 วิธีการจัดทำดัชนีมักใช้เพื่อรับข้อมูลในชุดข้อมูล เมื่อใช้วิธีการเหล่านี้ คุณจะสามารถเข้าถึงข้อมูลได้โดยการป้อนชื่อบล็อกในอาร์เรย์ข้อมูลที่คุณต้องการเข้าถึง สามารถใช้เมธอดโครงสร้างเพื่อเข้าถึงข้อมูลในชุดข้อมูลได้ เมื่อคุณใช้วิธีการเหล่านี้ คุณจะสามารถเข้าถึงข้อมูลได้โดยใช้โครงสร้างของอาร์เรย์ข้อมูล ในตัวอย่างต่อไปนี้ คุณสามารถเข้าถึงข้อมูลในอาร์เรย์ข้อมูลได้โดยใช้ค่าออฟเซ็ตและค่าความยาวของเมธอดโครงสร้าง อีกวิธีในการรับข้อมูลจากชุดข้อมูลคือการใช้วิธีฟังก์ชัน คุณสามารถรับข้อมูลได้โดยใช้วิธีใดวิธีหนึ่งโดยเลือกฟังก์ชันในไฟล์ส่วนหัวสำหรับข้อมูล วิธีการเข้าถึงอาร์เรย์ข้อมูลสามารถใช้ได้โดยการกำหนดค่าในไฟล์ส่วนหัวเป็นองค์ประกอบอาร์เรย์ข้อมูลของอาร์เรย์ สุดท้าย คุณสามารถเข้าถึงข้อมูลในชุดข้อมูลโดยใช้วิธีการเข้าถึง เมื่อใช้วิธีการเหล่านี้ คุณจะสามารถเข้าถึงข้อมูลได้โดยใช้สิทธิ์การเข้าถึงที่กำหนดในไฟล์ส่วนหัว กล่าวอีกนัยหนึ่ง การใช้สิทธิ์การอ่านสามารถเข้าถึงข้อมูลในอาร์เรย์ข้อมูลด้วยวิธีการเข้าถึง สามารถสร้างและใช้ข้อมูลได้หลากหลายวิธีโดยใช้ข้อมูลจำเพาะ HDF5 วิธีการสร้างเป็นวิธีการทั่วไปในการสร้างชุดข้อมูล เมื่อใช้วิธีการสร้าง คุณสามารถสร้างชุดข้อมูลได้โดยการป้อนชื่อชุดข้อมูลและหมายเลขรุ่นของชุดข้อมูล นอกจากข้อกำหนด HDF5 แล้ว การใช้ชุดข้อมูลสามารถทำได้หลายวิธี วิธีที่ใช้บ่อยที่สุด

Hdf5 เป็นฐานข้อมูลเชิงสัมพันธ์หรือไม่
HDF5 ไม่ใช่ฐานข้อมูลเชิงสัมพันธ์
Graphql Nosql หรือ Sql คืออะไร
เป้าหมายหลักของ GraphQL คือการใช้ระบบประเภทเพื่อส่งคืนข้อมูลได้เร็วขึ้นและมีประสิทธิภาพมากขึ้น SQL (ภาษาคิวรีที่มีโครงสร้าง) เป็นภาษาที่เก่ากว่าและใช้กันอย่างแพร่หลายในการจัดเก็บข้อมูลใน ระบบฐานข้อมูลแบบตารางหรือเชิงสัมพันธ์ หากคุณต้องการสร้าง API บนฐานข้อมูล NoSQL คุณควรทำงานร่วมกับ GraphQL
Type Mismatch คือฐานข้อมูล GraphQL และ NoSQL ที่สร้างโดย Herman Camarena และ Roger Cochrane การใช้ GraphQL อาจส่งผลให้มีการแนะนำระบบประเภทแทนที่จะเป็นระบบ NoSQL ซึ่งช่วยลดความยืดหยุ่นที่เกิดจากระบบ NoSQL คอลเลกชัน GraphQL ประกอบด้วยเอกสารที่หลากหลายซึ่งมีโครงสร้างที่สอดคล้องกันและมีข้อยกเว้นบางประการ เนื่องจาก GraphQL มีชุด ประเภทข้อมูล ในตัวที่ตรงกับประเภทของแบ็กเอนด์ นักพัฒนาจึงสามารถเลือกประเภทข้อมูลที่จะสร้างได้ GraphQL ควรแก้ไขปัญหาประเภทที่ไม่ตรงกันเพื่อให้ตระหนักถึงศักยภาพอย่างเต็มที่ ในแง่ของคุณสมบัติ มอบโซลูชันที่ไม่ตรงกันในระดับล่างเนื่องจากมีข้อดีมากมาย งานเป็นแบบอัตโนมัติมากขึ้นด้วยเครื่องมือเช่น JSON2SDL ของ StepZen
เป็นเครื่องมืออันทรงพลังที่สามารถใช้เพื่อสร้างแอปพลิเคชันที่ยืดหยุ่นและมีประสิทธิภาพมากขึ้น แต่ SQL ไม่ใช่สิ่งทดแทน ในแง่ของการบำรุงรักษา อาจมีผลกระทบในทางลบเนื่องจากทำให้งานบางอย่างยากขึ้น
Graphql: ภาษาคิวรีสำหรับฐานข้อมูลใดๆ
ภาษาคิวรี GraphQL ช่วยให้ไคลเอนต์และเซิร์ฟเวอร์สื่อสารกันได้ อินสแตนซ์ GraphQL สามารถดึงและคงการเปลี่ยนแปลงจากแหล่งข้อมูลหรือสถานะถาวร ตัวแก้ไขคือชุดของฟังก์ชันตามอำเภอใจที่ใช้ในการเข้าถึงและจัดการข้อมูล API มีอยู่ในฐานข้อมูลที่หลากหลาย และ GraphQL สามารถใช้กับฐานข้อมูลใดก็ได้ ฐานข้อมูล MongoDB เป็น ฐานข้อมูลแหล่งข้อมูลยอดนิยม ที่ไม่เชื่อเรื่องพระเจ้ากับข้อมูลประเภทต่างๆ
Nosql ใช้ B Trees หรือไม่
ฐานข้อมูล NOSQL ไม่ใช้ B tree เนื่องจากไม่ได้ขึ้นอยู่กับโมเดลเชิงสัมพันธ์ ฐานข้อมูล NOSQL มักจะใช้คู่คีย์-ค่า ที่เก็บเอกสาร หรือฐานข้อมูลกราฟ
B-tree เป็นโครงสร้างการสร้างดัชนีเริ่มต้นใน MongoDB ใน การจัดเก็บข้อมูล B-tree เป็นวิธีที่มีประสิทธิภาพมากกว่า สามารถจัดระเบียบข้อมูลโดยใช้จำนวนเต็มและสตริงได้หากใช้ร่วมกัน ดังนั้น ฐานข้อมูลที่มีปริมาณข้อมูลสูงจึงควรพิจารณาใช้ เนื่องจาก B tree สามารถใช้พื้นที่ได้มาก จึงเป็นโมเดลที่มีประสิทธิภาพ สิ่งนี้มีประโยชน์สำหรับฐานข้อมูลที่ต้องการเก็บข้อมูลจำนวนมาก B-tree ยังเป็นทางเลือกที่ดีสำหรับฐานข้อมูลที่ต้องการจัดระเบียบข้อมูลด้วยวิธีเฉพาะ
ฐานข้อมูลใดใช้ B-tree
มีมานานแล้วและสามารถใช้กับฐานข้อมูลได้หลากหลาย ฐานข้อมูล NoSQL สามารถสร้างบนเอ็นจิ้น B-tree นอกเหนือจากเอ็นจิ้น B-tree ตัวอย่างเช่น MongoDB ทำดัชนีข้อมูลใน B-tree อัลกอริทึมจะเหมือนกันสำหรับ DBMS เช่นเดียวกับฐานข้อมูลเชิงสัมพันธ์ แม้ว่าจะมีข้อยกเว้นอยู่บ้าง สามารถใช้สตริงและจำนวนเต็มเพื่อจัดระเบียบข้อมูลใน B-tree
ฐานข้อมูลใดใช้ B-tree Mysql ในบทความต่อไปนี้ใช้ทั้ง Btree และ B+tree SQL Server จัดเก็บดัชนีตามข้อมูลที่คงอยู่ตามคีย์ในรูปแบบของ BTree ส่งผลให้แต่ละโหนดในแผนผังดังกล่าวปรากฏเป็นหน้าเดียว