
MapReduce: Büyük Veri Setleri İçin Bir Programlama Modeli
Yayınlanan: 2023-01-08MapReduce, bir küme üzerinde paralel, dağıtılmış bir algoritma ile büyük veri kümelerini işlemek ve oluşturmak için bir programlama modeli ve ilişkili bir uygulamadır.
Yeni teknolojiler kullanarak büyük miktarda veriyle çalışma şeklimizi dönüştürüyoruz. Hadoop, NoSQL ve Spark gibi veri ambarları bu alandaki en önemli oyunculardan bazılarıdır. DBA'lar ve altyapı mühendisleri/geliştiricileri, yüksek düzeyde karmaşıklıkla sistemleri yönetme konusunda uzmanlaşmış yeni nesil profesyoneller arasındadır. Hadoop, bir veritabanı yerine, devasa dosyalar biçiminde paralel hesaplamaya izin veren bir yazılım ekosistemidir. Bu teknoloji, büyük verinin devasa işlem ihtiyaçlarını desteklemek açısından önemli faydalar sağlamıştır. Büyük bir veri işlemi için, ortalama bir Hadoop kümesinin, merkezi bir ilişkisel veritabanı sisteminde genellikle 20 saat sürecek olan büyük bir işlemi işlemesi yalnızca üç dakika sürebilir.
Bir mapreduce kümesi , normal bir kümeyle aynı şekilde büyük veri kümelerini işleyen ve üreten bir paralel algoritmaya ve bir programlama modeline sahip bir kümedir.
Apache Hadoop ekosistemi, dağıtılmış bilgi işlemi desteklemek için tasarlanmıştır ve güvenilir, ölçeklenebilir ve kullanıma hazır bir ortam sağlar. Bu projenin MapReduce modülü, Hadoop'ta (dağıtılmış bir dosya sistemi) bulunan devasa veri kümelerini işlemek için kullanılan bir programlama modelidir.
Bu modül, Apache Hadoop açık kaynak ekosisteminin bir bileşenidir ve Hadoop Dağıtılmış Dosya Sistemindeki (HDFS) verileri sorgulamak ve seçmek için kullanılır. Veriler, bu tür seçimler yapmak amacıyla kullanılabilen bir MapReduce algoritması kullanılarak çeşitli sorgular için seçilebilir.
MapReduce kullanarak, büyük veri işleme görevlerini yürütmek mümkündür. MapReduce programlarını C, Ruby, Java, Python ve diğerleri dahil olmak üzere herhangi bir programlama dilinde oluşturabilirsiniz. Bu programlar, MapReduce programlarını çalıştırmak için aynı anda kullanılabilir, bu da onları büyük ölçekli veri analizinde çok faydalı kılar.
Mapreduce Mongodb'da Ne İçin Kullanılır?
MongoDB'deki haritalar, kullanıcıların büyük veri kümeleri gerçekleştirmesine ve bunlardan toplu sonuçlar oluşturmasına olanak tanıyan bir veri işleme programlama modelidir. MapReduce, MongoDB tarafından haritaları azaltmak için kullanılan yöntemdir. Bu işlev iki bileşene ayrılmıştır: bir harita işlevi ve bir küçültme işlevi.
MongoDB'nin MapReduce aracını kullanarak büyük veri kümelerini düzenlemek ve bir araya getirmek mümkündür. MongoDB'deki bu komut, büyük miktarda veriyi işlemek için MongoDB'deki iki birincil girişi kullanır: harita işlevi ve azaltma işlevi. Örnekleri tanımlamak için aşağıdaki adımları izleyin. Harita işlevini, azaltma işlevini ve örnekleri tanımlayacağız.
MapReduce, varsayılan yöntemi kullanıp kullanmadığınıza bakılmaksızın, varsayılan sıralama yöntemini kullanarak çıktıyı sıralamak için dizeleri karşılaştırır. Verilerin sıralanma şeklini değiştirmek için önce bir sıralama algoritması oluşturmanız ve ardından onu eşleyici sınıfını kullanarak uygulamanız gerekir.
SpiderMonkey, yaygın olarak kullanılan bir JavaScript motorudur. Küçük ölçekli uygulamalar için iyidir, ancak bazı sınırlamaları vardır. Örneğin, SpiderMonkey'in bir sıralama algoritması yoktur. Sonuç olarak, verileri sıralamak için Mapmapper kullanmak istiyorsanız, öncelikle kendi sıralama algoritmanızı oluşturmalı ve bunu Reduce sınıfında uygulamalısınız.
Popülaritesine rağmen SpiderMonkey bir sıralama algoritması kullanmaz. SpiderMonkey'in başka sınırlamaları da var ama bu dikkate değer. Örneğin SpiderMonkey iyi bir çöp toplayıcıya sahip değil, bu nedenle programınız yavaşlamaya başlarsa onu hızlandırmak için bazı önlemler almanız gerekebilir.
Neden Mapreduce İşlevi Kullanmalı?
Bir MapReduce işlevi , çeşitli durumlarda yararlı olabilir. Bu yöntem, bazı durumlarda toplu veri işleme için kullanılabilir. Tek bir uygulama veya işlem tarafından işlenecek büyük miktarda veriye ihtiyacınız varsa da kullanışlıdır. Bir MapReduce işlevi, dağıtılmış bir sistemde birden çok düğüme yayılmış verileri işlemek için de kullanılabilir. MapReduce işlevi kullanılarak, düğümlerden gelen veriler tek bir çıktıda birleştirilebilir. Bir MapReduce uygulaması genellikle büyük miktarda veriyi işlemek için kullanılır, ancak çok büyük miktarları işlemek için gerekli olabilir.
Adı Neden Mapreduce?
Neden MapReduce olarak adlandırıldığına dair birkaç teori var. Birincisi, harita indirgeme algoritmaları bir sorunu daha küçük parçalara ayırmayı (eşleme), ardından bu parçaları çözmeyi ve tekrar bir araya getirmeyi (azaltma) içerdiğinden, bunun bir kelime oyunu olmasıdır. Başka bir teori, bunun Google çalışanları tarafından 2004 yılında yazılan "MapReduce: Basitleştirilmiş Veri İşleme Büyük Kümelerde Basitleştirilmiş Veri İşleme" adlı bir makaleye atıfta bulunduğudur. Makalede yazarlar, önerilen işleme modelinin iki ana aşamasını tanımlamak için "harita" ve "azaltma" terimlerini kullanıyorlar.
Ancak, MapReduce modelinin yalnızca sınırlı olarak kullanıldığını not etmek önemlidir. Büyük veri kümeleri için uygun değildir ve düzgün çalışması için paralelleştirilmesi gerekir. Bu sorunların ele alınması söz konusu olduğunda, Apache Spark'ın MapReduce'a güçlü bir alternatifi vardır. Spark küme bilgi işlem sistemi, Hadoop tabanlıdır ve genel amaçlı bir bilgi işlem platformu olarak çalışır. Bu araç, veri madenciliği ve makine öğrenimi gibi geleneksel veri analizi görevlerinin yanı sıra veri ambarı ve büyük veri analizi gibi daha karmaşık veri işleme görevlerini hızlandırmak için kullanılabilir. Bu yazılım, hem ölçeklenebilir hem de hataya dayanıklı bir programlama dili olan Erlang kullanılarak oluşturulmuştur. Büyük miktarda veriyi işleyebilir ve aynı anda birden fazla makinede çalıştırılabilir. Ayrıca Spark, birden çok düğümün aynı görevi aynı anda gerçekleştirmesine izin vererek paralellik kullanır. Genel olarak, büyük ölçekli veri analizi görevlerini otomatikleştirme ve daha ölçeklenebilir hale getirme potansiyeline sahiptir. İşlemlerinizi paralel hale getirmeniz ve büyük veri kümelerini işlemeniz gerekiyorsa, MapReduce'a mükemmel bir alternatiftir.
Mapreduce Ve Toplama Arasındaki Fark Nedir?
Büyük Veri ile çalışırken, mapreduce büyük miktarda veriden veri çıkarmak için önemli bir yöntemdir. MongoDB 2.2, şu andan itibaren yeni toplama çerçevesini içeriyor. Toplama, işlevsellik açısından mapreduce'a benzer, ancak kağıt üzerinde daha hızlı görünüyor.
Bu senaryoda, MongoDB Aggregation ve MapReduce, Sharded kurulumundaki Docker kapsayıcılarında çalıştırılır. Toplayıcı boru hattı performansı, daha hızlı ve daha kolay gezinmeye izin verdiği için mapreduce'tan üstündür. Sorun şu şekilde işliyor: tweet, bir Twitter hashtag'inde "den", "denne", "denna", "det", "han", "hon" ve "hen" (büyük/küçük harfe duyarlı) gibi İsveççe zamirleri sayar. Bir kullanıcının kaç twitter tanıtıcısı vardır? 4 milyondan fazla tweet gönderildi. Bu deneyde öncelikle bir MongoDB veritabanı oluşturacağız ve sharding'i etkinleştireceğiz. Twitter akışları veritabanına aktarıldı ve MapReduce ve Aggregation Pipeline kullanılarak sorgular yürütüldü.
Mapreduce: Nihai Veri Toplama Aracı
Bir mapReduce programı , bir koleksiyondaki belgelerin bir listesini okur ve önceden tanımlanmış bir dizi işlevi kullanarak bunları işler. mapReduce işlemi, azaltma aşamasında işlenecek, işlemeye hazır belgelerden oluşan bir akış oluşturur. Mapsreduce ve toplamayı çeşitli durumlarda birleştirmek mümkündür. $group toplama operatörü, belgeleri tek bir alanda gruplandırmak için kullanılabilen bir araçtır. $merge toplama operatörü kullanılarak birden çok belge birleştirildiğinde, yeni bir belge oluşturulabilir. $accumulator toplama operatörü, birden çok harita küçültme işleminin sonuçlarını tek bir belgede göstermek için kullanılabilir.
Mongodb'da Mapreduce
Mongodb mapreduce , büyük veri kümeleri için bir veri işleme teknolojisidir. Verileri analiz etmek için güçlü bir araçtır ve verileri paralel ve dağıtılmış bir şekilde işlemek ve toplamak için bir yol sağlar. MapReduce, web trafiği analizi, günlük analizi ve sosyal ağ analizi dahil olmak üzere çeşitli alanlarda veri analizi için yaygın olarak kullanılmıştır.

mapReduce komutunu kullanırken, bir koleksiyonda map-reduce toplama işlemlerini çalıştırabilirsiniz. Harita işlevi, herhangi bir belgeyi sıfıra veya diğer birçok belgeye dönüştürebilir. 4.2'den önceki sürümlere kadar değişen MongoDB sürümlerinde, her bir yayın, maksimum BSON belge boyutunun yalnızca yarısını tutabilir. MapReduce'ta kullanılan kullanımdan kaldırılmış BSON türü JavaScript kodu artık desteklenmemektedir ve kod artık işlevleri için kullanılamaz. MongoDB 4.4 artık kullanımdan kaldırılan BSON türü JavaScript kodunu (BSON türü 15) içermemektedir. kapsam parametresi, azaltma işlevi tarafından hangi değişkenlere erişilmesine izin verildiğini belirtir. Girdileri azaltmak için MongoDB, BSON belge boyutunu maksimum boyutunun yarısı ile sınırlar.
Sunucuya iade edilen büyük belgeler iade edilebilir ve ardından sonraki indirimlerde birleştirilebilir, bu da potansiyel olarak gereksinimi karşılar. MongoDB 4.2 en son sürümdür. Bu seçenek, aynı koleksiyon adıyla yeni bir koleksiyon oluşturmak için harita küçültmenin yanı sıra yeni bir parçalı koleksiyon oluşturmak için kullanılabilir. Sonlandırma işlevi, bağımsız değişkenler olarak bir anahtar değeri ve azaltma işlevinden indirgenmiş değeri alır. out parametresini yapılandırmak için üç seçenek vardır. Bu seçenek, yeni bir koleksiyon oluşturmaya ek olarak, çoğaltma kümelerinin ikincil üyeleri üzerinde çalışmaz. NonAtomic: false seçeneği, yalnızca koleksiyon zaten mevcutsa ve açık belirtime sahipse sağlanabilir.
Küçültme işlevinin hem yeni hem de mevcut belgede kullanılması, yeni belgedeki tuşun mevcut belgedeki tuşla aynı olması sonucunu verir. CollectionName ayarlanmış var olan sabitlenmemiş bir koleksiyon olduğunda, bir harita azaltma çalışmaz. Bu durumda, nonAtomic doğruysa MongoDB'nin veritabanını kilitlemesi engellenir. Yalnızca bu seçeneği kullanan çoğaltma kümelerinin ikincil üyeleri kümenin dışında olabilir. Harita küçültme işlemini yeniden yazmak için özel işlevler gerekmez. cust_id, $group aşama grubunun değer alanını cust_id yöntemiyle hesaplamak için kullanılır. $merge aşaması, $merge aşamasının sonuçlarını mevcut toplama boru hattı işleçlerini kullanarak çıktı koleksiyonunda birleştirir.
Örnek olarak, agg_alternative_1 koleksiyonunun çıktısını yazmak için $out aşaması kullanılabilir. Her girdi belgesi, harita işleviyle işlenebilir. Siparişteki her kalem, siparişteki hem 1 sayısını hem de kalem miktarını içeren yeni bir nesne değeriyle ilişkilendirilir. azaltılmışVal'da, sayım alanı, dizi öğeleri tarafından oluşturulan sayım alanlarının toplamını temsil eder. Sonlandırma işlevi, azaltılmışVal nesnesini avg adlı bir hesaplanmış alanı içerecek şekilde değiştirirse, değiştirilen nesne kullanıcıya döndürülür. $unwind aşaması, items dizi alanını kullanarak belgeyi her bir dizi öğesi için bir belgeye böler. $project aşaması, iki alan -id ve value dahil ederek mapreduce'un çıktısını yansıtmak için çıktı belgesini yeniden şekillendirir.
Yeni sonuçla aynı anahtara sahip mevcut bir belge yoksa mevcut belgenin üzerine yazar. out parametresini belirtirseniz, sonuçları bir koleksiyona yazmak istiyorsanız, mapReduce aşağıdaki biçimde bir belgeyi çıktı olarak döndürür. Çıktı satır içinde yazılırsa, sonuçta ortaya çıkan belgeler dizisi döndürülür. Her belge iki alan içerir: kaynak belgenin adı ve alıcı belgenin adı. -id alanına anahtar değeri girildiğinde, anahtar için azaltılmış veya kesinleştirilmiş değerler için bir değer alanı oluşturulur.
Mongodb'da Emit Nedir?
Bir harita işlevi olarak, harita işlevi, anahtarı ve değeri içeren bir çıktı belgesi oluşturmak için herhangi bir zamanda yayıcıları (anahtar, değer) çağırabilir. MongoDB 4.2 ve önceki sürümlerdeki tek bir yayın, MongoDB'nin BSON dosyalarının maksimum boyutunun yalnızca yarısını tutabilir. MongoDB'nin 4.4 sürümünden itibaren kısıtlama kaldırılmıştır.
Mongodb, Esnek ve Ölçeklenebilir Veriler İçin Neden En İyi Seçimdir?
Katı bir şemaya sahip olmaması nedeniyle, MongoDB sıklıkla NoSQL ile ilişkilendirilir. Katı bir şema içermemesi nedeniyle veriler, uygulama için uygun olan herhangi bir formatta saklanabilir. Veritabanının esnekliği, verilerin uygulamanın ihtiyaçlarına göre uyarlanmış bir şekilde depolanabileceği anlamına geldiğinden, ölçeği yukarı veya aşağı ölçeklendirirken önemli bir avantaj sağlar.
Çeşitli veri parçaları arasındaki ilişkileri görselleştirmek için ER diyagramları içeren bir veri diyagramı kullanılabilir. ER diyagramı, bir veri koleksiyonunu temsil eden bir dizi düğümü tasvir eder ve aralarındaki bağlantılar bir tanımlayıcı görevi görür.
İlişkisel bir veritabanı olmadığı için MongoDB'de ilişkiler zorunlu değildir. ER diyagramı, veriler içinde var olan ilişkileri gösterir ve ayrıca bunların görselleştirilmesine yardımcı olur.
MongoDB, esnek ve ölçeklenebilir veriler için mükemmel bir seçimdir. Esnekliği, verileri bir uygulama için anlamlı olacak şekilde depolamasına olanak tanır ve ölçeklenebilirliği, büyük veri kümelerini hızlı ve kolay bir şekilde işlemesine olanak tanır.
Map-reduce Mongodb Örneği
MongoDB'de map-reduce, koleksiyonlardan veri toplamak için bir veri işleme paradigmasıdır. İşlevsel programlamadaki harita ve azaltma işlevlerine benzer.
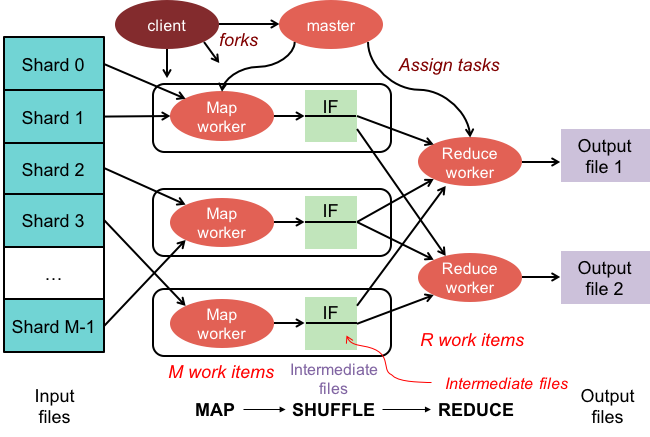
Harita küçültme işlemlerinin iki aşaması vardır:
1. Harita aşaması, koleksiyondaki her belgeye bir haritalama işlevi uygular. Eşleme işlevi, her girdi belgesi için bir veya daha fazla nesne yayar.
2. İndirgeme aşaması, harita aşaması tarafından yayınlanan belgelere bir azaltma işlevi uygular. Azaltma işlevi, nesneleri toplar ve çıktı olarak tek bir nesne üretir.
Örneğin, bir makale koleksiyonunu düşünün. Her makaledeki kelime sayısını hesaplamak için harita azaltmayı kullanabiliriz.
İlk olarak, anahtarın makale kimliği ve değerin makaledeki kelime sayısı olduğu, her belge için bir anahtar/değer çifti yayan bir eşleme işlevi tanımlarız.
Ardından, her anahtarın değerlerini toplayan bir azaltma işlevi tanımlarız.
Son olarak koleksiyon üzerinde map-reduce işlemini gerçekleştiriyoruz. Sonuç, birleştirilmiş verileri içeren bir belgedir.
Mongosh'ta bir veritabanı var. mapReduce() yöntemi, mapReduce komutunu çevreleyen bir sarmalayıcıdır. Bu bölümde, özel bir toplama ifadesi olmayan bir toplama boru hattı alternatifi gibi çeşitli örnekler verilmiştir. Map-Reduce to Aggregation Pipeline Çeviri Örnekleri kullanılarak haritalar özel ifadelerle çevrilebilir. Harita küçültme işlemi, mevcut toplama işlem hattı işleçlerini kullanarak özel işlevleri tanımlamaya gerek kalmadan değiştirilebilir. Harita işlevi, girdideki her belgeyi işlemek için kullanılabilir. Her öğenin, 1 sayısını, sipariş için adet numarasını ve bir kalem listesini içeren yeni bir değerle ilişkili kendi nesne değeri vardır.
Geçerli belgedeki anahtar yeni belgedeki anahtarla aynıysa, işlem bu belgenin üzerine yazar. Harita küçültme işlemini, özel işlevleri tanımlamak yerine toplama işlem hattı işleçlerini kullanarak yeniden yazabilirsiniz. $unwind aşaması, belgeyi öğeler dizisi alanına göre ayırır ve her dizi öğesi için bir belgeyle sonuçlanır. $project aşaması çıktı belgesini yeniden şekillendirdiğinde, map-reduce çıktısı yansıtılır. Bir işlem, yeni sonuçla aynı anahtara sahip mevcut bir belgenin üzerine yazar.
Hadoop'ta Eşleyici İşlevi Nedir?
İndirgeyici olarak, birleşik bir yanıt oluşturmak için haritalayıcılardan gelen verileri birleştirmelisiniz. Azaltılmış çıktı, her biri oluşturulan sonucun bir alt kümesini temsil eden bir dizi harita çıktısı girdi olarak kabul edildiğinde üretilir.
Haritalayıcılar, verileri yönetilebilir parçalara bölmek ve ardından her parçayı boyutuna göre bir göreve atamak için kullanılır. Girdi verileri, gerçekleştirilecek görevi gösteren parametrelerin bulunduğu eşleyici işlevi tarafından alınır.
Bir dizi öğe, çıktıda eşleyici tarafından eşlenen veri yığınlarına karşılık gelir. Sonuç olarak, harita çıktısı, indirgeme çıktısına dönüştüren indirgeyiciye iletilir.
Hatalar ayrıca eşleştirici işlevi tarafından işlenir. Bu durumda bir eşleyici, bir harita çıktısı olmayan bir hata çıktısı döndürür. İndirgeyici bu verileri işleyemediği için, eşleştirici bir hata mesajı döndürür.
Hadoop Ekosistemi
Hadoop ekosistemi, büyük verileri işlemek ve depolamak için bir platformdur. Her biri verilerin işlenmesinde ve depolanmasında belirli bir role sahip olan bir dizi bileşenden oluşur. Ekosistemin en önemli bileşenleri, Hadoop Dağıtılmış Dosya Sistemi (HDFS), MapReduce çerçevesi ve Hadoop Ortak kitaplığıdır .