
是 Spark 用于 Nosql
已发表: 2023-02-05Spark 是处理数据,尤其是大型数据集的强大工具。 它旨在快速高效,并且支持多种数据格式,包括NoSQL 数据库。 NoSQL 数据库正变得越来越流行,因为它们非常适合处理大量数据。 Spark 可以帮助您高效地查询和操作 NoSQL 数据。
为了有效地工作,使用 Apache Spark 和 NoSQL( Apache Cassandra和 MongoDB)管理应用程序的数据库至关重要。 此博客的目标是提供使用 NoSQL 后端开发 Apache Spark 应用程序的技巧。 这是一个主题公园,TCP/IP sPark 在 CassandraLand 和 MongoLand 都有游乐设施。 当我们尝试查询 DOE 数据时,我们的 Spark 应用程序开始自旋偏离轴心。 这里的教训是,当您查询 Cassandra 时,键序列很重要。 CassandraLand 还提供 Partitioner 过山车,这是其最受欢迎的景点之一。 当客户享受他们的过山车之旅时,乘车运营商可以通过保留他们的信息来跟踪每天乘坐过山车的人。
在第一课中,我们将介绍如何管理 MongoDB 连接。 当您需要更新有关公园的信息时,例如能源部的新公园成员身份,您可以使用mongo 索引。 应该使用 MongoDB 和 Spark 来确保正确管理您的连接,以及特定情况下的索引。
Apache Spark 是一种流行的分布式处理系统,它是开源的,专为处理大数据工作负载而构建。 除了内存缓存和优化的查询执行之外,此功能还支持对大量数据进行快速分析查询。
使用几乎相同的代码,它更加高效和通用,允许它同时处理批处理和实时数据。 因此,较旧的大数据工具由于缺乏此功能而变得越来越过时。
Spark 是什么类型的数据库?
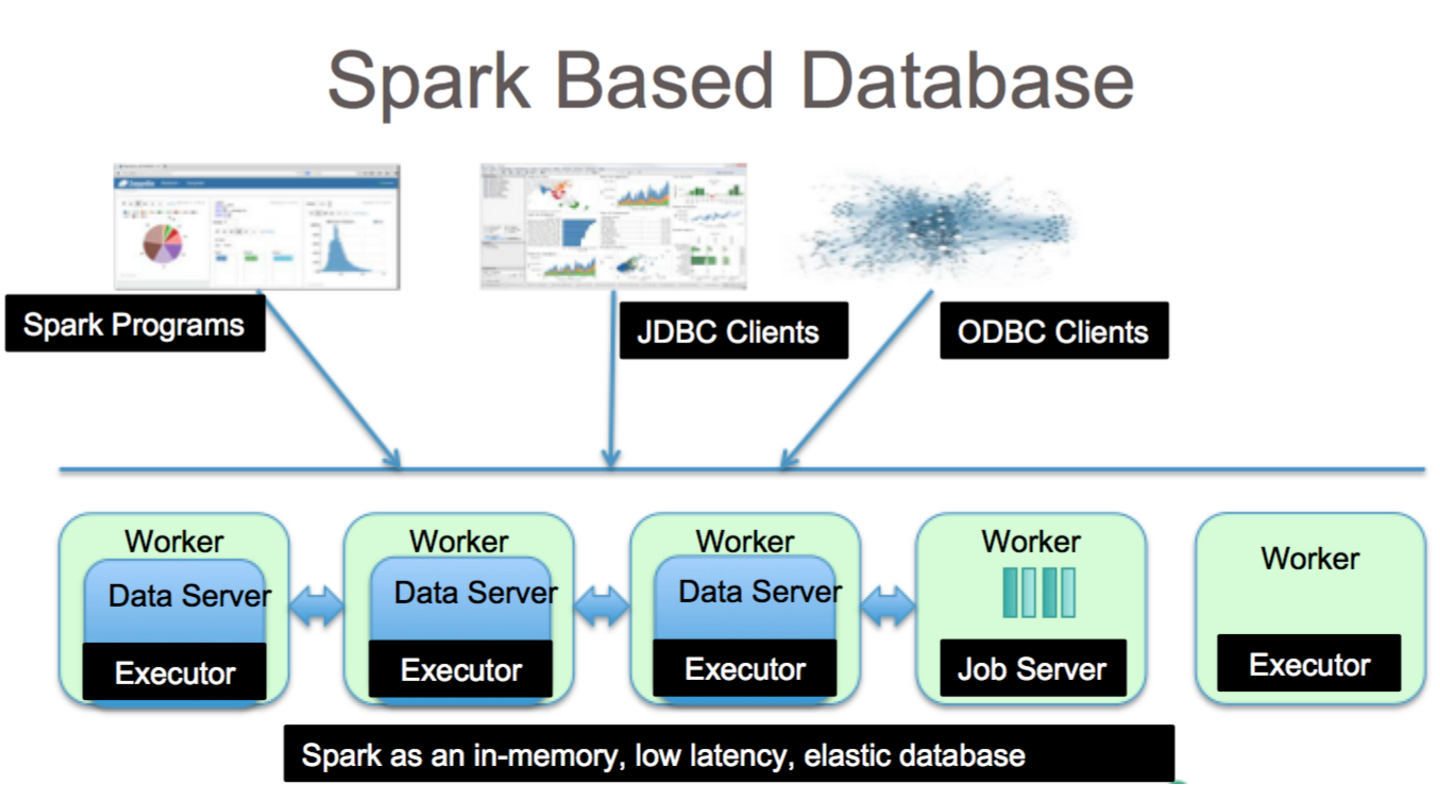
Apache Spark 是一个数据处理框架,可以处理来自各种数据存储库的数据,包括 (HDFS)、NoSQL 数据库和关系数据库。
尽管关系数据库已经出现了无数次炒作周期,但无论 NoSQL 数据库的最新进展和兴起如何,它们都将继续流行。 随着时间的推移,在关系数据库中存储数据变得越来越困难。 在本文中,我们将了解在全球范围内利用关系数据库的强大功能所取得的一些重大进展。 首次发布时,Spark 和大数据分析之间的接口很少。 很多人为了运行这个功能强大但比较慢的程序写了很多代码。 用户将能够轻松地将这两个模型结合到Spark SQL数据库中。 它还接受来自各种来源的各种数据格式。
Apache Spark 开源项目是最活跃的,有数百名贡献者参与其中。 除了作为一个免费的开源项目,Spark SQL 已经开始在主流行业中流行起来。 除了 Spark SQL 之外,大约三分之二的 Databricks Cloud 客户(运行 Spark 的托管服务)使用其他编程语言。 在我们的第一个案例研究结束后,我们将在这个实践案例研究中演示如何将数据块应用到案例中。 Spark DataFrame是一组以相同模式分布的行(行类型)。 数据集中的每一列都标有名称。 DataFrame 的 API 允许开发人员集成过程代码和关系代码。
Spark 还可以处理 UDF 等高级功能。 关系数据库中的表类似于数据框数据库中的数据框,但涉及更多优化。 它们的操作方式与 Spark 的原生分布式集合 (RDD) 相同。 总的来说, Spark SQL 查询比 Shark 查询更快,与 Impulsa 相比更具竞争力。 在查询 3a 中,查询选择性导致其中一个表非常小,Impala 和 Impala 之间存在显着差异。

它是使用 Spark SQL 进行数据分析的绝佳工具。 可以通过 HiveQL 语法以及 Hive SerDes 和 HiveDF 访问 HiveQL 语法、Hive SerDes 和 HiveDF。 Hive metastores 、SerDes 和 UDF 已经实现。 尽管 Spark 是一个数据库,但它也是一个 NoSQL 数据库。 因此,当您在 Spark 中创建托管表时,您将能够使用各种符合 SQL 的工具来存储您的数据。 通过 jdbc.org 的连接器连接到 JDBC,SQL 表达式可用于访问 Spark 中的表。 因此,您还可以使用 Tableau、Talend 和 Power BI 等第三方工具。 使用 Spark 的能力非常适合数据分析,它是适用于广泛行业的有用工具。
Spark Sql:两全其美
它通过包括两个主要组件弥合了前面提到的两个模型(过程模型和关系模型)之间的差距。 因此,您可以使用 DataFrame API 对外部数据源和 Spark 的内置分布式集合运行大规模关系操作。
数据库中的spark是什么? 它是一个使用机器学习、交互式查询处理和实时工作负载的开源框架。 该公司没有自己的存储系统; 相反,除了自己的存储系统之外,它还对其他存储系统(例如 HDFS、Amazon Redshift、Amazon S3、Couchbase 等)进行分析。 在结构化数据处理方面,Spark SQL 不仅仅是一个数据库; 它也是一个模块。 其中绝大部分是在 DataFrame 上编写的,DataFrame 是与 SQL 查询结合使用的编程抽象。
“sparksql”的SQL sql类型是什么? Hive SQL 支持 HiveQL 语法,以及 Hive SerDes 和 UDF,允许您访问之前创建的 Hive 仓库。 在 Spark SQL 中使用现有的 Hive 元存储、SerDes 和 UDF 并不困难。
Mongodb 可以运行 Spark 吗?
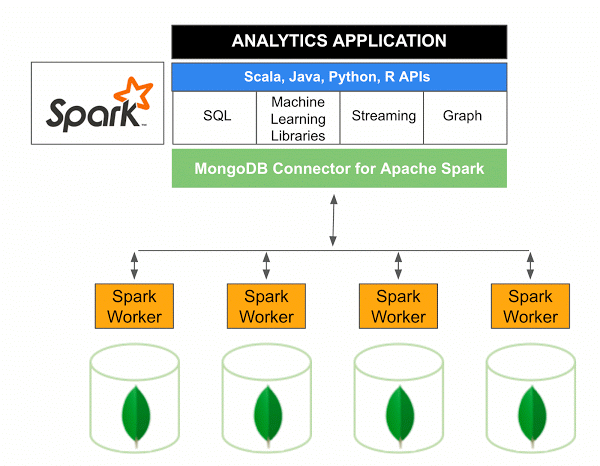
适用于 Apache Spark 的 MongoDB Connector 10.0 版包括通过新的 Spark Data Sources API V2支持 Spark Structured Streaming 以及新的 Spark Data Sources API V2 的实现。
用于 Spark 的 MongoDB 连接器是一个开源项目,允许您使用 Scala 从 MongoDB 写入数据并从 MongoDB 读取数据。 由于连接器的实用方法,简化了 Spark 和 MongoDB 之间的交互,使其成为创建复杂分析应用程序的强大组合。 使用其内置的复制和分片功能,Spark 可以在使用MongoDB 数据库的各种工作负载中实施。
Spark:构建数据丰富的应用程序的快速方法
借助Spark这个强大的工具,您可以快速开发更多功能的应用程序。 通过合并 MongoDB,开发人员可以利用单一数据库技术加快开发过程。 此外,Spark 是云原生的,包括对NoSQL 数据存储的支持,使其成为数据密集型应用程序的理想选择。