
NoSQL Veritabanları: Yüksek Trafik ve Büyük Veri Kümeleri İçin Web Ölçekli Veritabanları
Yayınlanan: 2022-11-18Nosql veritabanları , yüksek trafik ve büyük veri kümelerini işleyebilen web ölçekli veritabanlarıdır. Ölçeklenebilir olacak ve yüksek yükleri taşıyacak şekilde tasarlanmıştır. Bir nosql veritabanı, sisteme daha fazla sunucu eklenerek yatay olarak ölçeklendirilebilir. Bu, sistemin daha fazla trafiği yönetmesine ve daha fazla veri depolamasına olanak tanır.
Karmaşık uygulamalara olan talebin artması, daha fazla esneklik gerektirir. Ölçeklendirmesi kolay ve verimli bir şekilde çalıştırılan veri depolarını seçmek de aynı derecede önemlidir. En önemli konu, bir uygulamayı çalıştırmak için 'ASL' veya 'NoSQL' veritabanlarının daha iyi olup olmadığıdır. SQL veritabanları bir süredir kullanılmaktadır, ancak NoSQL veritabanlarının ölçeklenmesinin daha kolay olduğu bilinmektedir. NoSQL veritabanları için, parçalamanın tüm işlemlerde gerçekleştirilmesi gerektiği varsayımı vardır. Bir düğüm, veritabanındaki her veri işleminden beklenen bir niteleyici işlevle tanımlanabilir. Veriler birden çok makinede depolandığından, en temel makinelerde bile veri işlemlerini yürütmek çok verimlidir.
Bu özellikle, NoSQL depolarını ölçeklendirmek için basit ticari makineler kullanılabilir. NoSQL, kullanıcının verileri herhangi bir işlem için yalnızca aynı düğümden zamanın belirli bir noktasında alınacak şekilde planlayıp yapılandırabileceğini varsayar. Ek olarak, düğümler arasında verilerin normalleştirilmesi (başlangıç için önceden pişirilmiş veriler) gerçekleştirilebilir. NoSQL birleştirmeleri için bir yer var, ancak bunların SQL açısından zengin veya optimize edilmiş olmasını beklemeyin. Uygulamada, verilerin her zaman NoSQL uygulamalarıyla tutarlı olacağı varsayılır. Tutarlılık önemliyse zaman içinde tutarlılığı değiştirmek için anahtarlar sağlayan çok sayıda NoSQL sistemi vardır. Kullanım durumunu değerlendirme hedefi gibi herhangi bir mimari kararının amacı, uygun veri deposunu seçmektir.
Yatay bir ölçeklendirme havuzu, içine daha fazla makine eklenerek genişletilebilirken, dikey bir ölçeklendirme havuzu, daha fazla makine eklenerek genişletilebilir.
SQL veritabanları ve NoSQL veritabanları, verilerin depolanma biçimi nedeniyle (ilişkili tablolara karşı ilgisiz koleksiyonlar) dikey ölçeklendirmeyi kullanır, oysa NoSQL veritabanları, ilgili tabloları kullanmadıkları için yatay ölçeklendirmeyi kullanır.
NoSQL tarafından desteklenen ölçeklendirme türü yataydır.
Yatay olarak ölçeklendirmek için MongoDB, verileri birden çok sunucu arasında taşımanıza izin veren yerleşik bir mekanizma kullanır. Bu işleme parçalama denir ve bunu Atlas Kullanıcı Arayüzünün yapılandırma sayfasındaki bir açma/kapatma düğmesine basarak gerçekleştirebilirsiniz. Bunun dışında, süreç aksama olmadan da tamamlanabilir.
Nosql'de Yatay Ölçeklendirme Nasıl Çalışır?
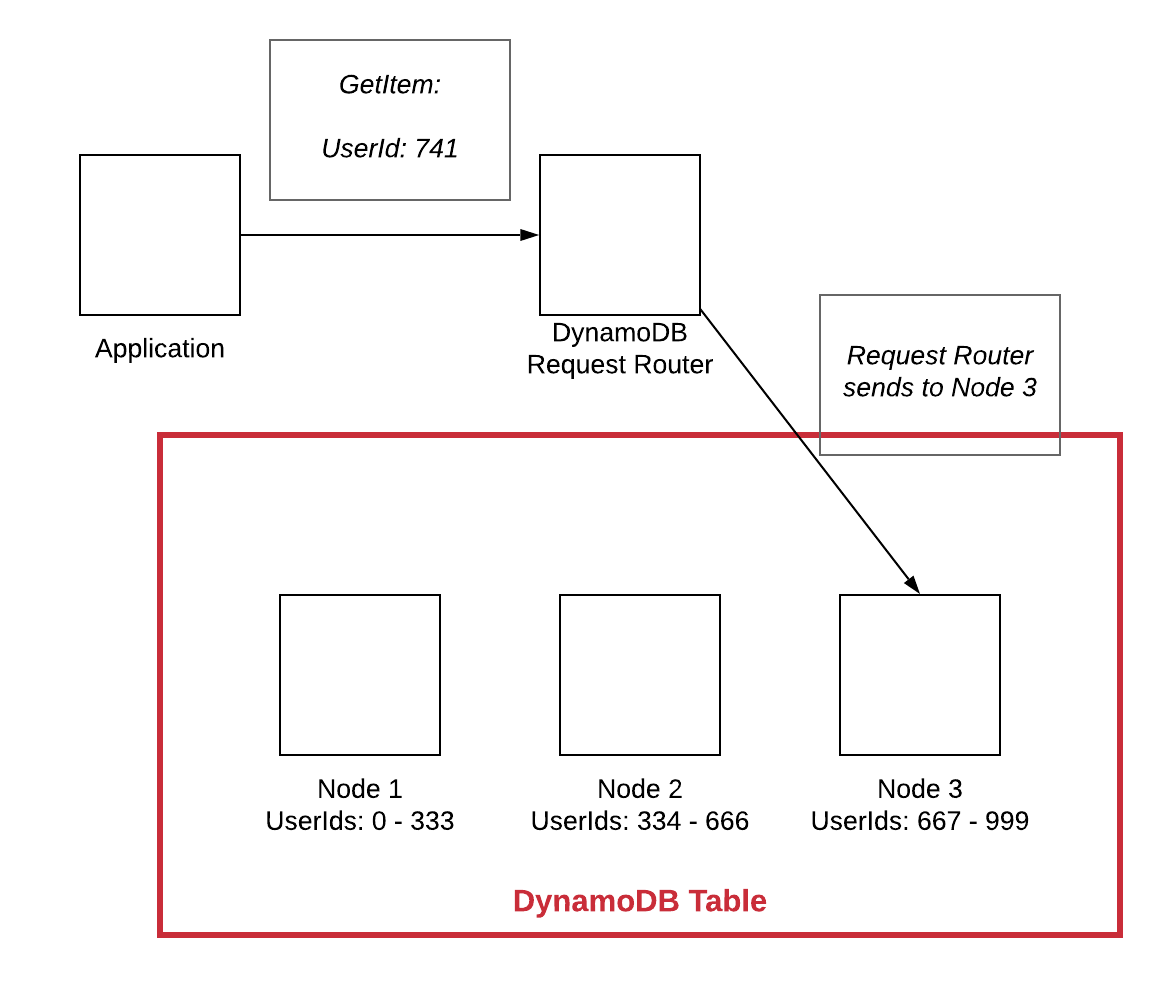
Bir NoSQL veritabanında yatay ölçeklendirme, tek bir makineyi daha hızlı veya daha güçlü hale getirmek yerine, veritabanının sisteme daha fazla makine eklenerek ölçeklenebileceği anlamına gelir. Bu, sistemin performans sorunları yaşamadan daha fazla trafiği ve veriyi işlemesine olanak tanır.
Yatay ölçeklendirmenin sayısız avantajı vardır: artan trafiği işlemek için kolayca daha fazla sunucu ekleyebilirsiniz ve aynı anda birden çok sunucudan satır yükleme konusunda endişelenmenize gerek kalmaz. Sonuç olarak, NoSQL veritabanları, veri depolamadan tasarruf ederken talep üzerine veri depolamak isteyen işletmeler için mükemmel seçimlerdir.
Nosql Veritabanları Büyük Veri Kümelerini İşlemek İçin Daha İyi
İlişkisel veritabanlarının sınırlamaları nedeniyle, büyük veri kümelerini işleyemezler. MongoDB gibi NoSQL veritabanları, verilerinizi bağımsız bir belge biçiminde depolayarak, verilerinizi birden çok düğüme dağıtmanıza olanak tanır. Bu özelliği sayesinde veritabanı, büyük veri kümelerini hızlı ve kolay bir şekilde işleyebilmektedir.
Mongodb Yatay Olarak Nasıl Ölçeklenebilir?
MongoDB, parçalama kullanarak yatay olarak ölçeklenebilir. Parçalama, verileri birden çok sunucu arasında bölme işlemidir. Her sunucunun kendi veri kümesi bölümü vardır ve veriler sunucular arasında eşit olarak dağıtılır. Bir istek yapıldığında, MongoDB sunucusu talep edilen verilerin hangi sunucuda olduğunu belirleyecek ve bu verileri o sunucudan alacaktır. Bu işlem, MongoDB'nin yatay olarak ölçeklenmesine ve büyük miktarda veriyi işlemesine olanak tanır.
Altyapıyı ölçeklendirme söz konusu olduğunda, birçok işletme zor zamanlar geçirdiğini fark eder. Hizmet olarak sunulan MongoDB veritabanı platformu, çok çeşitli ölçeklendirme seçeneklerini destekler ve arka ucuna yerleştirilmiştir. Yatay olarak ölçeklendirme tekniği parçalama olarak bilinir (çünkü tercih edilir). "Katmanlı ölçeklendirme" terimi, tek bir sunucunun veya kümenin yukarı doğru ölçeklendirme yeteneğini ifade eder. Verilerin birden çok düğüme dağıtılmasını içeren yatay bir ölçeklendirme yöntemidir. MongoDB Atlas platformu otomatik olarak bir parça anahtarı yapılandırır, bu hâlâ bize bağlıdır. Çoğaltma kümeleri ve parçalamanın benzer olduğu açıktır, ancak veri kümeleri aynı değildir.
Ayrıca, uygulamalar için büyük miktarda yazma işleminde sorunlara neden olabilirler. MongoDB Atlas ayrıca yatay ve dikey ölçeklendirmeyi de destekler. Parçalı bir kümenin konuşlandırılması, yatay ölçeklendirmeyi mümkün kılar. Özetle, dikey ölçeklendirme, bir küme katmanını yapılandırmak kadar basittir. Tam bir kapatma durumunda, kümeyi 0'da tutmak için küme duraklatılabilir ve depolama hariç tüm küme etkili bir şekilde 0'a ölçeklenir.
MongoDB, büyük veri kümelerini işlemek için yatay olarak ölçeklenmesi gereken modern bir uygulama olduğu gibi mükemmel bir NoSQL veritabanıdır. MongoDB, geliştiricilerin verilere erişmesini ve bunları işlemesini kolaylaştıran basit bir API'ye sahiptir ve şemasız depolaması, verileri depolamayı ve almayı kolaylaştırır. Ayrıca, MongoDB çoğaltmayı desteklediğinden, veriler birden çok sunucuda kolayca çoğaltılabilir ve gelecekte kullanım için kullanılabilir durumda kalması sağlanır.
Mongodb'un Ölçeklenebilirliği
MongoDB, en esnek programlama dillerinden biridir. MongoDB gibi belge odaklı bir veritabanında, veriler JSON benzeri belgelerde saklanır. MongoDB işlemi, parçalama kullanımıyla yatay olarak ölçekleniyor. Srave, verileri veritabanları ve makineler arasında dağıtmak için birden çok koleksiyon ve makine kullanan bir veri dağıtım tekniğidir.
Sql Db Yatay Olarak Ölçeklendirilebilir mi?
Yatay ölçeklendirmede, genel kapasiteyi veya performansı artırmak veya azaltmak gibi belirli bir görevi gerçekleştirmek için veritabanları eklenir veya kaldırılır. Yatay ölçeklendirme, tipik olarak, aynı şekilde yapılandırılmış birden çok veri tabanından gelen verilerin birleştirilmesi ve ardından bunların ayrı tablolara ayrılmasıyla uygulanır.
Her veritabanı, her gün, üretilen veri hacmini işlemek için ölçeklendirilmelidir. Ölçekleme dikey ve yatay olmak üzere ikiye ayrılır. 2 TB sunucunun belleği daha fazla veri depolamak için yeterlidir. Son derece yüksek bir fiyata büyük bir sunucu satın alıyor. Sunucuya daha fazla makinenin eklenmesi yatay ölçeklendirme olarak adlandırılır. Amacı, veri kümesini birden çok sunucuya veya parçaya bölmektir. De-normalizasyona dayalı tek bir doğruluk noktasına sahip olmak anlamsız olacaktır. Bu yaklaşımın bir dezavantajı vardır: Master, bir yazma işlemi gerçekleştirirken bağımlı replikaları güncelleyemezse, master, bağımlı replikaları güncellemeyecektir.

Çoğaltma, bir kümedeki düğümler arasında veri alışverişi yapma eylemidir. Verileri çoğaltarak, bir sunucunun kullanılabilirliğini ve kurtarılmasını artırabilirsiniz. Ek olarak, yükü birden çok düğüm kümesine yaymak için çoğaltma kullanılabilir. Bir kuruluş, verilerini yatay olarak daha küçük parçalara bölebilir ve bu parçaları birden çok düğüme dağıtabilir. Yatay olarak bölümleme, performansı artırır. Varsayılan MongoDB kümelerine ek olarak birkaç farklı türde MongoDB kümesi vardır. Genel olarak tek düğümlü küme, en basit küme türüdür ve test ve geliştirme için çok uygundur. İki düğümlü bir küme, en yaygın küme türüdür ve orta ila büyük ölçekli uygulamalar için uygundur. Üç düğümlü bir küme de popülerdir ve büyük ölçekli uygulamalar için uygundur. Örneğin, iki düğümlü bir kümede, veriler her düğümde iki ayrı parçaya bölünür. Bu durumda, her düğümde verilerin bir kopyası bulunur. Bir düğümün yükü arttığında, diğer düğüm yükü kaldırabilir. Yük dengeli bir küme, en yaygın küme türlerinden biridir. Üç düğümlü bir küme, her biri üç ayrı parça içeren üç ayrı veri merkezinden oluşur. Bir düğümün yükü artarsa, diğer iki düğüm görevi devralabilir. Dengeli bir küme bu kümelerden biridir. MongoDB veritabanı, yatay ölçeklendirme yeteneklerine sahip modern bir belge tabanlı veritabanıdır: çoğaltma ve yatay bölümleme (veya parçalama). Bir veritabanını yatay ölçeklendirme süreci, artan taleple başa çıkmak için daha fazla örnek veya düğüm eklemeyi içerir. Daha fazla kapasiteye ihtiyaç duyduğunuzda, kümeye daha fazla sunucu eklemeniz yeterlidir. Ek olarak, sunucular genellikle masaüstü bilgi işlem için kullanılanlardan daha küçük ve daha ucuzdur. Bir kümedeki düğümler arasında veri kopyalama işlemidir. Bölümleme verileri yatay olarak daha küçük parçalara böler ve bunları dağıtılmış bir sistemdeki birden çok düğüme dağıtır. Her biri farklı özelliklere sahip birkaç tür MongoDB kümesi vardır. Dört düğümlü bir küme kadar etkili olmasalar da üç düğümlü kümeler de yaygındır.
İlişkisel Bir Veritabanıyla Yatay Ölçeklendirme
Geleneksel bir SQL veritabanı, daha fazla sunucu barındırması gerektiğinden genellikle yatay olarak ölçeklenemez, ancak yine de diğer makinelerin kopyalarını ekleyebiliriz. Önceden Yazma Günlüğü, tüm yazma işlemlerini ana sunucudan diğer makinelere yaymak için kullanılır. Sorgu sözdiziminin esnekliği nedeniyle, ilişkisel veritabanları yatay olarak ölçeklenemez. Sorgunuzu yürütene kadar verilerinizin hiçbir parçasının getirilmemesini sağlamak için SQL, verilerinize o kadar çok koşul ve filtre eklemenize izin verir ki, veritabanınızın hangi parçaların alınacağını tahmin etmesi imkansızdır. Sonuç olarak, veritabanı büyük miktarda veriyi işlemeye çalışırken yavaşlayabilir. İlişkisel veritabanları yatay olarak ölçeklenebildiğinden, Spark Akışı veya toplu hesaplamalar için bir depolama ortamı işlevi görerek Spark'ın genellikle daha az etkili olduğu alanları kapsamaya yardımcı olabilirler. Bulut SQL platformu , bu yapılandırmaları yerel olarak desteklemez, ancak ProxySQL gibi endüstri araçları kullanılarak uygulanabilir. Ancak, Cloud SQL'in temel konsepti bu tür senaryolar için tasarlanmamıştır.
Nosql Neden Yatay Olarak Ölçeklendirilebilir?
NoSQL veritabanları, gereksinimlerine bağlı olarak yatay veya dikey olarak ölçeklenebilir. İşleme daha fazla sunucu ekleyerek NoSQL veritabanınızı parçalara ayırarak yüksek trafik durumlarının üstesinden gelebilirsiniz. NoSQL veritabanları, dikey yerine yatay olarak ölçeklenebildikleri için büyük ve sık değişen veri kümeleri için tercih edilen seçimdir.
Çok büyük veritabanlarını , çok yüksek istek oranlarıyla, çok düşük gecikmeyle işleyebilmelidir. Ölçekleme ve kullanılabilirlik, eBay, Amazon, Twitter ve Facebook gibi yüksek hacimli web siteleri için kritik gereksinimlerdir. Bir sunucuda aynı anda birden çok örneği çalıştırma olanağına sahip olduğunuzda, yatay ölçeklendirme idealdir.
Ölçeklenebilirlikleri ve esneklikleri nedeniyle NoSQL veritabanları, SQL veritabanlarına kıyasla popülerlik kazanıyor. Ayrıca, işlenmesi ve depolanması zor olan yapılandırılmamış veriler için tablo tabanlı veritabanlarına kıyasla daha iyi performans gösterirler.
Nosql Veritabanını Ölçeklendirme
Bir NoSQL veritabanını ölçeklendirmenin en iyi yolu, uygulamanın özel gereksinimlerine ve depolanan verilere bağlı olduğundan, bu sorunun herkese uyan tek bir yanıtı yoktur. Bununla birlikte, bir NoSQL veritabanının nasıl ölçeklendirileceğine ilişkin bazı ipuçları, kapasiteyi ve performansı artırmak için kümeye daha fazla düğüm eklemeyi, verileri birden çok düğüme dağıtmak için parçalamayı kullanmayı ve yüksek kullanılabilirliği sağlamak için verileri birden çok düğüme çoğaltmayı içerir.
Couchbase'den Rahim Yaseen bize bunları anlatırken birçok önemli noktayı ele alıyoruz. Kuruluşlar, büyük miktardaki verilerini yönetmek, depolamak ve bunlardan para kazanmak için çabalıyor. Önemli bir veritabanı kararı ölçeğin genişletilip genişletilmeyeceğidir. Kayıt, manuel parçalamada check-in kabinlerine dağıtılır. Bu, iyi tanımlanmış, önceden tanımlanmış bir şema sayesinde gerçekleştirilir. Otomatik parçalamanın bir parçası olarak, kimin S ile başlayan bir soyadıyla check-in yaptığını öğrenmek için her kabine gitmeniz gerekir. Belge veritabanlarında, kullanıcıların belirli bir anahtar aracılığıyla başka bir belgeye gitmesini ve verilere tek bir anahtar aracılığıyla erişmesini gerektiren erişim kalıpları vardır. anahtar. Dağıtılmış bir veri kümesinin boyutu büyüdükçe, onu dizine eklemek ve sorgulamak giderek daha zor hale gelir.
Sorgudaki her düğümün buna katılması gerektiğinden harita azaltma tekniği kullanmak anlamsızdır. Veri hacmi büyüdükçe, RDBMS modelini büyütmek giderek daha az uygulanabilir hale geliyor. Büyük bir veri kümesi söz konusu olduğunda, bir ölçek büyütme mimarisinin başarısızlığının çok büyük bir başarısızlık noktası olması muhtemeldir. İnternet, ultra ölçekli, paylaşımsız bir küme örneğidir.
Nosql Veritabanları: Ölçeklenebilirliğin Geleceği
Veriler, Nosql veritabanlarında birden çok makine arasında gönderildiğinden, son derece ölçeklenebilirdirler. Sonuç olarak, özel ekipman gerektiren pahalı makineler satın almak yerine kolayca CPU gücü ekleyebiliriz. Ayrıca, Nosql veritabanları büyük miktarda veriyi sınırsız olarak tutabilir, bu da onu çok yönlü bir veri yönetim sistemi yapar.
Sql Veritabanı Yatay Olarak Ölçeklenebilir mi?
Evet, SQL veritabanları yatay olarak ölçeklenebilir. Bu, her biri toplam verilerin bir bölümünü işleyen birden çok sunucuya yayılabilecekleri anlamına gelir. Bu, tek bir sunucunun sağlayabileceğinden daha fazla ölçeklenebilirlik sağlar.
Sql Veritabanları Neden Yatay Olarak Ölçeklenemez?
Sorgu sözdiziminin esnekliği nedeniyle, ilişkisel bir veritabanında yatay olarak ölçeklendirmek imkansızdır. SQL'in bir sonucu olarak, verilerinize, sorgu tamamlanana kadar veritabanı sisteminin hangi parçalarının döndürüleceğini bilmesini engelleyen istediğiniz sayıda koşul ve filtre ekleyebilirsiniz.
Sql Neden Dikey Olarak Ölçeklenir?
Dikey ölçeklendirmenin amacı, esas olarak mevcut kaynakları artırarak mevcut sistemlerin güç tüketimini ve RAM kapasitesini artırmaktır. Dikey ölçeklendirme sadece daha kolay değil, aynı zamanda daha ucuzdur. Sorun ayrıca uzun vadeli bir düzeltme gerektirmez.