
使用 Apriori 算法获得更好的产品推荐
已发表: 2018-10-05在本文中,您将学习有效的产品推荐方法(所谓的购物车分析)。 通过使用特殊算法(Apriori 算法),您将了解哪些产品可以成套销售。 您将获得有关在其他产品的网站上推荐哪种产品的信息。 这样,您将增加商店中的平均购物车价值。
智能产品推荐 - 交叉销售
在线商店增加销售额的方法之一是推荐相关产品。
不幸的是,此类推荐的最常见实现是显示同一类别的产品。 在我们正在查看的产品下,我们看到其他此类产品 - 例如其他鞋类产品。
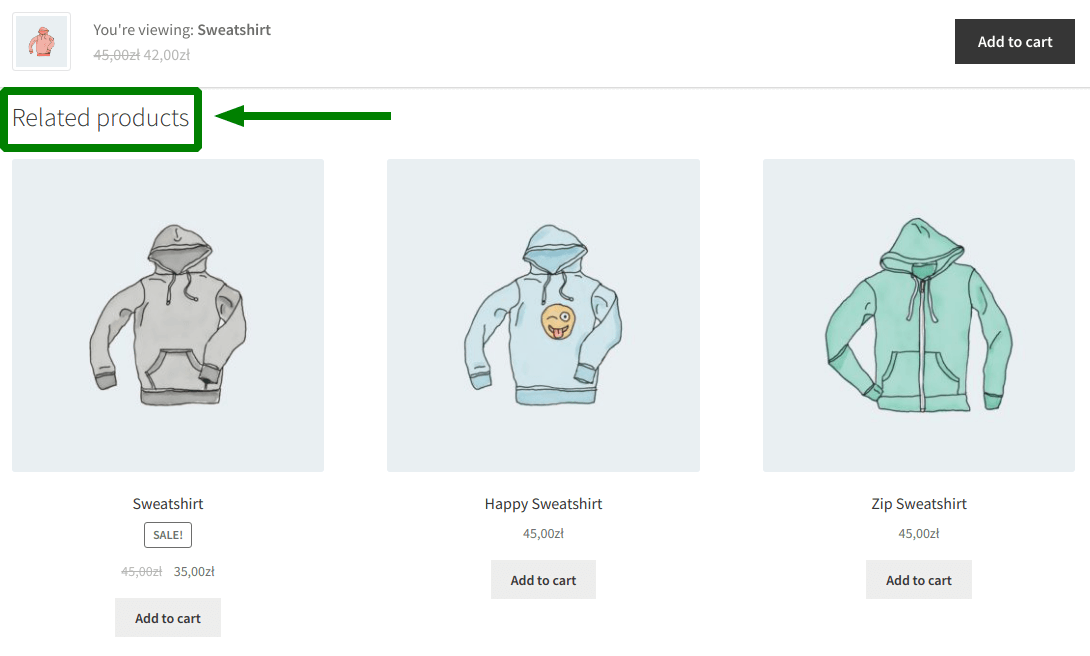
但是,产品之间的关系并不是由它们在商店中添加的联合类别产生的。 当顾客已经将一双鞋放入购物车时推荐其他鞋子毫无意义。 这样,我们就可以盲目猜测这是否有效。 也许客户会在购物车中添加其他东西。
产品推荐的本质是给客户一个他们会明确感兴趣的产品。我们怎么知道这些产品是什么? 感谢统计! 在它的帮助下,我们可以发现大多数购买产品 A 的客户同时购买了 B 和 C。在这种情况下,我们向将 A 放入购物车的客户推荐 B 和 C。 这种产品推荐在购物车页面上效果最好。
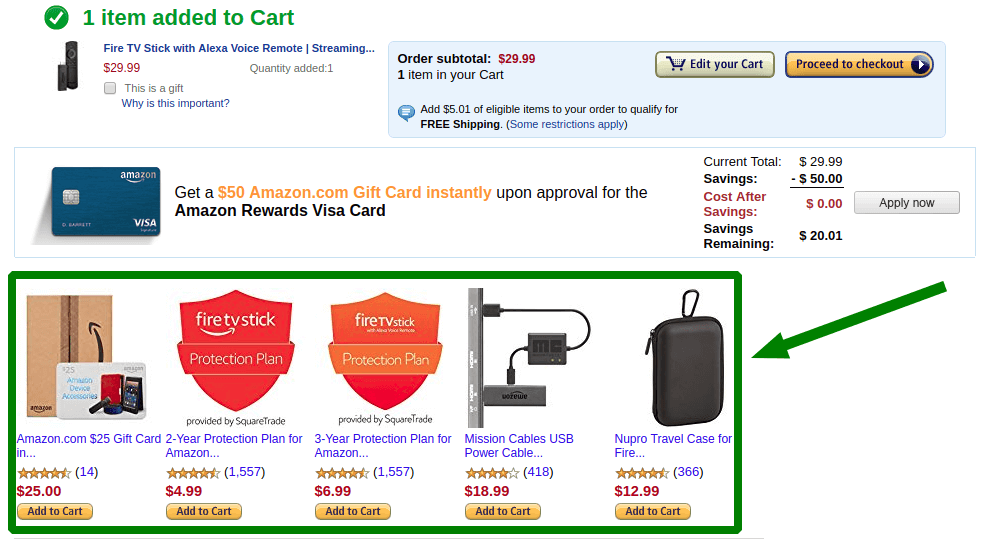
通过这种方式,进行购买的客户可以获得他们可以购买其他商品的信息。 我们感知到某种购买趋势,并促进其对后续客户的实施。
由于方便的界面,后续客户将在他们的订单中添加其他产品。 购物车的价值会增加。 商店会赚更多。 大家都开心 :)
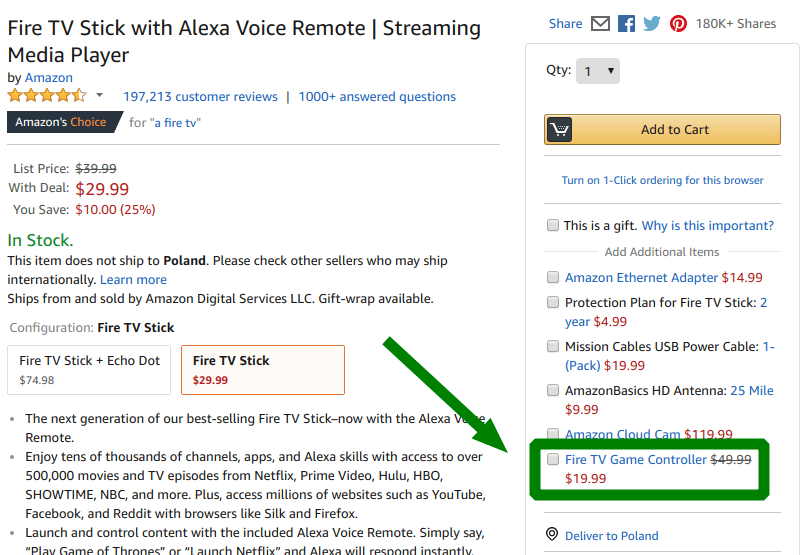
在这种追加销售的情况下,您可以对追加销售的产品应用折扣。 这样,客户对购买的满意度就会提高。
简而言之 Apriori 算法
什么是购物车分析?
问题 - 如何从产品订单中获取有用的数据以进行产品推荐? 答案就是所谓的购物车分析。 它是一种数据挖掘方法。
一种有效且流行的购物车分析算法是 Apriori 算法。 该算法定义了我们挖掘数据的方式以及我们如何评估其有用性。
并非客户购物车中产品的每个相关性都将用于推荐。 如果一个案例在 1000 次中发生了 1 次,那么在商店层面实施这样的建议是没有意义的。 这不是趋势,而是个案。
有效实施的例子
在网上,我们可以找到沃尔玛在 1990 年代使用购物车分析的信息。 它是美国最大的连锁超市之一。 由于购物车分析,我们发现了啤酒和尿布之间的密切关系。 你不会自己想出这样的东西,这种奇怪的相关性来自数据挖掘。
让我们切入正题:啤酒和婴儿尿布通常在周五晚上被年轻人购买。 多亏了这些知识,分析师已经在商店中引入了变化。 首先,他们将这些产品放在一起。 其次,他们修改了营销活动。 大型超市对产品实行所有促销和折扣。 周五,决定这两种产品中只有一种会打折。 在大多数情况下,无论如何都会购买它们。 通过这种方式,商店获得了额外的销售额并节省了营销活动。
传统商店分析中使用的许多原则和方法也可以应用于电子商务。 其中一些更容易实现。 我们的在线商店可以轻松监控 - 点击次数、流量、在网站上花费的时间。 使用购物车中产品的数据来改进推荐系统也是值得的。
一个很好的例子是亚马逊。 超过 20% 的订单是在各种推荐系统的帮助下生成的。
基本概念
Apriori 算法不仅显示产品之间的关系,而且由于其设计,它允许您拒绝无关紧要的数据。 为此,它引入了两个重要概念:
- 支持- 发生频率
- 信心——规则的确定性
该算法可以确定这两个指标的最小值。 因此,我们拒绝不符合推荐质量假设的交易。
该算法的操作是迭代的。 我们不会一次处理所有数据。 多亏了这一点,该算法限制了数据库上的计算次数。
我将向您展示算法在实践中的操作。 我将解释使用支持度和置信度作为 Apriori 算法的关键元素。
Apriori算法的工作原理
例如初始假设
让我们使用一个简化的例子。 假设我们的商店中有四种产品:A、B、C、D。客户进行了 7 笔交易,如下所示:
- A B C D
- 甲,乙
- 乙、丙、丁
- 甲、乙、丁
- 乙,丙
- 丙、丁
- 乙,丁
我们将使用 Apriori 来确定产品之间的关系。 作为支持,我们将值设置为 3。这意味着规则必须在给定的迭代中出现 3 次。

第一次迭代
让我们开始第一次迭代。 我们确定产品在订单中出现的频率:
- A - 3次
- B - 6次
- C - 4次
- D - 5次
这些产品中的每一个都出现在订单中超过 3 次。 所有产品均满足支持要求。 我们将在下一次迭代中使用它们中的每一个。
第二次迭代
我们现在根据一组两个产品寻找产品中的连接。 我们寻找客户将两种选定产品放在一个订单中的频率。
- A、B - 3次
- A、C - 1次
- A、D - 2次
- B、C - 3次
- B、D——4次
- C、D - 3次
如您所见,集合 {A, C} 和 {A, D} 不满足support的假设。 它们出现的次数少于 3 次。 因此,我们将它们排除在下一次迭代之外。
第三次迭代
我们寻找由三种产品组成的套装,其中:
- 发生在客户订单中
- 自身不包含集合 {A, C} 和 {A, D}
因此它是一组:{B, C, D}。 它仅在订单中出现两次,因此不符合我们的支持假设。
结果
我们的假设满足以下条件:
- A, B - 顺序出现 3 次
- B、C - 3倍
- B、D——4次
这个例子只是为了说明算法的操作。 对于大多数在线商店来说,数据计算会复杂得多,因为它们的数量会更多。
以百分比表示的支持
值得补充的是,支持定义了规则在所有事务中的全局份额。 我们同意以数值形式支持我们的最低要求: 3. 但是,我们可以设置一个百分比。 在这种情况下:
- A、B 的支持率约为 42.9% - 7 笔交易发生 3 次
- B、C有相同的支持
- B、D 的支持率约为 57.14% - 它们发生 4 次,共 7 次交易
在我们的示例中,支持因子的高百分比来自少量产品。 我们只有 4 种产品:A、B、C、D。
例如,在有 1000 种产品的商店中,在一半的订单中总是有两种相同的产品是不太可能的。
这个例子是故意简化的。 在您的商店中使用该算法时,您应该考虑到这一点。 您应该为商店、行业等单独设置支持的最小值。
最终结论
信心问题依然存在。 它将给定规则的发生指定给所有发生初始集合的规则。
如何计算它?
{A, B} - 在订单中出现了 3 次 初始设置为 A。该产品也已在订单中出现 3 次。 因此置信度为 100%。
让我们镜像这对。 {B, A}在订单中出现了 3 次。 这里什么都没有改变——这对是一样的。 但是,初始设置发生了变化。 这是 B。该产品已发生 6 次交易。 这给了我们50%的信心。 产品 A 仅出现在产品 B 发生的一半交易中。
- A 和 B 有 100% 的置信度
- B 和 A 有 50% 的置信度
- B 和 C 有 50% 的置信度
- C 和 B 有 75% 的置信度
- B 和 D 的置信度为 66.7%
- D 和 B 有 80% 的置信度
我们的简化示例(4 个产品,7 个交易)产生了以下建议:
- A -> B
- B -> D
- C -> B
- D -> B
其中第一个产品是用户添加到购物车的产品。 第二个是我们推荐的。
结论
购物车分析是产品推荐系统的一种非常有效的方法。 但是,我无法想象根据上述算法进行手动数据处理。 尤其是大型商店。
有效的购物车分析需要方便的实施。 Apriori 算法应该按照程序的原理工作,而不是手动数据处理。
网络上有一个用 Python 实现的 Apriori 算法。
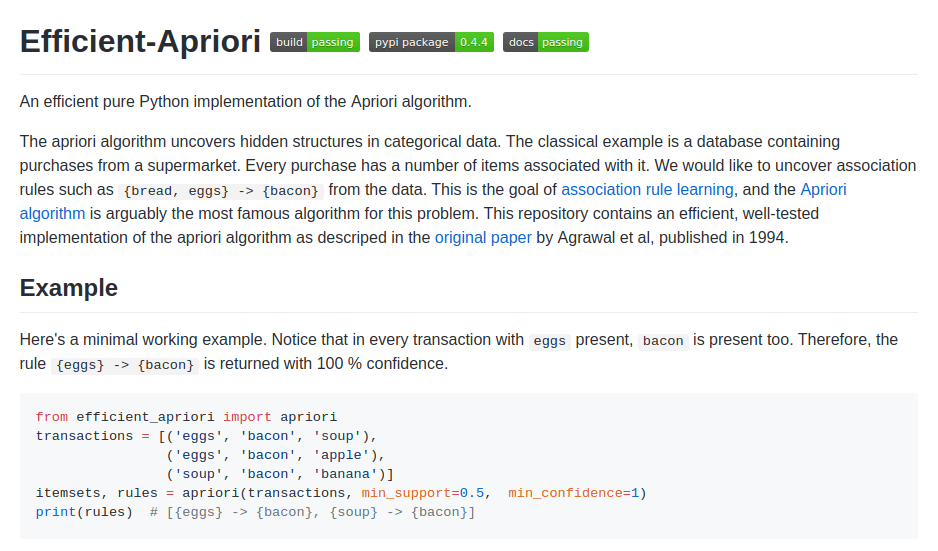
但是,正如您在屏幕截图中看到的那样,使用它需要编程技能。
另外,请查看我们的电子商务提示 →