
HDF5 Veri Formatı: Büyük Veri Koleksiyonlarını Depolamak ve Yönetmek İçin Çekici Bir Seçenek
Yayınlanan: 2023-02-13HDF5, büyük, karmaşık veri koleksiyonlarını depolamak ve yönetmek için tasarlanmış bir veri formatıdır. Bilimsel ve mühendislik uygulamalarında sıklıkla kullanılmaktadır ve popülaritesi son yıllarda giderek artmaktadır. HDF5 bir veritabanı değildir, ancak verileri bir dosya sistemine benzer hiyerarşik bir biçimde depolamak için kullanılabilir. Bu, HDF5'i büyük miktarda veri depolaması ve yönetmesi gereken uygulamalar için çekici bir seçenek haline getirir.
HDF5 ve netCDF4 dosyalarından meta verileri ve ham verileri ayıklayabilir ve Hadoop Dağıtılmış Dosya Sistemi (HDFS) HDF5 Bağlayıcı Sanal Dosya Sürücüsünü (VFD) kullanarak Hadoop verilerini analiz etmek için Hadoop akışını kullanabilirsiniz.
Hdf5 Bir Veritabanı mı?
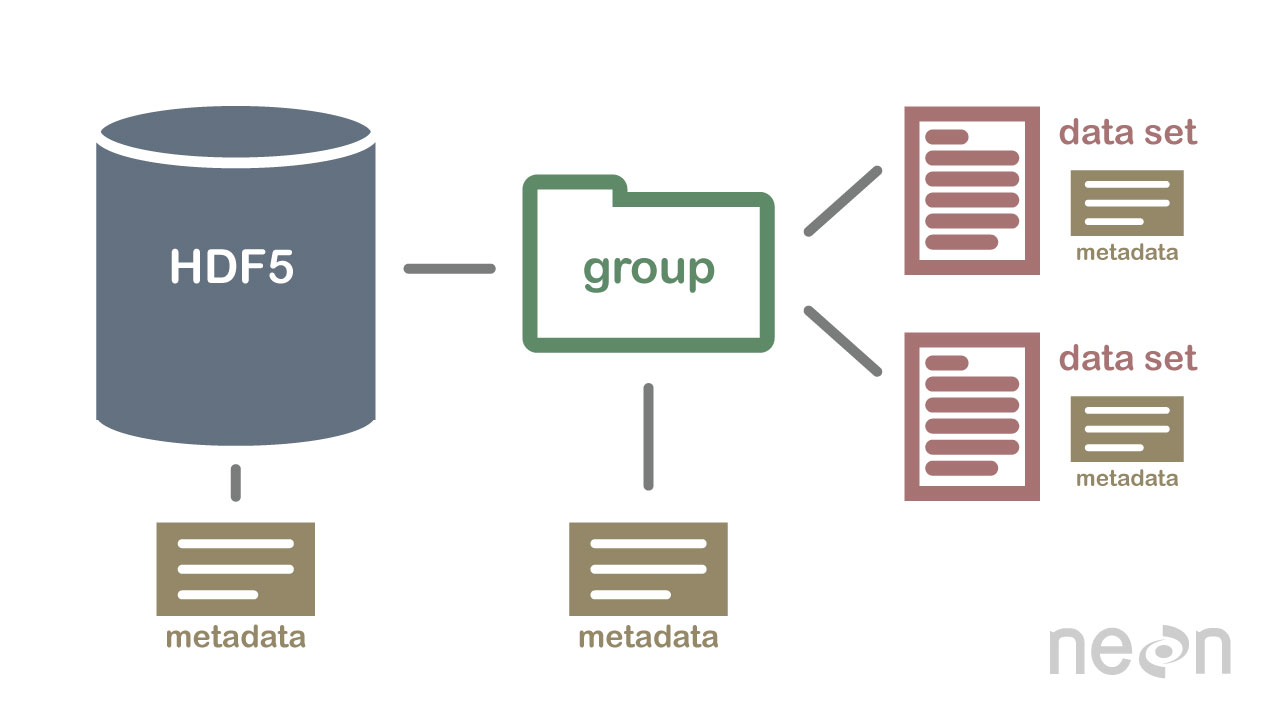
HDF5 bir veritabanı değildir, ancak bir dosya sistemine benzer şekilde hiyerarşik bir yapıda veri depolamak için kullanılabilir. HDF5, metin, resim ve ikili veriler dahil olmak üzere çeşitli biçimlerdeki verileri depolamak için kullanılabilir.
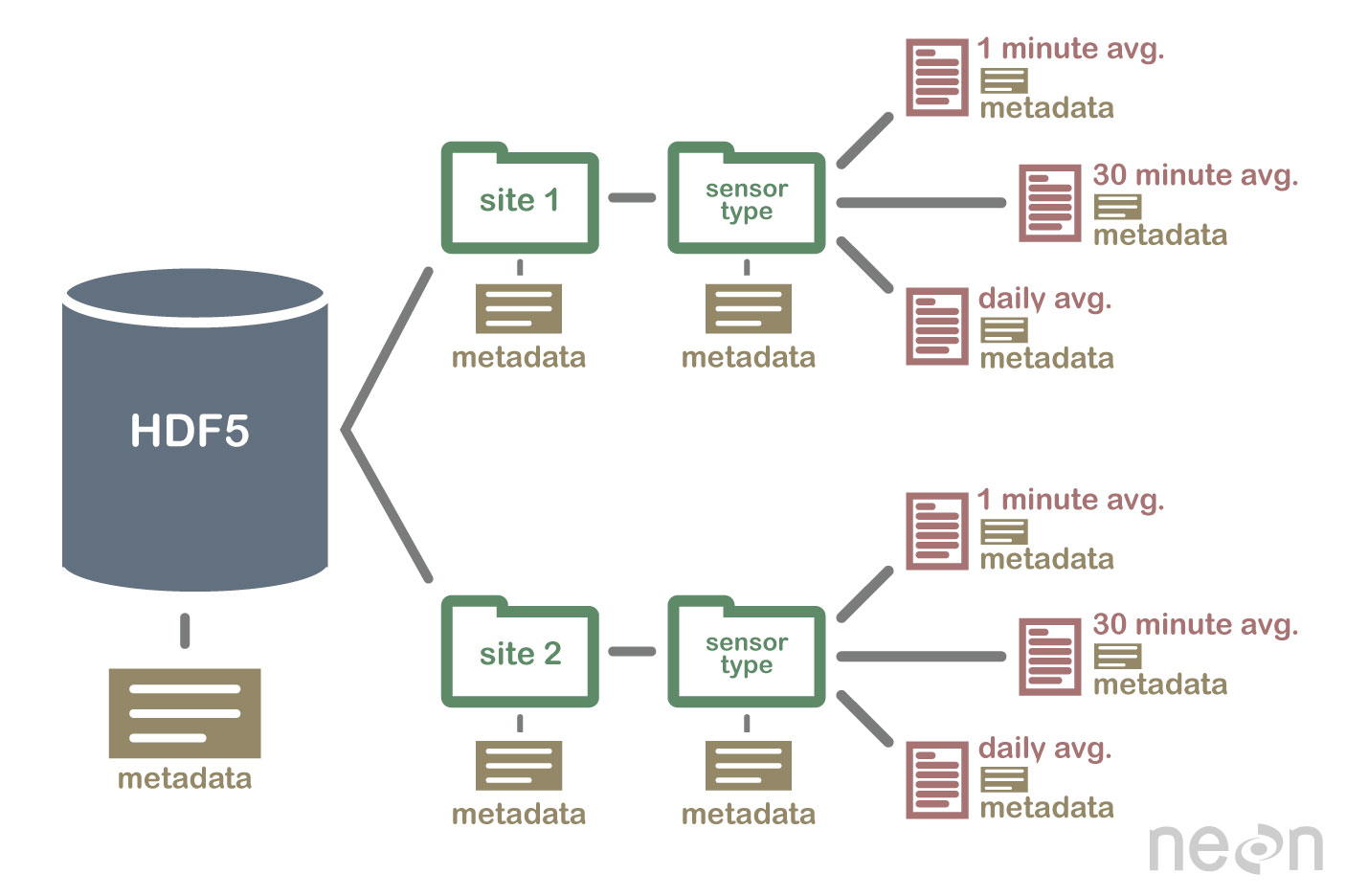
Hiyerarşik formattaki (HDF5) veriler, bilimsel araştırmalarda son derece faydalıdır. HDF5 dosya sistemi, çok verimli olması açısından bir dosya sistemine benzediği için mükemmel bir formattır. Bu formatta şifrelenmiş veri söz konusu olduğunda, ona erişmek zor olabilir. Bu kılavuz, Apache Drill'in HDf5 veri kümelerine kolayca erişmenize ve bunları sorgulamanıza nasıl yardımcı olabileceği konusunda size yol gösterecektir. Drill, defaultPath seçeneği aracılığıyla bağımsız HDF5 dosyalarına erişebilir. Bu, sorgu süresi boyunca doğrudan tablo() işlevinin yürütülmesiyle veya yapılandırma aracılığıyla gerçekleştirilir. Bu sorgunun sonuçları aşağıdaki tabloda bulunabilir. Drill daha sonra sütunları seçebilir ve bunları tek tek filtreleyebilir, filtreleyebilir, toplayabilir veya sorgulayabileceği diğer verilerle birleştirebilir.
HDF5 spesifikasyonu, veri dizilerini depolamak için bir dosya formatı tanımlar. Bir veri dizisi, dize, değişken, karmaşık ve tamsayı verileri dahil olmak üzere herhangi bir veri türünden oluşabilir. Bir dizi, herhangi bir boyuttaki verileri içerebilir ve herhangi bir şekilde olabilir. HDF5'te, bir veri seti oluşturmak için önce bir başlık dosyası oluşturmak gerekir. Başlık dosyası, meta verilerin yanı sıra veri kümesi hakkında bilgiler içerir. Başlık dosyası iki önemli bilgi içerir: veri setinin adı ve veri setinin sürüm numarası. Bir veri kümesinin verilerini depolamak için bir veri dizisi kullanılır. Bloklar, bir veri dizisindeki verilerden oluşur. Veri dizisinde, her veri bloğu bitişik bir veri kümesi içerir. Bir veri kümesinin blok sayısı, içindeki bayt sayısına göre belirlenir. Verilere, HDF5 spesifikasyonuna uygun olarak bir dizi yöntemle erişilebilir. İndeksleme yöntemleri en yaygın olarak bir veri kümesindeki verileri elde etmek için kullanılır. Bu yöntemleri kullanarak, erişmek istediğiniz veri dizisindeki bir bloğun adını girerek verilere erişebilirsiniz. Yapı yöntemi, bir veri kümesindeki verilere erişmek için kullanılabilir. Bu yöntemleri kullandığınızda, bir veri dizisinin yapısını kullanarak verilere erişebilirsiniz. Aşağıdaki örnekte, yapı yönteminin ofset ve uzunluk değerlerini kullanarak bir veri dizisindeki verilere erişebilirsiniz. Bir veri kümesinden veri almanın başka bir yolu da işlev yöntemlerinin kullanılmasıdır. Veriler için başlık dosyasındaki işlevi seçerek yöntemlerden birini kullanarak veri elde edebilirsiniz. Bir veri dizisine erişme yöntemi, başlık dosyasındaki değeri dizinin veri dizisi öğesi olarak tanımlayarak kullanılabilir. Son olarak, erişim yöntemini kullanarak bir veri kümesindeki verilere erişebilirsiniz. Bu yöntemleri kullanarak, başlık dosyasında ayarlanan erişim ayrıcalıklarını kullanarak verilere erişebilirsiniz. Başka bir deyişle, okuma ayrıcalığı kullanılarak, bir veri dizisindeki verilere erişim yöntemi aracılığıyla erişilebilir. Veriler, HDF5 spesifikasyonu kullanılarak çeşitli şekillerde oluşturulabilir ve kullanılabilir. Create yöntemi, bir veri kümesi oluşturmak için en yaygın yöntemdir. Create yöntemini kullanarak, veri kümesinin adını ve veri kümesinin sürüm numarasını girerek bir veri kümesi oluşturabilirsiniz. HDF5 spesifikasyonuna ek olarak, veri kümelerinin kullanımı çeşitli şekillerde gerçekleştirilebilir. En sık kullanılan yöntem.

Hdf5 İlişkisel Bir Veritabanı mı?
HDF5 ilişkisel bir veritabanı değildir.
Graphql Nosql Veya Sql mi?
GraphQL'nin birincil amacı, verileri daha hızlı ve daha verimli bir şekilde döndürmek için bir tür sistemi kullanmaktır. SQL (yapılandırılmış sorgu dili), verileri tablo veya ilişkisel veritabanı sistemlerinde depolamak için daha eski ve daha yaygın olarak kullanılan bir dildir. API'nizin bir NoSQL veritabanı üzerine inşa edilmesini istiyorsanız, GraphQL ile çalışmak iyi bir fikir olacaktır.
Type Mismatch, Herman Camarena ve Roger Cochrane tarafından oluşturulan bir GraphQL ve NoSQL veritabanıdır. GraphQL'nin kullanımı, NoSQL sistemlerinin yarattığı esnekliği ortadan kaldıran bir NoSQL sistemi yerine bir tip sisteminin getirilmesiyle sonuçlanabilir. Bir GraphQL koleksiyonu, yapı olarak tutarlı ve birkaç istisna içeren çok çeşitli belgeler içerir. GraphQL, arka uç türleriyle eşleşen yerleşik bir veri türleri kümesine sahip olduğundan, geliştiriciler hangi veri türlerinin oluşturulacağını seçebilir. GraphQL, potansiyelini tam olarak gerçekleştirmek için tür uyumsuzlukları sorununu ele almalıdır. Özellikleri açısından birçok avantajı nedeniyle daha düşük seviyede uyumsuzluk çözümü sağlar. İş, StepZen'in JSON2SDL'si gibi araçlarla giderek daha fazla otomatik hale geliyor.
Daha dayanıklı ve verimli uygulamalar oluşturmak için kullanılabilecek güçlü bir araçtır, ancak SQL onun yerine geçemez. Bakım açısından, bazı görevleri daha zor hale getirdiği için bunun olumsuz bir etkisi olabilir.
Graphql: Her Veritabanı İçin Bir Sorgulama Dili
GraphQL sorgulama dili, istemcilerin ve sunucuların birbirleriyle iletişim kurmasını sağlar. Bir GraphQL örneği, bir veri kaynağından veya kalıcı bir durumdan değişiklikleri alabilir ve devam ettirebilir. Çözücü, verilere erişmek ve verileri işlemek için kullanılan bir dizi isteğe bağlı işlevdir. API, çeşitli veritabanlarında mevcuttur ve GraphQL herhangi biriyle kullanılabilir. MongoDB veritabanı, çeşitli veri türleri için agnostik olan popüler bir veri kaynağı veritabanıdır .
Nosql B Ağaçlarını Kullanıyor mu?
NOSQL veritabanları, ilişkisel modele dayalı olmadıkları için B ağaçlarını kullanmazlar. NOSQL veritabanları genellikle anahtar-değer çiftlerine, belge depolarına veya grafik veritabanlarına dayalıdır.
B-ağaçları, MongoDB'deki varsayılan indeksleme yapısıdır. Veri depolamada , bir B-ağacı daha verimli bir yöntemdir. Veriler, birlikte kullanıldıkları takdirde tamsayılar ve dizeler kullanılarak düzenlenebilir. Sonuç olarak, yüksek hacimli veriye sahip veritabanları kullanmayı düşünmelidir. B ağaçları çok yer kaplayabildikleri için verimli bir modeldir. Bu, büyük miktarda veri tutması gereken veritabanları için faydalıdır. B-ağaçları, verileri belirli bir şekilde düzenlemesi gereken veritabanları için de iyi bir seçimdir.
Hangi Veritabanı B-ağacı Kullanıyor?
Uzun süredir kullanılmaktadır ve çok çeşitli veritabanlarında kullanılabilir. NoSQL veritabanları, B ağacı motorlarına ek olarak B ağacı motorlarının üzerine inşa edilebilir. Örneğin MongoDB, verileri B-ağaçlarında indeksler. Algoritma, bazı istisnalar olmasına rağmen, ilişkisel bir veritabanı için olduğu gibi DBMS için aynıdır. Dizeler ve tamsayılar, B-ağacındaki verileri düzenlemek için kullanılabilir.
Hangi veritabanı B-ağacı kullanır? Aşağıdaki makalede Mysql, hem Btree'yi hem de B+tree'yi kullanır. SQL Server, anahtar tabanlı kalıcı verilere dayalı dizinleri bir BTree biçiminde depolar. Sonuç olarak, böyle bir ağaçtaki her düğüm tek bir sayfa olarak görünür.