
NoSQL Veritabanları ile Yatay Ölçeklenebilirlik
Yayınlanan: 2022-11-20NoSQL veritabanları yatay ölçeklenebilirdir, yani tek bir düğüme daha fazla kaynak eklemeyi ifade eden dikey ölçeklendirmenin aksine, bir sisteme daha fazla düğüm ekleyerek ölçeklenebilecekleri anlamına gelir. Bu, bir NoSQL veritabanının parçalanabileceği veya birden çok parçaya bölünebileceği ve her parçanın ayrı bir sunucuda depolanabileceği anlamına gelir. Bu, veritabanının dikey ölçeklendirmeden çok daha verimli ve ölçeklenebilir olan yatay ölçeklendirmesine izin verir.
Ölçeklendirme, SQL ve NoSQL veritabanları için kritik öneme sahiptir ve veritabanı parçalama kavramı bunun önemli bir parçasıdır. Adından da anlaşılacağı gibi veritabanını parçalara (shards) ayırıyoruz.
Ayrıca, NoSQL'de dinamik işlem yeteneği eksikliği vardır. Bileşiğin ASİT özelliklerine sahip olacağına dair bir garanti yoktur. SQL veritabanları bu gibi durumlarda bir seçenektir. Ayrıca, uygulamanız çalışma zamanı esnekliği gerektiriyorsa NoSQL'den kaçının.
NoSQL veritabanlarının bazı dezavantajları nelerdir? NoSQL veritabanlarının dezavantajlarından biri, birden çok belgede ACID işlemleri için gereken ACID (atomluluk, tutarlılık, yalıtım, dayanıklılık) işlem desteğinden yoksun olmalarıdır. Birçok uygulama, uygun şema tasarımıyla tek kayıt atomikliğini kullanabilir.
Mongodb Parçalanabilir mi?
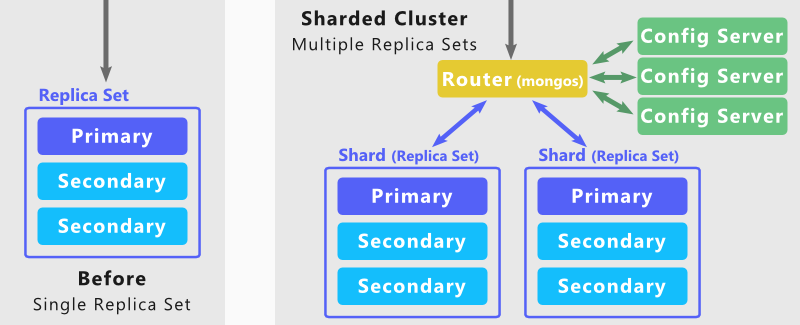
MongoDB arka ucu, son derece büyük veri kümelerini ve yüksek verimli işlemleri desteklemek için bir parçalama mimarisi üzerine kurulmuştur. Büyük miktarda veri içeren veya yüksek hızlı uygulamalar çalıştıran büyük veritabanları, sunucu kapasitesinin tehlikeye atılmasına neden olabilir.
MongoDB Sharding'i kullanarak, veritabanınızı sonsuz sayıda eşzamanlı kullanıcıyı işleyecek şekilde ölçeklendirebilirsiniz. Bu, okuma ve yazma işlemlerinin yanı sıra sistemin depolama kapasitesinin artırılmasıyla gerçekleştirilir. Aralarından seçim yapabileceğiniz çok sayıda koleksiyon var. Küme performansını en üst düzeye çıkarmak için parça anahtarını dikkatli bir şekilde seçin. MongoDB NoSQL veritabanı, parçalama özelliklerine sahip kümeler arasında iki tür veri dağıtımını destekler. Veriler, bir parçanın aralık anahtarı değeri kullanılarak aralıklara bölünebilir. Karma hashleme kullanılarak hashlenmiş bir Shard'ın değeri hesaplanabilir.
Bazı parça anahtarları kapalı olabilir, ancak karma değerlerinin aynı yığında olması pek olası değildir. Sharding ayarını yapılandırıp açarak, veritabanına erişilebilecektir. Mongolarınızın bağlı olduğundan emin olun. Parçalarınız da kümeye eklenecektir. Bu prosedürü her gerçekleştirdiğinizde, her parça için bir işlem yapmış olacaksınız. Veritabanınızda bir parçalama ayarını etkinleştirmeniz gerekir. Ardından, koleksiyonunuzu parçalamak için sh.shardCollection() yöntemini kullanın. Artık ilk parçalı kümenizi oluşturdunuz. Şimdiye kadar, uygulama etkileşimleri için yönlendiriciler (mongos örnekleri) kullanılıyordu.
MongoDB, ölçeklenebilirlik ve performans gerektiren küçük ve orta ölçekli işletmeler için mükemmel bir NoSQL veritabanıdır. Ayrıca, performansı artırmak için belgelerin parçalar arasında dağıtılmasına izin veren parçalama gibi özellikler içerir. Veritabanınız 200 GB ve üzerine çıkarsa yedekleme ve geri yükleme işlemleri yavaşlayabilir. Sonuç olarak, MongoDB veritabanınız belirli bir boyutun üzerine çıktığında her zaman MongoDB sağlayıcınıza danışmalısınız.
Hangi Veritabanları Sharding'i Destekler?

Parçalamayı destekleyen veritabanları genellikle birden çok sunucuda çalışacak şekilde tasarlanır ve her sunucu veritabanının bir bölümünü barındırır. Bu, veritabanının birden çok sunucuya yayılmasını sağlayarak performansı ve ölçeklenebilirliği artırabilir.
Nosql'de Parçalama

NoSQL teknolojilerine dayalı bölümleme kalıpları, karma oluşturmayı içerir. Bölümleme, her bölümü potansiyel olarak ayrı bir sunucuya - muhtemelen tüm dünyaya - yerleştirmeyi içerir. Dünyanın her yerinden kullanıcılar, aynı anda veri setinin farklı bölümlerine erişmelerini sağlayan bu ölçeklendirmeden yararlanabilir.
İstenen sonuca ulaşmak için bir veri seti birden fazla veritabanında saklanarak dağıtılır. Bu yaklaşım, daha büyük veri setlerinin daha küçük parçalara bölünmesine izin verdiğinden, bunları depolamak için birden çok veri düğümü kullanılabilir. Veriler birden çok makineye dağıtıldığından, parçalanmış bir veritabanı , tek bir makinenin işleyebileceğinden daha fazla isteği işleyebilir. Artan yükü sınırsız ölçüde işlemek için Sharding'i kullanarak veri tabanınızdaki verimi, depolama kapasitesini ve kullanılabilirliği artırabilirsiniz. İş yükünüz öncelikle okumak için yazıldığında, verileri çoğaltmak size önemli performans kazanımları sağlar ve parçalama kullanmanıza hiç gerek kalmayabilir. Öncelikli olarak yazmaya dayalı veya okuma-yazma ile karışık bir iş yükü için farklı bir mimari gerekir. Parçalamanın birçok farklı türü ve mimarisi vardır.

Aralık tabanlı parçalamanın kullanılması, basit ve doğrudan bir yatay bölümleme yöntemidir; ancak etkinliği, uygun anahtarların mevcudiyeti ve uygun aralıkların seçimi ile belirlenecektir. Bir karma veya algoritmik parçalama kaydı, bir çıktı veya karma değer oluşturmak için karma işlevinin veya algoritmanın kullanıldığı bir girdi olarak uygulanır. Karma tabanlı parçalama kullanılarak veriler tek bir fiziksel alanda korunabilir. İlişkisel bir veritabanında , belirli bir tabloyla ilişkili veriler diğer tablolara yayılabilir. Uygun bir anahtar elde edilemese bile, girdilerin karma hale getirilmesi, verilerin parçalar arasında eşit bir şekilde dağıtılmasına izin verir. Performansı artırmanın yanı sıra azaltılmış yayın işlemlerine yardımcı olabilir. Coğrafya tabanlı parçalama hizmeti de ilgili verileri tek bir sunucuda tek bir yerde tutar. Menzilli bir parça, coğrafi olarak dağıtılmış bir parçadır ve anahtarın anahtarı, parçalar için coğrafi konumlu bir anahtardır. Geoshard'ları tahsis etmek için bu makalede ele alınmayan bir dizi başka seçenek mevcuttur.
Sql'de Parçalama Nedir?
Bir veri deposu, karma yöntemi aracılığıyla birden çok veritabanına dağıtılabilir ve ardından birden çok makinede depolanabilir. Bu, daha büyük veri kümelerinin daha küçük parçalara bölünmesine ve birden çok veri düğümünde saklanmasına olanak tanıyarak sistemin genel kapasitesini artırır.
Bu Algoritma Verilerin Eşit Olarak Bölünmesini Garanti Etmez
Bu algoritma, bu algoritmaya göre, verilerin parçalar arasında eşit olarak dağıtılacağını garanti eder, ancak parçalar arasında eşit olarak dağıtılacağını garanti etmez. Bölüm sütunundaki user_id veri adına sahip bir satır, beş parçaya eşit olarak dağıtılacaktır; ancak, beş parça için veri değerleri eşit olarak bölünmeyecektir.
Mongodb Sharding Kullanıyor mu?
Birden fazla makine, tekniklerin bir kombinasyonunu kullanarak bir Sharding yöntemi aracılığıyla verileri paylaşabilir. MongoDB, büyük veri kümelerini dağıtırken ve yüksek hacimli işlemler gerçekleştirirken parçalama kullanır. Büyük miktarda veri içeren veritabanı sistemleri veya yüksek verim gerektiren uygulamalar, önemli miktarda depolama kapasitesi alabilir.
Parçalamanın Geleceği: Postgresql
Gelecek için bir plan yapın. Bir parçalama çözümü dağıtmak yalnızca mümkün değil, aynı zamanda gerekli bir adımdır. Sürecin bir parçası olarak, düzenli olarak ayarlama ve optimizasyon yapılması gerekir. Günümüzün parçalama çözümlerinin hızla geliştiğinin farkında olmalı ve güncel bilgileri takip etmelisiniz. PostgreSQL, son birkaç yılda parçalama alanında önemli ilerleme kaydetti, bu nedenle, birden çok platformda kullanılabilecek bir çözüm istiyorsanız, kullanmayı ciddi olarak düşünmelisiniz.
Nosql Parçalama ve Bölümleme
Büyük bir veri kümesini daha küçük bölümlere ayırmak için bölümleme ve algoritmalar benzerdir. Veriler, birçok bilgisayara yayılabilmesi için bölümlenirken, parçalama, birden çok bilgisayara dağıtılmasına izin verir. Genel olarak, bölümlenen veriler, tek bir veritabanı örneğine göre alt kümelere bölünür.
Çıkarma yoluyla bölümleme, yatay bölümlemeye ek olarak bir tür bölümlemedir. Başka bir yöntem, bir tabloyu daha küçük parçalara böldüğünüz dikey bölümlemedir. Dikey bir bölümü çoğalttığınızda buna dikey bölümleme denir. Verileri bölmek için şemayı kopyalayın ve ardından bir parça anahtarı kullanın. Bir tabloyu bölmenin ne zaman uygun olduğuna dair bazı örnekler. Veriler bölümlendiğinde, sorguları gerçekleştirmek genellikle daha kolaydır. Bir uygulamanın, siparişlerin geçmiş kaydını içeren bir Sipariş tablosu içerdiğini ve bu tablonun her hafta bölümlendiğini varsayalım. Bir haftalık emir talep ettiğinizde, Emirler tablosunun sadece bir bölümüne erişebileceksiniz. Bu sorgu için bir bölüm budama prosedürü teorik olarak 100 kat daha hızlı çalışmasını sağlayabilir.