
NoSQL Veritabanı: Impala
Yayınlanan: 2023-03-03NoSQL, geleneksel, ilişkisel veritabanı yapısını kullanmayan bir veritabanını tanımlamak için kullanılan bir terimdir. Bunun yerine, NoSQL veritabanları genellikle daha basit, daha ölçeklenebilir bir çözüm sağlamak için tasarlanır.
Impala, büyük veri kümelerini yönetmek için hızlı, ölçeklenebilir bir çözüm sağlamak üzere tasarlanmış bir NoSQL veritabanıdır. Impala, Google Bigtable veri modelini temel alır ve sütunlu bir depolama biçimi kullanır. Impala, açık kaynaklı bir proje olarak mevcuttur ve Cloudera tarafından desteklenir.
Apache Impala, bir Hadoop kümesine yüklenen ve sistemde depolanan veriler için büyük paralel işleme (MPP) gerçekleştiren açık kaynaklı bir SQL sorgu motorudur. İlk olarak 2012'de geliştirilen açık kaynaklı proje "Microsoft Formula 1" olarak biliniyor.
Impala platformu, kullanıcıların verileri taşımak veya dönüştürmek zorunda kalmadan HDFS ve Apache HBase'de depolanan Hadoop verilerine yönelik düşük gecikmeli SQL sorguları gerçekleştirmesini sağlar.
Impala Sql Tabanlı mı?
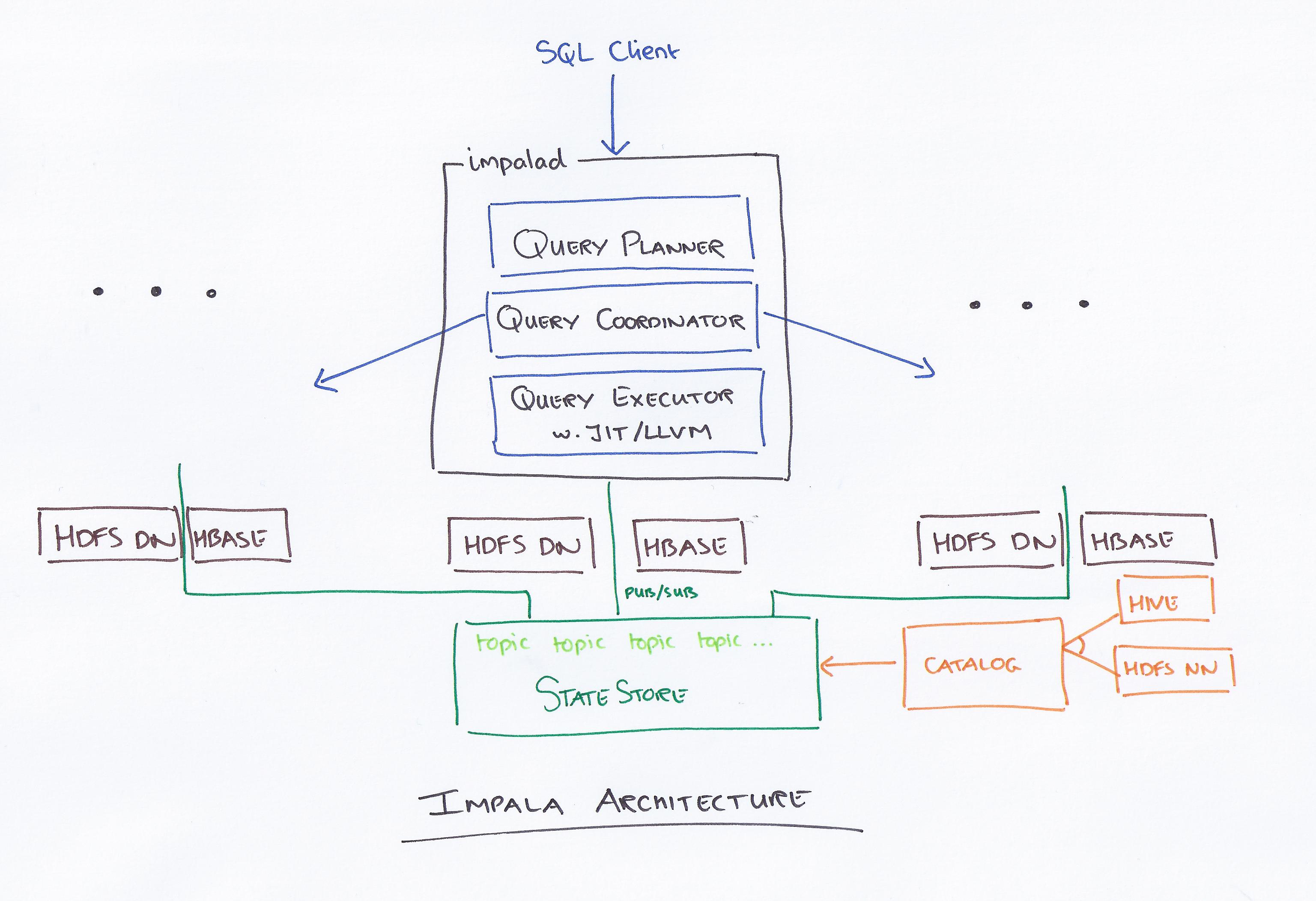
Impala, Apache Hadoop üzerinde çalışan SQL tabanlı bir sorgu motorudur. Kullanıcıların SQL kullanarak HDFS ve HBase'de depolanan verileri sorgulamasına olanak tanır. Impala, Hive ve Pig gibi diğer Hadoop sorgulama motorlarına kıyasla yüksek performans ve düşük gecikme sağlar.
Impala analitik MPP veritabanı, sektördeki en hızlı içgörü süresini sağlar. CDH ile entegredir ve Cloudera Enterprise aracılığıyla erişilebilir. Impala gibi Apache Hadoop için MPP veritabanları, daha hızlı içgörü elde etme süresi sağlamak için HDFS'yi kullanır.
Impala Bir Veritabanıdır
inandığım bir veri tabanıdır.
Impala Bir Etl Aracı mı?
Impala bir ETL aracı değil, veriler bir işlemle temizlendikten sonra SQL sorguları yapmak için kullanılabilen bir SQL sorgu motorudur.
Apache Impala Ne İçin Kullanılır?
SQL benzeri sorgular kullanarak, Impala kullanarak çeşitli kaynaklardan veri okuyabiliriz. Apache Impala , Hadoop Dağıtılmış Dosya Sisteminde depolanan verilere erişim söz konusu olduğunda, Hive ve diğer SQL motorlarından daha iyi performans gösterir. Verileri Hadoop HBase, HDFS ve Amazon S3'te depolamak için Impala kullanıyoruz.
Teknoloji Yığınlarında Apache Impala Kullanan 19 Şirket
Apache Impala, çeşitli büyük işletmeler için popüler bir veri işleme motorudur . Raporlara göre aralarında Stripe, Agoda ve Expedia.com'un da bulunduğu 19 teknoloji şirketi Apache Impala kullanıyor. Impala platformu, esnek ve verimli olup, büyük veri kümelerini hızlı ve etkili bir şekilde işleme yeteneğine sahiptir. Bu aracın yaygın kullanımı, ne kadar yararlı olduğunu ve veri işlemede ne kadar yararlı olduğunu göstermektedir.
Sql Hive Ve Impala Arasındaki Farklar Nelerdir?
Hive'ın amacı, birden çok dönüştürme ve birleştirme gerektiren uzun süredir devam eden sorguları işlemektir. Düşük gecikme süresi ve daha küçük sorguları işleme yeteneği nedeniyle, Impala sorgu işleme motoru etkileşimli bilgi işlem için idealdir. Spark, kısa ve uzun vadeli sorgulara ek olarak hem kısa hem de uzun vadeli sorguları destekler.
Hive Uzun Süren Toplu İşler İçin Daha Uygundur
Araçların birincil amacı partileri işlemek değildir. Hive, daha küçük veri kümelerini işleyebilen Impulsa'dan daha uzun süreli toplu iş için daha uygundur.
Impala Bir Veritabanı mı
Bir impala, verileri sütun biçiminde depolayan bir veritabanıdır. Ölçeklenebilir olacak ve büyük veri kümeleri için yüksek performans sağlayacak şekilde tasarlanmıştır.
Impala'nın ilk sürümünde, aşağıdaki temel sütun veri türleri desteklenir: sayı yerine STRING, VARCHAR, VARCHar2, INT ve FLOAT ve hiçbir BLOB türü desteklenmez. Impala SQL-92, bazı SQL standartları standart geliştirmeleri içerir, ancak hepsini içermez. Veriler tek bir sunucuda üretilemeyecek, değiştirilemeyecek ve analiz edilemeyecek kadar büyük olduğunda, Impala diğer veri ambarlarından daha iyi performans gösterir ve daha fazla ölçeklenebilirlik sağlar. Hafif olduğu için Impala'yı yüklerken veri dosyalarının orijinal konumunu kaldırmaya gerek yoktur. Performans testi, ölçeklenebilirlik ve çok düğümlü küme yapılandırmaları hakkında bilgi edinmenin ilk adımı genellikle çok büyük miktarda veri toplamaktır. Cloudera Impala, büyük veri kümelerinde veri yükleme ve toplu okuma için optimize edilmiştir ve daha azıyla daha fazlasını yapmanızı sağlar. HDFS'nin multimegabayt blok boyutu, Impala'nın çok büyük miktarlardaki verileri ağa bağlı birden çok sunucuda paralel olarak işlemesine olanak tanır.
Normalleştirilmiş dizinler ve bunları oluşturmak için gereken zaman ve çabayı planlamak yerine, bunu Impala'da yapacaksınız. Impala'nın sorgu motoru, veri ambarlarından gelen büyük miktarda veriyi işleyebilir. Bir kümeyi analiz eder ve tüketilen kaynak miktarını azaltmak için görevleri düğümler arasında dağıtır. Bir veri ambarının bölümlenmesi, Impala'da tanıdık bir kavramdır. Bölümleme, disk G/Ç'yi azaltır ve Impala'da sorgu ölçeklenebilirliğini artırır. Impala'da yerleşik tablolara erişemeyeceğiniz için veri dosyaları gereklidir. INSERT mevcut seçeneklerden biridir.
İki oyuncak tablosu oluşturmak için bir değer ifadesi kullanın. Toplu iş odaklı yazılım kullanıyorsanız, bunu deneyebilirsiniz. Hadoop üzerinde SQL teknolojisini Apache Hive yapılandırmanıza dahil edebilirsiniz. Impala'daki Hive tabloları yüklenmez veya zaman alıcı bir şekilde dönüştürülmez.
Impala: Hadoop İçin Güçlü Bir Veri Yönetim Aracı
SQL sözdizimi, HDFS ve Apache HBase'de depolanan verileri sorgulayabilen Impala kullanıcıları için tanıdıktır. Bu sayede geleneksel ilişkisel veritabanları yerine Hadoop ve Impulsa kullanılabilir. Ayrıca sahip olduğu özellikler sayesinde güçlü bir veri yönetim aracıdır. Ayrıca, büyük veri kümeleri için yetenekleri etkileyicidir ve bunları büyük bir kolaylıkla işleyebilir.
Büyük Veride Impala
Impala, Apache Hadoop üzerinde çalışan açık kaynaklı bir MPP SQL sorgu motorudur. HDFS ve HBase'de depolanan veriler üzerinde hızlı, etkileşimli SQL sorguları sağlar. Impala, HDFS ve HBase'de depolanan veriler için hızlı, etkileşimli bir SQL arabirimi sağlayarak Apache Hadoop'un performansını artırmak üzere tasarlanmıştır.

Cloudera liderliğindeki Impala, yeni bir sorgulama sistemidir. Hadoop, HDFS ve HBase'e sahiptir, dolayısıyla burada depolanan PB düzeyindeki büyük verileri sorgulayabilir. Bu teknoloji, veri ambarını dikkate almanın yanı sıra hesaplama için kovan ve belleğe dayalıdır ve gerçek zamanlı toplu işleme ve çoklu eşzamanlı işleme sağlar. Bir istemci, sonraki istemci işlemleri için bir sorgu kimliğinin döndürüldüğü bir impalad ağındaki bir düğüme bir sorgu isteği gönderir. Çözümleyicinin oluşturma sürecinin ilk adımında, tek başına bir yürütme planı (tek makine planı, dağıtılmış yürütme planı) oluşturulur ve birleştirme sırası değişiklikleri, yüklem indirmeleri vb. gibi SQL de yürütülür. Tüm düğümler, döngünün dışında kalmamanızı sağlamak için en son meta veri bilgilerinin bir kopyasını tutar. Hadoop, Hive veya Impurbia'yı kullanmadan önce gerekli veri işleme yazılımını yüklemeniz gerekir.
Impala'nın yapılandırma dosyası değiştirilebilir. Her düğüm, Impala'da bir yapılandırma değişikliği gerçekleştirir. MySQL sürücü paketini bir veritabanına bağlamaktan tüm düğümler sorumludur. Düğümler, Bigtop'un Java yolunu değiştirir.
Hive Ve Impala Karşılaştırması
Bu üç ana farka ek olarak birkaç küçük fark daha var. Hive'da HiveQL'nin bir alt kümesi bulunurken, Örtülü'de HiveQL'nin bir alt kümesi vardır. Hive ve Impala, sırasıyla veri ambarı ve etkileşimli sorgulama için kullanılır. Hive, Impala'nın aksine etkileşimli bilgi işlem için tasarlanmamıştır.
Hadoop'ta Impala Nedir?
Impala, bir Hadoop kümesinde depolanan veriler için açık kaynaklı bir SQL sorgu motorudur. HDFS, HBase veya diğer herhangi bir Hadoop veri kaynağında depolanan veriler üzerinde hızlı, etkileşimli SQL sorguları sağlamak üzere tasarlanmıştır.
Impala, çok çeşitli tanıdık Hadoop bileşenlerini kullanır. INSERT, yalnızca Impala'nın okuyabileceği türden verileri yazabilirken, SELECT, Impala'nın okuyabileceği türden verileri okuyabilir. Bir Avro, RCFile veya SequenceFile dosya biçimi kullanılırken, veriler Hive'a yüklenir. Tablo ve sütun istatistiklerine ek olarak tablo istatistikleri ve sütun istatistikleri de kullanılabilir. Tüm DDL ve DML ifadeleri, kataloglanmış arka plan programı aracılığıyla gönderildikleri takdirde, Impala 1.2 ve sonraki sürümlerde kataloglanmış arka plan programı kullanılarak otomatik olarak güncellenir. INVALIDATE METADATA yöntemi, erişilen meta deposundaki tüm tablolar için meta verileri döndürür. Veri dosyaları, yeni bir tablo için dizinlerde saklanır ve Impala çalışırken dosya adından bağımsız olarak okunur.
Genel olarak, Apache Hive bir veri ambarı platformu olarak iyi performans gösterirken, Impala paralel işleme için daha uygundur. Hive hataya dayanıklıdır, oysa Impulsa değildir.
Apaçi Impala
Apache Impala, Apache Hadoop için hızlı, etkileşimli bir SQL sorgu motorudur. Kullanıcıların, veri taşıma veya dönüştürme gerektirmeden HDFS ve Apache HBase'de depolanan verilere düşük gecikmeli SQL sorguları vermesini sağlar.
Impala'nın mimari konsepti, HDFS kullanarak etkileşimli sorguları diğer tüm sorgu motorlarından daha verimli bir şekilde işlemesini sağlar. Hive, disk G/Ç işlemleri nedeniyle çok daha yavaştır, ancak Apache tamamen farklı bir motor olduğu için çok daha hızlıdır. Impulsa ve Presto arasında bir fark yoktur çünkü Impulsa çok daha hızlı bir teknoloji kullanır ve Presto da benzer bir mimari kullanır. Parke eğeleri söz konusu olduğunda, Impala en iyi performansı gösterir. Analistlerinizin sorgularına göre hangi verileri bölümlere ayırmanız gerektiğini belirleyin. Compute Stats Statistics ile sorgularınız, özellikle birden fazla tablo (birleştirme) içeriyorsa, çok daha kolay olacaktır. Haftada dört kez bir Impala katalog sunucusu çökmesi yaşadık ve sorgularımızın tamamlanması çok uzun sürdü.
Ayrıca, oluşturduğumuz dosya miktarı, sorgu performansımızı büyük ölçüde etkiler. Sonuç olarak, bölümlerimizi yönetmeye ve onları yaklaşık 256 MB'lık en uygun dosya boyutunda birleştirmeye başladık. Her bölümün yalnızca bir dosyası olduğu belirtilir (boyutu > 256MB olmadığı sürece). Implicit tarafından desteklenen tüm veri türleri arasından en uygun sütun türü seçilmelidir. Bir kullanıcı tarafından erişilen eşzamanlı sorguların veya Y belleğinin sayısını sınırlamak için Impala Kabul Denetimini kullanın. Bir sorgu 30 dakikadan uzun sürerse, ölü kabul edilir.
Büyük Veri İçin En İyi Motor: Impala
Impala motoru, büyük kümeler için özel olarak tasarlanmış bir Hadoop veri işleme motorudur . Hadoop'un standart MapReduce motorundan çok daha az enerji kullanır ve çok daha az kaynak tüketir. Örtük, birincil veri depolama ortamı olarak dağıtılmış dosya sistemi HDFS'yi kullanır ve düğümden düğüme donanım veya ağ kesintilerini önlemek için HDFS'nin yedekliliğine güvenir. Tablo verilerini temsil eden veri dosyaları, fiziksel olarak bilinen HDFS dosya formatları ve sıkıştırma codec'leri tarafından temsil edilir.
Paralel İşleme Sorgu Motoru
Paralel işleme sorgu motoru, sorguları paralel olarak işlemek için tasarlanmış bir tür veritabanı motorudur. Bu, birden çok işlemci, birden çok çekirdek veya birden çok makine kullanılarak yapılabilir. Paralel işleme, özellikle karmaşık sorgular için bir sorgu motorunun performansını büyük ölçüde artırabilir.
Çok işlemcili bir bilgisayar, karmaşık sorguları aynı anda yürütülebilen yürütme planlarına dönüştürmek için kullanılır ve büyük miktarda veriyi aynı anda işlemesine olanak tanır. Yüksek performans için iyi sorgu yanıt süresi veya yüksek sorgu verimi gibi verimli bir yürütme gereklidir. Verimli paralel yürütme teknikleri ve sorgu optimizasyonu kullanılarak gerçekleştirilir.
Paralel İşleme: Etl'nin Geleceği?
Üst düzey bir sorgu, paralel sorgu işleme kullanan çok işlemcili bir bilgisayar tarafından verimli bir şekilde yürütülebilen bir yürütme planına dönüştürülebilir. Paralel işleme, paralel ve dağıtılmış verileri birleştirme tekniğinin yanı sıra paralel veritabanı sistemi tarafından sağlanan çeşitli yürütme tekniklerini kullanır. Paralel sorgu işleme, ETL'de, aktarım için atanan her kaynak tablodaki kayıt kümesini aynı boyuttaki parçalara bölerek ve ardından her bir kaynak tablo için veri dönüştürme işlemini bir döngüde gerçekleştirerek, verileri ardışık olarak, yığın parça seçerek uygulanır. .