
NoSQL Veritabanları: Geleneksel İlişkisel Veritabanlarına Bir Alternatif
Yayınlanan: 2023-01-13NoSQL veritabanları, geleneksel ilişkisel veritabanlarına bir alternatif olarak giderek daha popüler hale geliyor. Bir NoSQL veritabanı, sabit bir şema gerektirmez ve ölçeklenmesi kolaydır. Sıra, bir NoSQL veri deposu türüdür. Sıra, verileri ilk giren ilk çıkar (FIFO) tarzında depolayan bir veri yapısıdır. Bir sıra genellikle, tamamlanması gereken görevlerin listesi gibi sıralı bir sırada işlenmesi gereken verileri depolamak için kullanılır. Kuyruk, sabit bir şema gerektirmediği için bir NoSQL veri deposu türüdür. Görev sayısı arttıkça bir sıra kolayca ölçeklendirilebilir.
Mesaj kuyruğu olarak MongoDB veya RavenDB kullanacaksam hangisini tercih ederim? Mesaj nesnesi, istemci aracılığıyla bir web servisine gönderilebilir ve ardından web servisi tarafından alınabilir. İşi yapan servis, ortaya çıkabilecek herhangi bir kritere göre bir mesaj tipi seçebilir. İşleri hızlandırmak için senaryolara dayalı dizinler oluşturabilirim. Yalnızca bir sıra oluşturuyorsanız, NoSQL'i bundan daha fazlası için düşünmemelisiniz. Hangi uygulamayı kullanmak istediğinize karar verirseniz, büyük olasılıkla performans, güvenilirlik ve verimlilik üzerinde daha büyük bir etkiye sahip olacaktır.
NoSQL veritabanları (SQL olarak da bilinir), tablolu olmamanın yanı sıra verileri ilişkisel veritabanlarından farklı şekilde depolar. Bir NoSQL veritabanı, veri modeline bağlı olarak çeşitli farklı türlerde olabilir. Belge türleri, anahtar/değer türleri, geniş sütun türleri ve grafikler en sık kullanılanlardır.
Datastore, çok çeşitli uygulamaları destekleyen yüksek düzeyde ölçeklenebilir bir NoSQL veritabanıdır. Sonuç olarak Datastore, parçalama ve replikasyonu otomatik olarak yöneterek, uygulamalarınızın yükünü kaldıracak şekilde otomatik olarak ölçeklenen, yüksek düzeyde kullanılabilir ve dayanıklı bir veritabanı kullanmanıza olanak tanır.
Nosql Veri Deposu Hangisidir?
Her biri kendi güçlü ve zayıf yönleri olan birçok farklı NoSQL veri deposu türü vardır. En popüler NoSQL veri depoları MongoDB, Cassandra ve HBase'dir.
Belge tabanlı NoSQL veritabanları, verileri ilişkisel veritabanlarından daha verimli bir şekilde depolar. Uyarlanabilir, ölçeklenebilir ve veri yönetimi için iş gereksinimlerine hızlı bir şekilde yanıt verebilecek kapasitede olmaları amaçlanmıştır. Genel olarak NoSQL olarak adlandırılan veritabanı türleri, saf belge veritabanlarını, anahtar-değer depolarını, geniş sütunlu veritabanlarını ve grafik veritabanlarını içerir. Küresel 2000 işletmeleri, görev açısından kritik uygulamaları desteklemek için hızla NoSQL veritabanlarını benimsiyor. Bunun nedeni, çoğu ilişkisel veritabanının kullanımını zorlaştıran teknik zorluklar sunan beş eğilimdir. Veritabanı yönetimi, çevik geliştirme için gerekli olan sabit veri modelini destekleme yeteneğinden yoksun oldukları için çevik geliştirme için büyük bir engeldir. Uygulama modeli, NoSQL'deki veri modelini tanımlar.
NoSQL'de verileri modellemek statik değildir. JSON formatı, verileri belge yönelimli bir veritabanında depolamak için varsayılan formattır. Bu, ORM çerçevelerine olan ihtiyacı ortadan kaldırır ve geliştirme sürecini iyileştirir. SQL'i JSON'a genişleten güçlü bir sorgulama dili olan N1QL (telaffuz nikel), Couchbase Server 4.0'ın bir parçası olarak yayınlandı. Ayrıca, standart SELECT / FROM / WHERE deyimlerinin yanı sıra toplama (GROUP BY), sıralama (SORT BY), birleştirmeler (LEFT OUTER / INNER) ve diğerleri için destek içerir. Genişletilebilir mimarisi ve tek bir hata noktası olmaması nedeniyle, NoSQL dağıtılmış veritabanları zorlayıcı operasyonel avantajlara sahiptir. Daha fazla müşteri çevrimiçi olarak ve mobil uygulamalar aracılığıyla şirketlerle etkileşime girdikçe, kullanılabilirlik önemli bir sorun haline geliyor.
NoSQL veritabanlarının kurulumu, yapılandırılması ve ölçeklenmesi kolaydır. Dağıtılmış okuma, yazma ve depolama özellikleriyle, okumayı, yazmayı ve depolamayı basit hale getirmek için tasarlandılar. Farklı boyutlardaki kümeleri yöneten ve izleyenler de dahil olmak üzere çok çeşitli ölçeklerde çalışabilirler. Veri merkezleri arasında eşleme yapmak için yazılım geliştirmeye gerek yoktur; dağıtılmış bir NoSQL veritabanı, veri merkezleri arasında yerleşik çoğaltma içerir. Ayrıca, veritabanının bir sorunu algılamasını ve veritabanı tabanlı bir kurtarma işlemi gerçekleştirmesini beklemek yerine uygulamaların kendi yük devretmelerini gerçekleştirmelerine olanak tanır. NoSQL veritabanları, kullanım kolaylığı ve entegrasyon kolaylığı nedeniyle web, mobil ve IoT uygulamalarında giderek daha fazla kullanılmaktadır.
Tablo depolama, ilişkisel bir veritabanında depolanmayan veriler için mükemmel bir çözümdür. Tablo depolama, verileri uygulamanızın büyümesini karşılayacak kadar esnek bir kapsayıcıda depolamanıza olanak tanır. Video veya görüntü verileri gibi ilişkisel bir modelde depolanması zor olan verileri depolamak için bir tablo depolama sistemi kullanılabilir.
Azure'ın Nosql Veritabanları: Documentdb, Graph ve Keyvalue
Azure'daki üç NoSQL veritabanı türü Azure DocumentDB, Azure Graph ve Azure KeyValue'dur. Azure DocumentDB ile sunucudaki veri dosyalarını yönetmeye veya arşivlerden almaya gerek yoktur; sunucusuzdur, anahtar-değer çiftidir ve saniyede bir milyona kadar isteği işleyebilir. Bu, bir uygulamadaki birden çok katmandaki verileri sorgulamak ve yönetmek için kullanılabilen bir grafik veritabanıdır. Azure Graph, bir uygulamadaki birden çok katmandaki verileri sorgulamak ve yönetmek için kullanılabilen bir grafik veritabanıdır. Azure KeyValue'nun sıralanmış ve filtrelenmiş listelerindeki verileri düzenlemenizi ve filtrelemenizi sağlar.
Sıra Veritabanı mı?
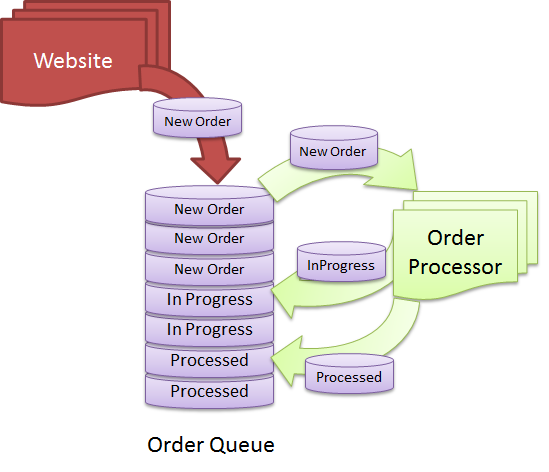
Bir veritabanını nasıl tanımladığınıza bağlı olduğundan, bu sorunun kesin bir yanıtı yoktur. Genel olarak, bir veritabanı, gerektiğinde erişilebilmesi ve güncellenebilmesi için belirli bir şekilde düzenlenmiş bir veri topluluğudur. Sıra, verileri belirli bir sırada depolamanıza ve almanıza olanak tanıyan bir veri yapısıdır. Dolayısıyla, kuyruğu bir veri koleksiyonu olarak düşünürseniz, o zaman bir veritabanı olarak kabul edilebilir. Bununla birlikte, bir veritabanını yalnızca erişilebilen ve güncellenebilen bir veri koleksiyonu olarak kabul ederseniz, o zaman sıra bir veritabanı olarak kabul edilmez.
Kuyruğa dayalı bir sistem için veritabanı kullanmanın doğru zamanı ne zaman? Tüm isteklerin mümkün olan en kısa sürede işlenmesi için düzenli ve düzenli bir kuyruğun sürdürülmesi çok önemlidir. Bu tür durumların üstesinden gelmek için tasarlanmış bir ileti kuyruğu vardır, bu da iletilerin kuyruğundan çıkarılmasını veya kuyruğa alınmasını kolaylaştırır. Veritabanınızda herhangi bir zamanda yüzlerce PDF oluşturma isteğiniz olduğunu hayal edin. Saniyede daha fazla talebi sürekli olarak işleyebilmek arzu edilir. Çözümünüzü ölçeklendirebileceğiniz için daha fazla çalışan (istekleri işleyen süreçler) bağlamanıza gerek yoktur. İsteği almak için çalışanın ek bir bilgi sağlaması gerekecektir.
İleti kuyrukları , iletilerin saklanmasını ve işlenmesini sağlamak için kullanıcının herhangi bir işlem gerçekleştirmesini gerektirmez. Mesajları bir veritabanından manuel olarak yoklamak yerine, mesaj kuyrukları gerçek zamanlı olarak gönderilir. Çok fazla bağlantıya bağlanırken veya çok fazla CPU gerektiren diğer görevleri gerçekleştirirken CPU gücünüz biterse, mesaj kuyruğu sunucunuzu çalıştırmak için daha fazla CPU gücü kullanabilirsiniz. Çok sayıda asenkron mesajın gerekli olduğu durumlarda, bir mesaj kuyruğu şiddetle tavsiye edilir. Bir işçi bir görevi yerine getirirken ölürse, istek çözülene kadar kuyrukta tutulmalıdır. Bir mesaj alındığında ve işlendiğinde, bir işçi ilerlemeyi bildirmek için mesaj kuyruğuna geri bir onay gönderir.

Sıra, bir öğe koleksiyonunu mantıksal bir sırada depolayabilen bir veri yapısıdır. Bir kuyruğa yerleştirilen öğeler, kuyruğa eklendikten sonra mümkün olan en kısa sürede işlenir. Öğeleri belirli bir sırayla işlemek istediğinizde bir kuyruk yararlı olabilir. SELECT deyimi, bir kuyruğun içeriğini değiştirmek için kullanılabilen bir yöntemdir. SELECT deyimi, bir kuyruktan öğeleri seçmenize ve isterseniz başka bir konuma göndermenize izin veren bir yöntemdir. SELECT deyimi, öğeleri başka bir konumdan uygun bir kuyruğa göndermek ve bunları bir kuyruğa eklemek için de kullanılır. INSERT, UPDATE, DELETE veya TRUNCATE deyimi bir sırayı hedeflemeye çalışamaz. Öğeleri belirli bir sırayla işlemeniz gerekiyorsa, bir kuyruk kullanışlıdır; ancak kuyruktaki öğeleri değiştirmemelisiniz.
Veritabanı Sistemlerinde Kuyruk Sistemlerinin Önemi
Sıra mekanizmalarına sahip bir veritabanı, herhangi bir veri merkezine mükemmel bir ektir. Çeşitli amaçlar için kullanılabildikleri için kuyruk sistemleri için DBMS işlevselliğine sahip olmak çok önemlidir. Sıra işlevselliğini standart bir veritabanı sistemine entegre ederek, diğer uygulamalar bunlara daha fazla erişim sağlayabilir. Bu güncelleme ile kuyruk sistemleri daha güçlü ve çok yönlü hale geldi ve kullanışlılıkları ve potansiyelleri artırıldı.
Mongodb'un Sırası Var mı?
Sıra, bir MongoDB veritabanına, belgenin oluşturma verilerine veya belirli bir önceliğe göre belgelerin sıralamasına dayalı olarak artan bir sırada eklenen bir belgeler koleksiyonudur.
Halihazırda MongoDB kullanıyorsanız, güzel bir API ile kuyruklar oluşturmak için bu yöntemi kullanabilirsiniz. Bir MongoDB v3 sürücünüz veya daha eski bir veritabanınız varsa, mongodb- [e-posta korumalı] seçeneği önerilir. Bu paket, özellik eksiksiz ve kararlı olarak sınıflandırılır. Yaygın kullanımına rağmen, onunla ilgili çok az yeni gelişme var. Herhangi bir sorun yaşarsanız veya yanlış kullanırsanız lütfen bize bildirin. Oluşturduğunuz her sıra kendi kuyruğu olacaktır. Resizing-image-queue veya notify-owner-queue adlı bir MongoDB koleksiyonu oluşturulabilir ve her ikisi de kullanılabilir.
Bir mesajı aldıktan sonra 30 saniye içinde almazsanız, alınabilmesi için tekrar kuyruğa alınır. Herhangi bir ölü mesajın bulunup bulunmadığını görmek için ölü kuyruğunuzu yoklayın. Tüm iletileri orijinal kuyruktaki ölü kuyruğa when.get() döndürdüğümüzde, ölü kuyruğun yükü mesajdır. Bir öğe sıradan çıkarılırsa ancak onaylanmazsa, bir sonraki ayrılma girişiminde bu ölü kuyruğa taşınacaktır. Bir öğe sıradan çıkarılırsa ancak onaylanmazsa, bir sonraki ayrılma girişiminde bu ölü kuyruğa taşınacaktır. Sıra, hayatta olduğunuzu söylemek için bir mesaja ping atarak ve isteği işleyerek görüntülenebilir. Ping işleminde geçirdiğiniz görünürlük süresi, // görünürlük süresi yöntemiyle de belirlenir (bu durumda, bu sıra %d mesaj gördü%d mesaj%d sayar; ); // tail.ping(msg.ack, (err, id) = Mevcut mesajların yanı sıra son 24 saat içinde kuyrukta olan mesajların sayısı.
Alınan ancak henüz etkinleştirilmemiş yeni mesajların sayısını hesaplayabiliriz. up.size() +.inFlight() +.done() eklerseniz get.total() mümkün olmalıdır, ancak bu yalnızca yaklaşık olacaktır çünkü ikisi toplamı hesaplamak için kullanılan farklı işlemlerdir. Bazen mevsimler çok farklıdır. Sisteminizi düzenli aralıklarla temizlemek için setInterval seçeneğini kullanın. Console.log('İşlenen iletiler sıradan silinmiştir')*).
Mongodb Kuyruğu
MongoDB kuyrukları (veya mesaj kuyrukları), mesajları sıralı, ilk giren ilk çıkar şeklinde depolamak için bir mekanizma sağlar. Mesajlar herhangi bir zamanda kuyruğa eklenebilir ve alındıkları sırayla işlenir. Bu, MongoDB kuyruklarını belirli bir sırada gerçekleştirilmesi gereken görevleri işlemek veya eşzamansız olarak işlenebilen görevler için ideal hale getirir.
FloQast'ın misyonu, ürün ekiplerinin yenilikçi ürünlerin gelişimini hızlandırmasını ve otomatikleştirmesini sağlamaktır. Geleneksel olarak AWS SQS, mesaj kuyruğu hizmetimiz olarak hizmet vermiştir. Bu, işlenebilirliği ve tekrarlamayı sürdürme açısından sorunlara yol açmıştır. Bunun yerine, mesaj kuyruğumuz olarak MongoDB'yi seçtik. AWS Lambda'da herhangi bir kuyruğa kolayca mesaj ekleyebilirsiniz. Ayrı bir Lambda kullanmak için mevcut hizmetleri yükseltme ihtiyacını ortadan kaldırır. Bir kuyruğa erişildiğinde hizmet, ilk öğeyi almak ve geliştiricinin talimatlarına göre Lambda'yı çağırmak için MongoDB'nin atomik findAndModify yöntemini kullanır.
Mongodb'da Değişim Akışı Nedir?
Gerçek zamanlı olarak, uygulama geliştiricileri, işlem günlüğüne takılma korkusu olmadan veya karmaşık veri yapılarının karmaşıklığı ve riskleriyle uğraşmak zorunda kalmadan verilerdeki değişiklikleri görebilir. Bir değişiklik akışı, bir uygulama tarafından herhangi bir koleksiyon, veritabanı veya dağıtımdaki verilerdeki tüm değişikliklere abone olmak ve bunlara anında tepki vermek için kullanılabilir.
Veritabanı İşlemlerini Otomatikleştirmek İçin Tetikleyicileri Kullanın
Tetikleme mekanizmalarını kullanarak veritabanı işlemlerini otomatik hale getirebilir ve sisteminizi daha verimli hale getirebilirsiniz. Bağlantılı bir MongoDB Atlas kümesine bir belge eklendiğinde, güncellendiğinde veya kaldırıldığında, tetikleyiciler sunucu tarafı mantığını işleyebilir. Sisteminizin sorunsuz çalışmasını sağlayabilecek ve sonuç olarak veritabanı işlemlerini otomatik hale getirebileceksiniz.
Nosql Belge Veritabanı
İlişkisel olmayan veritabanı olarak da adlandırılan NoSQL veritabanı, geleneksel tablo tabanlı ilişkisel veritabanı yapısını kullanmayan bir veritabanıdır. NoSQL veritabanları genellikle büyük veri ve gerçek zamanlı web uygulamaları için kullanılır.
Belge yönelimli bir veritabanı, geleneksel sütunları ve satırları kullanmak yerine verileri JSON'da depolamanın modern bir yoludur. Bu yarı yapılandırılmış veriler, aksi takdirde bir RDBMS gerektirecek zor sorunların üstesinden gelmek için kullanılabilir. Doküman depoları, çevik yazılımlarla daha hızlı çalışmak isteyen geliştiricilerin kullanabileceği doğal ve esnek bir çözüm sunar. Etkileyici sorgu dili ve çok yönlü indeksleme yetenekleriyle çeşitli şekillerde sorgulama yapabilirsiniz. İlişkisel bir veritabanı, ACID işlemlerini çalıştırırken aşina olduğunuz bir dizi garantiye sahiptir. Dağıtılmış sistemlere sahip olmak, verilerinizi daha verimli ve uyarlanabilir bir şekilde ölçeklendirmenize ve korumanıza olanak tanır. Her belge, bağımsız bir birimdeki birden çok sunucuya dağıtılır ve bu da veri yerelliği ihtiyacını azaltır.
Belge veritabanları, ilişkisel veritabanlarından daha yüksek veri hızlarıyla sezgisel ve kullanımı kolaydır. Verilerin kalitesi daha düşük olacak ve tablolar katı olacaktır. Yerel ölçeklendirme gerçekleştirilemediğinden, geleneksel ilişkisel veritabanınızı bölümlere ayırmak istiyorsanız, pahalı ölçeklendirme sistemleri için ödeme yapmanız gerekir. Belge odaklı veritabanlarında çok çeşitli belge türleri arasından seçim yapmak mümkündür; ancak her mağazada bulunan alanlar isteğe bağlı olabilir. Her belge aynı yapıya sahiptir, ancak alanları farklıdır. Her belgenin, bilgi eklemek, değiştirmek, silmek ve sorgulamak için kullanılabilen kendi benzersiz kimliği vardır. Belge kodlamalarının tipik olarak, kapsüllenmiş verileri (veya bilgileri) standart bir formata dönüştürme süreci olduğu düşünülür.
Belge odaklı bir veritabanı yapısı daha az katıdır ve bu nedenle tutarsızlığa daha az eğilimlidir. Bilgileri veritabanındaki sütunlar yerine doğrudan belgeden sorguladığınızda, veriler belgede daha doğrudan depolanır. Verilerle ilgili bilgi alanlarını içeren tek bir alanla belge deposuna veri eklenebilir.