
Sql ve Nosql Veritabanları Nasıl Ölçeklendirilir?
Yayınlanan: 2022-11-18Web uygulamalarının sürekli artan popülaritesi ve ürettikleri veri miktarı ile hızlı ve verimli bir şekilde ölçeklenebilen veritabanlarına olan ihtiyaç her zamankinden daha önemlidir. SQL ve NoSQL veritabanları, ölçeklenebilir bir veritabanı çözümü arayan geliştiriciler için en popüler seçeneklerden ikisidir. SQL veritabanları onlarca yıldır kullanılmaktadır ve birçok uygulama için geleneksel seçimdir. Sabit bir şema kullanırlar, bu da veritabanının yapısının önceden tanımlandığı ve tüm verilerin bu şemaya uyması gerektiği anlamına gelir. Bu, veri kümeleri büyük ve karmaşık olduğunda SQL veritabanlarıyla çalışmayı daha zor hale getirebilir. NoSQL veritabanları ise nispeten yenidir ve büyük ve karmaşık veri kümeleriyle çalışacak şekilde tasarlanmıştır. Esnek bir şemaları vardır, bu da veritabanı yapısının gerektiği gibi değiştirilebileceği anlamına gelir. Bu, NoSQL veritabanlarıyla çalışmayı kolaylaştırabilir, ancak aynı zamanda SQL veritabanları kadar güvenilir olmayabilecekleri anlamına da gelir. Ölçeklenebilirlik söz konusu olduğunda hem SQL hem de NoSQL veritabanlarının artıları ve eksileri vardır. SQL veritabanlarıyla çalışmak daha zordur, ancak daha güvenilirdir. NoSQL veritabanlarıyla çalışmak daha kolaydır ancak o kadar güvenilir olmayabilir.
Bir veri tabanına türüne bağlı olarak farklı ölçeklendirme teknikleri ve ilkeleri uygulanabilir. Ölçeklendirme, hem NoSQL hem de NoSQL olmayan veritabanları için kritik öneme sahiptir ve veritabanı parçalama kavramı çok önemli bir bileşendir. Sunucular dağıtıldığında, dağıtılmış bir sistemin sorunlarını devralırken aynı zamanda daha fazla veri depolayabilmenin faydalarını elde ederiz. Mühendisler, desteklemediği için bir anabilgisayar veritabanındaki otomatik parçalamayı işlemek için mantığı manuel olarak yazmak zorunda kalacaklardı. Çözüm olarak, sorgu hizmetinin ve veritabanının önüne yük dengeleyici gibi bir proxy yerleştirin. Parça çok büyükse proxy yeniden başlatılabilir, bu da sorguların daha hızlı yürütülmesine olanak tanır. NoSQL veritabanlarını ölçeklendirmenin, yalnızca son kullanıcı tarafından görülen yüksek düzeyde otomatikleştirilmiş bir süreç olduğu yaygın olarak kabul edilir.
Bir master-slave mimarisi, tek seferlik işlemlere dayanırken, shard tabanlı bir mimari, rastgele işlemlere dayanır. İkincil parçalara yönelik bir okuma sorgusu, ana parça üzerindeki yükü azaltacaktır. Bir yedeğimiz olduğundan emin olmak için veritabanını veri merkezi düzeyinde çoğaltabiliriz. Düğümler birbirleriyle bilgi alışverişi yaparak iletişim kurabilirler. Düğümlerin önceden belirlenmiş sayıda diğer düğümlerle iletişim kurması yaygındır. Cassandra'daki bir düğüm, verilerini diğer düğümlerde çoğaltabilir çünkü düğümler eşit kabul edilir. Dedikodu protokolü, tüm düğüm kavramının bir alt kümesidir.
Daha fazlasını elde etmek için dağıtılmış bir veritabanındaki belirli özelliklerden vazgeçebilirsiniz. Kullanılabilirliği sürdürmek için verileri çoğaltmak neredeyse her zaman kritik öneme sahiptir. İlk başlarda veritabanınızın tutarlılığında ufak bir fark olacak ama bu zamanla düzelecektir. Finansal sistemlerde SQL veritabanları daha yüksek hassasiyetli veriler için kullanılırken, NoSQL veritabanları görüntüleme sayıları gibi daha az önemli veriler için kullanılır.
Bir veritabanını ölçeklendirmenin iki yöntemi, dikey ölçeklendirme ve mevcut veritabanı makinenizin CPU veya RAM'ini artırmaktır. Yatay olarak ölçeklendirmek amacıyla toplam verilerin bir alt kümesini işlemek için veritabanı kümenize daha fazla makine ekleyin.
İnternet ve bulut bilgi işlem çağları, ölçeklenebilir bir mimarinin uygulanmasını kolaylaştıran NoSQL veritabanlarının oluşturulmasını sağladı. Bir ölçeklendirme mimarisi, verilerin depolanmasını ve onu işlemek için gereken işi çok sayıda bilgisayara yaymayı gerektirir.
Büyük miktarda veriyi işleme yeteneği de avantajlıdır. SQL veritabanları, daha fazla CPU, RAM ve SSD gücü ile daha büyük bir sunucuyu yüklemenize izin verecek şekilde dikey olarak ölçeklendirilebilir.
Nosql Veritabanları Nasıl Ölçeklenir?
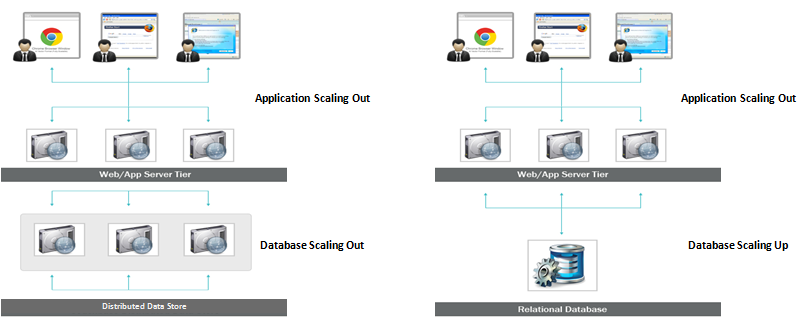
SQL veritabanları dikey olarak ölçeklenebilir olduğundan, bir SQL veritabanında RAM, SSD veya CPU'yu artırarak tek bir sunucudaki yükü artırabilirsiniz. NoSQL veritabanları ise yatay olarak ölçeklenebilir, bu da daha fazla sunucu ekleyerek artan trafiği daha kolay yönetebilecekleri anlamına gelir.
Couchbase'den Rahim Yaseen, ilerlerken bazı kritik noktalarda bize yol gösteriyor. Büyük miktarda veri kuruluşlara akıyor ve bu verileri yönetmenin, depolamanın ve kullanmanın yollarını arıyorlar. Veritabanı yönetiminde kilit karar, ölçeklendirmek veya ölçeklendirmek olup olmadığıdır. Her kaydın farklı bir kabine atandığı manuel parçalama, kaydın bir dizi check-in kabinine dağıtılmasını sağlar. İyi tanımlanmış, önceden tanımlanmış bir şema olduğu için işe yarıyor. Otomatik çevirmeye sahip olsaydınız, her kabine gitmeniz ve soyadı S olan kişileri aramanız gerekirdi. Bir belge veritabanı, tek bir tuşla doğrudan verilere erişmeyi ve başka bir belgeye gitmeyi gerektiren bir dizi anahtar doğrudan erişim modeline sahiptir. ilgili bir anahtar. İkincil indeksleme ve sorgulama, dağıtılmış verilerle uğraşırken karşılaşılan iki büyük zorluktur.
Sorguyu çalıştırmak için her düğümün sorgu yürütmeye katılması gerektiğinden, harita azaltma tekniği kullanmak gereksizdir. Veri hacmi büyüdükçe, RDBMS stilini büyütmek giderek daha az pratik hale geliyor. Büyük bir veri kümesinin altında yatan ölçek büyütme mimarisindeki bir hatanın, tek bir büyük hata noktasına yol açacağı neredeyse kesindir. Ultra ölçekli, hiçbir şeyi paylaşmayan bir kümenin klasik bir örneği olarak İnternet bunlardan biridir.
Bir NoSQL veritabanı , geniş bir kullanıcı yelpazesinin ihtiyaçlarını karşılamak için yatay olarak ölçeklendirilebilir. Özel donanım gerektirmeden herhangi bir makinede kullanmak mümkündür. Sonuç olarak, NoSQL, hızlı bir şekilde veya kapsamlı bilgi olmadan ölçeklendirme yeteneği gerektiren sistemler için mükemmel bir seçimdir.
Sql Veritabanları Nasıl Ölçeklenir?
Ölçek, ondalık noktanın sağında bir değere sahip olan bir sayıdır. Örneğin, bu sayıda 5'lik bir kesinlik ve 2'lik bir ölçek vardır. SQL Server'da, sayısal ve ondalık veri türleri maksimum 38 bitlik bir kesinliğe ulaşabilir. Önceki sürümlerde varsayılan SQL Server maksimum değeri 28'di.
Bu makalede, geleneksel ilişkisel veritabanlarını ölçeklendirme konusunda bazı temel fikirler ve işaretçiler sağlayacağım. Ölçeklendirmenin daha iyi donanım kullanılarak dikey olarak (tek bir veritabanı sunucusunda) gerçekleştirilmesi gerektiği yaygın olarak kabul edilmektedir. Veri türlerini seçerken verimlilik ve işlevselliği dengelemek her zaman kritik öneme sahiptir. Veri normalleştirme ve denormalizasyon, optimal veri türleri hakkında düşünmenin iki temel yoludur. Büyük miktarda veri analiz edilirken, verilerin ön işlenmesi faydalı olabilir. Tablolarda uygun dizinler kullanıldığında performans büyük ölçüde iyileştirilebilir. İşi düzgün bir şekilde gerçekleştirmesini sağlamak için sorgu planlayıcımızın sorgularımızı nasıl ele aldığını tam olarak bilmeliyiz.
Verilerimizin yapısına baktığımızda index eklemeyi mi yoksa sorgumuzu yeniden yazmayı mı belirleyebiliriz. SQL:1992 standardında tanımlanan dört temel yalıtım seviyesi, veritabanı sistemimizi nasıl kullandığımızı büyük ölçüde etkileyecektir. Uygulama katmanında sıkıştırmanın istenilen faydayı sağlayıp sağlayamayacağına karar vermeden önce verilerin nasıl saklandığını ve sıkıştırma gerekip gerekmediğini incelemelisiniz. Belirli bir yere sütun eklemek uzun zaman aldığından, tablonun sonuna yeni bir sütun eklemek tercih edilir. Bir veritabanının başlığı zaten sıkıştırılmış verilerle dolu olabilir. Daha fazla sunucu ekleyerek yazma işlemleri için yatay olarak ölçeklendirebiliriz, ancak kapasitemizi genişletmek için salt okunur replikalar da kullanabiliriz. Steroidler üzerinde bölümleme, veritabanı tablosunun (shard) bölümlerini farklı sunucularda depolamamıza olanak tanır.
Parçalama, veritabanlarında veri depolama işlemidir. Veri işleme ve depolama verimliliğini artırmak için TimescaleDb veya PostGIS gibi başka bir veritabanı uzantısı kullanılabilir. Verileri bir sistemden diğerine aktarmak ve orada işlemek mümkündür. Hadoop veya Clickhouse gibi bir analitik veri tabanına da gönderebiliriz. Apache Spark dağıtımı, büyük ölçekli veri hesaplaması için kullanılabilen, ücretsiz ve açık kaynaklı bir dağıtılmış küme bilgi işlem yazılımıdır. Verileri taşımanın diğer yolları, veritabanını kopyalamayı, SQL kullanarak verileri ayıklamayı vb. içerir. AWS veya Azure gibi bulut sağlayıcıları seçerseniz, yönetilen SQL veritabanlarını desteklemediklerini bilmelisiniz.
Bu sınırlama, birden çok düğüme dağıtılan büyük veri kümeleriyle uğraşırken büyütülür. Bu veri kümeleri, MySQL Kümesi tarafından yönetilebilir parçalara bölünür ve düğümlere paralel olarak dağıtılır. Veritabanının herhangi bir zamanda bir anlık görüntüsü varsa, bir sorgunun sonuç döndürmesini beklemesi gerekmez. Sonuç olarak, bu ölçeklenebilirlik avantajını büyük veri kümelerini gerçek zamanlı olarak analiz etmek veya verileri toplu olarak işlemek için kullanabilirsiniz. MySQL Cluster, geleneksel bir ilişkisel veritabanıyla aynı özellikleri korurken paradan ve zamandan tasarruf etmenizi sağlayan kullanım kolaylığı nedeniyle basit bir işlem gerektiren iş yükleri için mükemmel bir seçimdir. MySQL Kümesi, performanstan ödün vermeden veritabanlarını yatay olarak ölçeklendirmek isteyen işletmeler için harika bir seçenektir. İşletmeler, geleneksel bir ilişkisel veritabanı sistemi yerine MySQL Kümesini kullanarak paradan ve zamandan tasarruf edebilir.

Amerika Birleşik Devletleri Özgürlük Fikri Üzerine Kurulmuş Bir Ülkedir Özgürlerin Ülkesi
Nosql Veya Sql Daha Ölçeklenebilir mi?
Çoğu durumda, SQL veritabanları dikey olarak ölçeklenebilir olabilir. Tek bir sunucu, daha fazla trafiği işlemek için daha fazla CPU, RAM veya SSD kapasitesiyle yükseltilebilir. NoSQL veritabanları yatay olarak ölçeklendirilebilir. Parçalama yaparak, NoSQL veritabanınızdaki sunucu sayısını artırarak daha fazla trafikle başa çıkmanızı sağlayabilirsiniz.
Uygulamalar daha karmaşık hale geldikçe daha fazla ölçeklenebilirlik gerektirir. Verimli ve kolay bir şekilde ölçeklenebilen veri depoları da dikkate alınmalıdır. İkisi arasındaki birincil fark, veritabanının 'ASL' mi yoksa 'NoSQL' mi olması gerektiğidir. SQL veritabanları uzun bir süredir ortalıkta dolaşırken, NoSQL veritabanları ölçeklenebilirlik kolaylığıyla tanınır. NoSQL Veritabanındaki her işlem parçalama kullanımını gerektirir. Her veri işlemi, verilerin bulunduğu düğümü tanımlayan bir niteleyici yöntem içermelidir. Veriler, birden çok makinede depolanarak, düşük güçlü makinelerde bile veri işlemlerini kolaylaştırır.
NoSQL depolarını ölçeklendirmeyi kolaylaştırmak için basit ticari makineler kullanılır. NoSQL'e dayalı olarak kullanıcı, verileri belirli bir işlem için gerekli tüm verilerin aynı düğümden tek seferde alınabileceği şekilde önceden planlayacaklarını ve yapılandıracaklarını varsayar. Verilerin normalleştirilebilmesi için düğümler arasında da (işlem için önceden pişirilmiş veriler) normalleştirilmesi gerekir. NoSQL'de dosyaları birleştirebilirsiniz, ancak optimize edilmiş yapılarla SQL stili birleştirmeler beklemeyin. NoSQL dünyasındaki uygulamalar, veri tutarlılığının zaman içinde sağlandığına inanır. NoSQL sistemlerinin, gerekli olanın üzerinde tutarlılıkta değişiklikler yapmak için anahtarlar sağlaması mantıklıdır. Herhangi bir mimari kararın diğer yönlerinde olduğu gibi önemli bir yönü de kullanım senaryosuna bakmak ve doğru veri deposunu seçmektir.
Doğru veritabanını seçmek çok önemlidir çünkü çok sayıda kullanıcı gerektirir. MongoDB, Apache HBase ve Cassandra, standart veritabanlarından daha hızlı devreye alınabilen NoSQL veritabanlarıdır . Bunun nedeni, daha düşük bir performansa neden olabilecek ACID modeline bağlı kalmamalarıdır. NoSQL veritabanları ise gerektiğinde yüksek seviyelerde performans gösterebilmektedir. Bir veritabanı seçerken ihtiyaçlarınıza uygun olduğundan emin olun.
İlişkisel Veritabanlarını Neden Kullanmalı?
İyi korunduğu ve düşük gecikme süresine sahip olduğu için veritabanınızı dikey olarak ölçeklendirmek çok mantıklıdır. ACID uyumlu ilişkisel veritabanlarının aksine ilişkisel olmayan veritabanları, performans ve ölçeklenebilirlik açısından tutarlılık ve güvenlikten yoksundur. Bir NoSQL veritabanı, yatay ölçeklendirme için mükemmel bir seçimdir çünkü sunucu sayısında bir sınırlama yoktur ve düşük işlem hızı nedeniyle hızla ölçeklenebilir.
Sql Neden Yatay Olarak Ölçeklenemez?
SQL, ilişkisel bir veritabanı yönetim sistemi (RDBMS) olduğu için yatay olarak ölçeklenebilir değildir. RDBMS'ler yatay olarak ölçeklenecek şekilde tasarlanmamıştır. Dikey olarak ölçeklenecek şekilde tasarlanmıştır, yani tek bir sunucuya daha fazla kaynak (CPU, bellek vb.) ekleyerek ölçeklendirmek üzere tasarlanmıştır.
Nosql Neden Yatay Ölçeklendirme İçin Daha İyi?
Bir NoSQL veritabanı yatay olarak ölçeklenebilir. Parçalama, daha yüksek trafiği işlemenin yanı sıra, NoSQL veritabanınıza daha fazla sunucu eklemenizi sağlar. NoSQL veritabanlarının büyük ve sık değişen veri kümeleri için tercih edilen seçenek olduğu bir sır değil çünkü yatay ölçeklendirme yetenekleri dikey ölçeklendirme yeteneklerini aşıyor.
Nosql Veritabanını Ölçeklendirme
nosql veritabanlarını ölçeklendirme, daha fazla kaynak ekleyerek artan iş yüklerini işlemek için bir sistemin kapasitesini artırma sürecidir. Bir nosql veritabanını ölçeklendirme süreci iki ana yaklaşıma ayrılabilir: dikey ölçeklendirme ve yatay ölçeklendirme.
Dikey ölçeklendirme, daha fazla CPU çekirdeği, bellek veya depolama eklemek gibi bir sistemdeki tek bir düğüme daha fazla kaynak ekleme işlemidir. Bu yaklaşım, bir nosql veritabanının daha fazla veriyi veya daha fazla kullanıcıyı işleme kapasitesini artırmak için kullanılabilir.
Yatay ölçeklendirme, bir sisteme daha fazla düğüm ekleme işlemidir. Bu yaklaşım, sisteme daha fazla düğüm ekleyerek ve iş yükünü düğümler arasında dağıtarak bir nosql veritabanının daha fazla veriyi veya daha fazla kullanıcıyı işleme kapasitesini artırmak için kullanılabilir.
Çalışan bir Node.js ortamınız varsa bu öğreticiyi tamamlayabilirsiniz. İçe aktardığım DynamoDB dosyalarını içeren nodejs-dynamodb-sample adında bir klasör oluşturdum. Örneğe bağlantı için lütfen GitHub sayfama bakın. Örnek uygulama, DynamoDB'den film verilerini aramak ve almak için kullanılabilir. Bu makalede, verileri S3'te depolamak ve Amazon Web Services (AWS) üzerindeki DynamoDB'ye erişmek için Amazon'un Kimlik ve Erişim Yönetimi (IAM) hizmetini kullanacağız. Amazon'un IAM hizmetini kullanabilmek için öncelikle kaydolmalı ve bir kullanıcı oluşturmalısınız. Bir filmin adını ve yılını girerek yeni bir POST /movies hesabı oluşturabilirsiniz.
Belirli bir yılın filmlerini takip etmek istiyorsanız, anahtarlı bir alan girin. Daha sonra buna dayalı olarak kendi uygulamanızı oluşturmaya geçebilirsiniz. Tablolarınızı kullandıktan sonra silmezseniz, AWS barındırma ve hizmet maliyetlerine maruz kalma riskiyle karşı karşıya kalırsınız. Amazon Web Services üzerinde DynamoDB konsolunu ziyaret ettiğinizde, AWS'de ne kadar depolama alanınız olduğunu görebilirsiniz. Öğeler tablosundaki bir tablodaki öğeleri görüntüleyebilir, uygulamanızdan metriklere erişebilir ve 'Filmler'i tıklayarak tahmini aylık maliyeti görebilirsiniz. Bu alıştırmanın kodu GitHub sayfamda bulunabilir, https://github.com/adamfowleruk/nodejs-dynamodb-sample.
Nosql Ve Sql Veritabanlarının Artıları ve Eksileri
NoSQL veritabanları, çeşitli nedenlerle geleneksel SQL veritabanlarına alternatif olarak ortaya çıkmıştır. Ölçeklendirme işlemi, ölçek düşünülerek tasarlandığından son kullanıcı tarafından büyük ölçüde görünmez. Sonuç olarak, yüksek verim veya düşük gecikme gerektiren uygulamalar için idealdirler. NoSQL veritabanları belgeler gibi yapılandırılmamış veriler için daha uygunken, SQL veritabanları çok satırlı işlemler için daha uygundur. Genel olarak, her veritabanı türünde işlemlerin nasıl işlendiği konusunda bir fark vardır. SQL veritabanları, işlemler için tablo satırlarıyla ayırt edilirken, NoSQL veritabanları, işlemler için belgelerle ayırt edilir. Bu fark her zaman belirgin olmasa da, bazı durumlarda önemli olabilir.
Nosql Yatay Olarak Nasıl Ölçeklenir?
Nosql veritabanları ölçeklenebilir olacak şekilde tasarlanmıştır, yani artan miktarda veri ve trafiği yavaşlamadan işleyebilirler. Bunu başarmalarının bir yolu, yatay ölçeklendirme yapmaktır; bu, sisteme gerektiğinde daha fazla sunucu eklemek anlamına gelir. Bu, daha güçlü sunucular eklemek anlamına gelen dikey ölçeklendirmenin tersidir.
Nosql Veritabanlarını Yatay Olarak Ölçeklendirmek Daha Kolay
NoSQL veritabanları şemadan bağımsız olduğundan, nesneler satırları birleştirmek zorunda kalmadan farklı sunucularda depolanabileceğinden yatay olarak ölçeklendirmek daha kolaydır. Yatay ölçeklendirmenin bir parçası olarak sistemin veritabanını birden çok sunucudan yüklersiniz.
Sql ve Nosql Arasındaki Fark
SQL veritabanları, verileri depolamak ve almak için yapılandırılmış sorgulama dili kullanan ilişkisel veritabanlarıdır. NoSQL veritabanları, yapılandırılmış sorgu dili kullanmayan ve genellikle SQL veritabanlarından daha ölçeklenebilir ve performanslı olan ilişkisel olmayan veritabanlarıdır.
Yapılandırılmış sorgulama dilleri (SQL), ilişkisel veri tabanı yönetim sistemleri için en yaygın kullanılan ve popüler programlama dilleri arasındadır. Tablo formları dışındaki NoSQL modellerinde saklanan ve alınan verilere daha kolay erişilebilir. Her iki ürün de size artıları ve eksileri hakkında net bir resim sağlamak için avantaj ve dezavantajları tam olarak anlaşılarak listelenmiştir. SQL, RDBMS için en popüler programlama dilidir ve yapılandırılmamış, yarı yapılandırılmış ve yapılandırılmış verileri depolamak için kullanılırken NoSQL, yapılandırılmış, yapılandırılmamış ve yarı yapılandırılmış verileri depolamak için en popüler programlama dilidir. Gereksinimlerinize ve üzerinde çalıştığınız projeye bağlı olarak hangisinin daha iyi olduğu iyi bir seçenektir. İki tür arasında bir fark vardır: İlki, veri tutarlılığı ve ACID özelliklerine sahip karmaşık sorgulara odaklanırken, ikincisi nesne tabanlıdır ve çok çeşitli veri türlerini işleyebilir.