
Nosql İçin Spark mı?
Yayınlanan: 2023-02-05Spark, verilerle, özellikle de büyük veri kümeleriyle çalışmak için güçlü bir araçtır. Hızlı ve verimli olacak şekilde tasarlanmıştır ve NoSQL veritabanları da dahil olmak üzere çeşitli veri biçimlerini destekler. NoSQL veritabanları, büyük miktarda veriyi işlemek için çok uygun oldukları için giderek daha popüler hale geliyor. Spark, NoSQL verilerini verimli bir şekilde sorgulamanıza ve değiştirmenize yardımcı olabilir.
Etkin bir şekilde çalışmak için, uygulamanızın veritabanlarını Apache Spark ve NoSQL ( Apache Cassandra ve MongoDB) kullanarak yönetmeniz çok önemlidir. Bu blogun amacı, NoSQL arka uçlarını kullanarak Apache Spark uygulamaları geliştirmek için ipuçları sağlamaktır. Bu bir tema parkıdır ve TCP/IP sPark hem CassandraLand hem de MongoLand'da oyuncaklara sahiptir. DOE verilerini sorgulamaya çalıştığımızda Spark uygulamamız kendi ekseni dışında dönmeye başladı. Buradaki ders, Cassandra'yı sorguladığınızda tuş dizilerinin önemli olduğudur. CassandraLand ayrıca en popüler cazibe merkezlerinden biri olan Partitioner roller coaster'ı da sunmaktadır. Müşteriler hız treni yolculuğunun tadını çıkarırken, yolculuk operatörleri bilgilerini saklayarak her gün kimin bindiğini takip edebilir.
Birinci derste, MongoDB bağlantılarını yönetmeyi ele alacağız. Enerji Bakanlığı'nın yeni park üyelik durumu gibi bir parkla ilgili bilgileri güncellemeniz gerektiğinde, mongo dizinlerini kullanabilirsiniz. MongoDB ve Spark, bağlantınızın düzgün bir şekilde yönetilmesini sağlamak için ve ayrıca belirli durumlarda indeksler kullanılmalıdır.
Apache Spark, açık kaynaklı ve büyük veri iş yüklerinde kullanılmak üzere oluşturulmuş popüler bir dağıtılmış işleme sistemidir. Bu özellik, bellek içi önbelleğe alma ve optimize edilmiş sorgu yürütmeye ek olarak, büyük miktarda veriye karşı hızlı analitik sorgular sağlar.
Hemen hemen aynı kodla, toplu ve gerçek zamanlı verileri aynı anda işlemesine izin vererek daha verimli ve çok yönlüdür. Sonuç olarak, eski Büyük Veri araçları , bu işlevsellikten yoksun oldukları için giderek daha eski hale geliyor.
Spark Ne Tür Veritabanıdır?
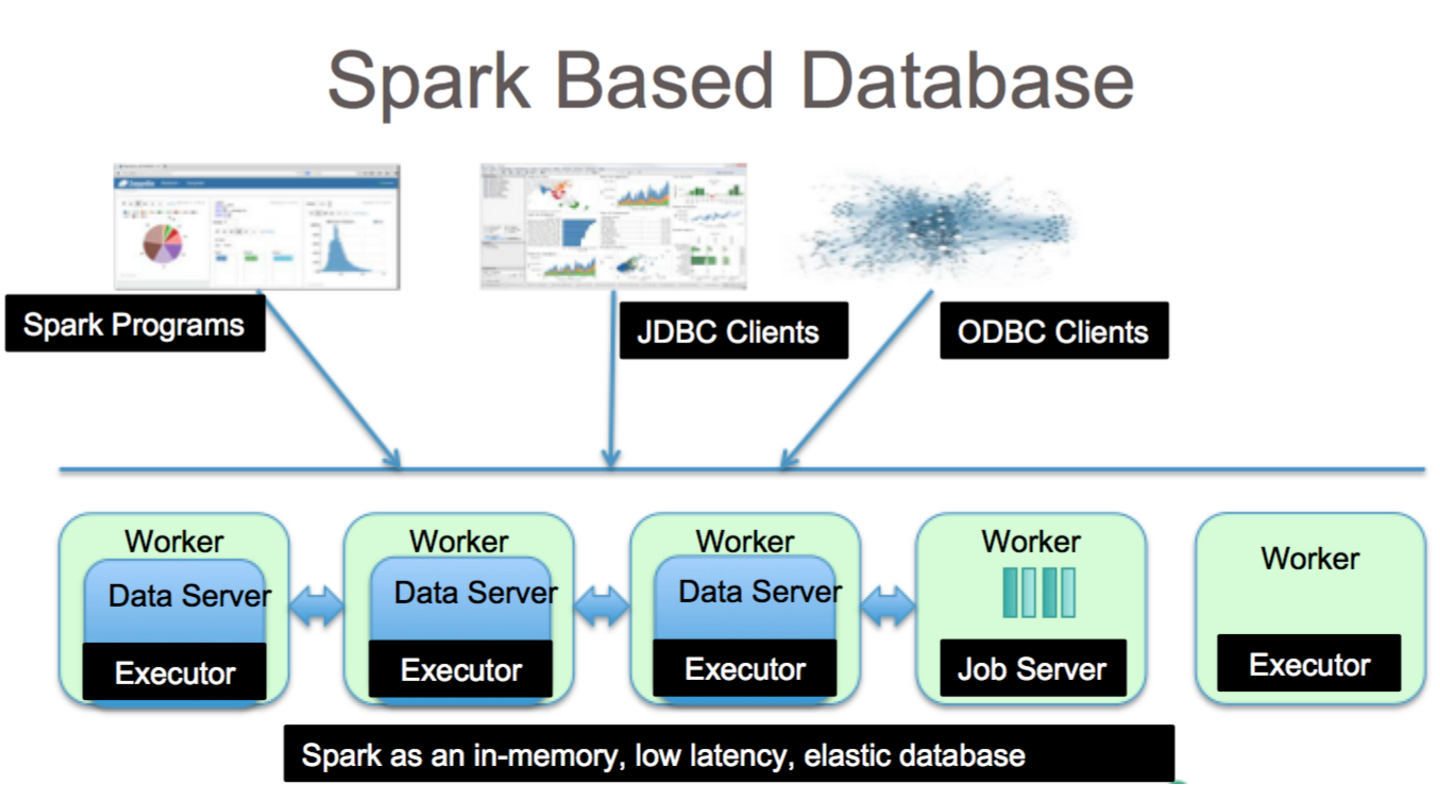
Apache Spark, (HDFS), NoSQL veritabanları ve ilişkisel veritabanları dahil olmak üzere çeşitli veri havuzlarından verileri işleyebilen bir veri işleme çerçevesidir.
İlişkisel veritabanları için çok sayıda abartı döngüsü olmasına rağmen, NoSQL veritabanlarındaki son gelişmelere ve yükselişe rağmen popüler olmaya devam edecekler. Zamanla, verileri ilişkisel veritabanlarında depolamak giderek daha zor hale geldi. Bu makalede, küresel ölçekte ilişkisel veri tabanının gücünden yararlanma konusundaki önemli gelişmelerden bazılarına bakacağız. İlk piyasaya sürüldüğünde, Spark ve Büyük Veri Analizi arasındaki arayüz minimum seviyedeydi. Pek çok kişi, güçlü ancak nispeten yavaş olan bu programı çalıştırmak için çok sayıda kod yazdı. Kullanıcılar bu iki modeli Spark SQL veri tabanında kolaylıkla birleştirebilecekler. Ayrıca, çeşitli kaynaklardan çok çeşitli veri biçimlerini kabul eder.
Apache Spark açık kaynak projesi, ona katkıda bulunan yüzlerce katılımcıyla en aktif olanıdır. Ücretsiz bir açık kaynak projesi olmasının yanı sıra Spark SQL, ana akım endüstrilerde popülerlik kazanmaya başladı. Spark SQL'e ek olarak, Databricks Cloud müşterilerinin (Spark çalıştıran barındırılan hizmet) yaklaşık üçte ikisi diğer programlama dillerini kullanıyor. İlk örnek olay incelememizin sona ermesinin ardından, bu uygulamalı örnek olay incelemesinde veri tuğlalarının duruma nasıl uygulanacağını göstereceğiz. Spark DataFrame , aynı şema ile dağıtılan bir dizi satırdır (satır türleri). Veri kümesindeki her sütun bir adla etiketlenir. DataFrame'in API'si, geliştiricilerin prosedürel ve ilişkisel kodu entegre etmesine olanak tanır.
Spark ayrıca UDF'ler gibi gelişmiş işlevleri de işleyebilir. İlişkisel bir veritabanındaki bir tablo, bir veri çerçevesi veritabanındaki bir veri çerçevesine benzer, ancak daha fazla optimizasyon söz konusudur. Spark'ın yerel dağıtılmış koleksiyonları (RDD'ler) ile aynı şekilde manipüle edilebilirler. Genel olarak Spark SQL sorgusu , Shark sorgusundan daha hızlıdır ve Impulsa ile daha rekabetçidir. Sorgu seçiciliğinin tablolardan birinin çok küçük olmasına neden olduğu Sorgu 3a'da, Impala ile Impala arasında önemli bir fark vardır.

Spark SQL ile veri analizi için harika bir araçtır. HiveQL sözdizimi, Hive SerDes ve HiveDF'lere HiveQL sözdiziminin yanı sıra Hive SerDes ve HiveDF'ler aracılığıyla erişilebilir. Kovan meta depoları , SerDes ve UDF'ler zaten uygulanmıştır. Spark bir veritabanı olmasına rağmen aynı zamanda bir NoSQL veritabanıdır. Sonuç olarak, Spark'ta yönetilen bir tablo oluşturduğunuzda, verilerinizi depolamak için çeşitli SQL uyumlu araçlar kullanabileceksiniz. SQL ifadeleri, jdbc.org'dan bağlayıcılar aracılığıyla JDBC'ye bağlanarak Spark'taki tablolara erişmek için kullanılabilir. Sonuç olarak Tableau, Talend ve Power BI gibi üçüncü taraf araçları da kullanabilirsiniz. Spark'ı kullanabilme özelliği, veri analizi için idealdir ve çok çeşitli sektörler için kullanışlı bir araçtır.
Spark Sql: Her İki Dünyanın En İyisi
Daha önce bahsedilen iki model, prosedürel ve ilişkisel modeller arasındaki boşluğu, iki ana bileşeni dahil ederek kapatır. Sonuç olarak, bir DataFrame API kullanarak harici veri kaynakları ve Spark'ın yerleşik dağıtılmış koleksiyonları üzerinde büyük ölçekli ilişkisel işlemler yürütebilirsiniz.
Veri tabanında kıvılcım nedir? Makine öğrenimi, etkileşimli sorgu işleme ve gerçek zamanlı iş yüklerini kullanan açık kaynaklı bir çerçevedir. Bu şirketin kendi depolama sistemi yoktur; bunun yerine, kendisinin yanı sıra HDFS, Amazon Redshift, Amazon S3, Couchbase ve diğerleri gibi diğer depolama sistemlerinde analitik kullanır. Yapılandırılmış veri işleme söz konusu olduğunda, Spark SQL yalnızca bir veritabanı değildir; aynı zamanda bir modüldür. Büyük çoğunluğu, SQL sorgularıyla birlikte çalışan programlama soyutlamaları olan DataFrames üzerine yazılmıştır.
“sparksql” için SQL sql türü nedir? Hive SQL, HiveQL sözdiziminin yanı sıra Hive SerDes ve UDF'leri destekleyerek önceden oluşturulmuş Hive ambarlarına erişmenize olanak tanır. Spark SQL'de mevcut Hive meta depolarını, SerDes'i ve UDF'leri kullanmak zor değil.
Mongodb Spark'ı Çalıştırabilir mi?
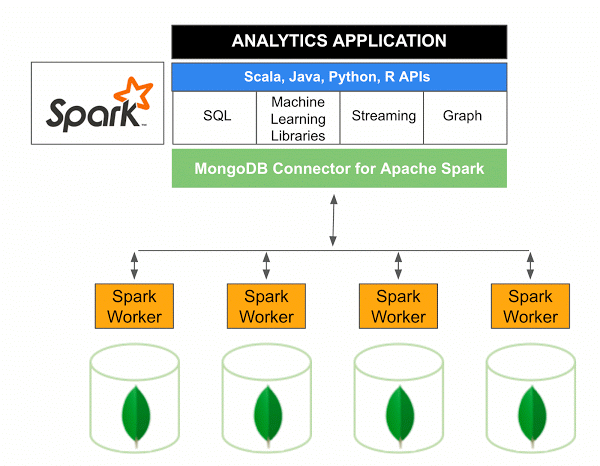
Apache Spark için MongoDB Connector'ın 10.0 sürümü, yeni Spark Data Sources API V2 aracılığıyla Spark Yapılandırılmış Akış desteğinin yanı sıra yeni Spark Data Sources API V2'nin uygulanmasını içerir.
Spark için MongoDB bağlayıcısı, Scala kullanarak MongoDB'den veri yazmanıza ve MongoDB'den okumanıza izin veren açık kaynaklı bir projedir. Bağlayıcıların kullanım yöntemleri nedeniyle, Spark ve MongoDB arasındaki etkileşimler basitleştirilmiştir ve bu da onu gelişmiş analitik uygulamalar oluşturmak için güçlü bir kombinasyon haline getirir. Yerleşik çoğaltma ve parçalama özelliklerini kullanan Spark, MongoDB veritabanlarını kullanan çeşitli iş yüklerinde uygulanabilir.
Spark: Veri Açısından Zengin Uygulamalar Oluşturmanın Hızlı Yolu
Güçlü bir araç olan Spark'ın yardımıyla, daha işlevsel uygulamaları hızla geliştirebilirsiniz. Geliştiriciler, MongoDB'yi dahil ederek, tek bir veritabanı teknolojisinden yararlanarak geliştirme sürecini hızlandırabilir. Ayrıca Spark, bulut tabanlıdır ve NoSQL veri depoları için destek içerir, bu da onu veri yoğun uygulamalar için ideal hale getirir.