
NoSQL 数据库:Impala
已发表: 2023-03-03NoSQL 是一个术语,用于描述不使用传统关系数据库结构的数据库。 相反,NoSQL 数据库通常旨在提供更简单、更具可扩展性的解决方案。
Impala 是一个 NoSQL 数据库,旨在为管理大型数据集提供快速、可扩展的解决方案。 Impala 基于 Google Bigtable 数据模型并使用列式存储格式。 Impala 可作为开源项目使用,并受 Cloudera 支持。
Apache Impala 是一个开源的 SQL 查询引擎,安装在 Hadoop 集群上,对存储在系统上的数据执行大规模并行处理 (MPP)。 这个开源项目最初于 2012 年开发,被称为“Microsoft Formula 1”。
Impala 平台使用户能够对存储在 HDFS 和 Apache HBase 中的Hadoop 数据执行低延迟 SQL 查询,而无需移动或转换数据。
Impala 是基于 SQL 的吗?
Impala 是一个基于 SQL 的查询引擎,运行在 Apache Hadoop 上。 它允许用户使用 SQL 查询存储在 HDFS 和 HBase 中的数据。 与 Hive 和 Pig 等其他Hadoop 查询引擎相比,Impala 提供高性能和低延迟。
Impala 分析 MPP 数据库提供业内最快的洞察时间。 它与 CDH 集成在一起,可以通过 Cloudera Enterprise 访问。 适用于 Apache Hadoop 的 MPP 数据库(例如 Impala)使用 HDFS 来提供更快的洞察时间。
Impala 是一个数据库
我相信这是一个数据库。
Impala 是 Etl 工具吗?
Impala 不是一个 ETL 工具,它是一个 SQL 查询引擎,可用于在数据经过某个流程清理后进行 SQL 查询。
Apache Impala 的用途是什么?
使用类似 SQL 的查询,我们可以使用 Impala 从各种来源读取数据。 在访问存储在Hadoop 分布式文件系统中的数据时,Apache Impala 的性能优于 Hive 和其他 SQL 引擎。 我们使用 Impala 将数据存储在 Hadoop HBase、HDFS 和 Amazon S3 中。
19 家在其技术堆栈中使用 Apache Impala 的公司
Apache Impala 是一种流行的数据处理引擎,适用于各种大型企业。 据报道,包括 Stripe、Agoda 和 Expedia.com 在内的 19 家科技公司都在使用 Apache Impala。 Impala 平台灵活高效,能够快速有效地处理大型数据集。 这个工具的广泛使用证明了它的用处,以及它在数据处理方面的用处。
Sql Hive 和 Impala 有什么区别?
Hive 的目标是处理需要多次转换和连接的长时间运行的查询。 由于其低延迟和处理较小查询的能力, Impala 查询处理引擎是交互式计算的理想选择。 除了短期和长期查询外,Spark 还支持短期和长期查询。
Hive 更适合长时间运行的批处理作业
这些工具的主要目的不是处理批次。 Hive 比 Impulsa 更适合长期的批处理工作,Impulsa 可以处理较小的数据集。
Impala 是数据库吗
Impala 是一种以柱状格式存储数据的数据库。 它旨在可扩展并为大型数据集提供高性能。
在 Impala 初始版本中,支持以下核心列数据类型:STRING、VARCHAR、VARCHar2、INT 和 FLOAT 而不是数字,并且不支持 BLOB 类型。 Impala SQL-92 包括一些 SQL 标准的标准增强,但它并没有包含所有这些。 当数据太大而无法在单个服务器上生成、操作和分析时,Impala 的性能优于其他数据仓库,并且具有更高的可扩展性。 加载 Impala 时无需删除数据文件的原始位置,因为它是轻量级的。 了解性能测试、可扩展性和多节点集群配置的第一步通常是收集大量数据。 Cloudera Impala 针对大型数据集中的数据加载和批量读取进行了优化,让您事半功倍。 HDFS 的多兆字节块大小允许 Impala 跨多个联网服务器并行处理大量数据。
您无需规划规范化索引以及创建它们所需的时间和精力,而是在 Impala 中完成。 Impala 的查询引擎可以处理来自数据仓库的大量数据。 它分析集群并在节点之间分配任务,以减少消耗的资源量。 数据仓库的分区是 Impala 中一个熟悉的概念。 分区减少了磁盘 I/O 并增加了 Impala 中的查询可扩展性。 需要数据文件,因为您将无法访问 Impala 中的任何内置表。 INSERT 是可用选项之一。
要构建两个玩具表,请使用价值声明。 如果你一直在使用面向批处理的软件,你可以试一试。 您可以将 SQL-on- hadoop 技术合并到 Apache Hive 配置中。 Impala 中的 Hive 表不会以耗时的方式加载或转换。
Impala:一个强大的 Hadoop 数据管理工具
SQL 语法是 Impala 用户所熟悉的,它可以查询存储在 HDFS 和 Apache HBase 中的数据。 这样就可以使用Hadoop和Impulsa,而不是传统的关系型数据库。 此外,由于其功能,它是一个强大的数据管理工具。 此外,它处理大型数据集的能力令人印象深刻,并且可以轻松处理它们。

大数据中的 Impala
Impala 是一个在 Apache Hadoop 上运行的开源 MPP SQL 查询引擎。 它对存储在 HDFS 和 HBase 中的数据提供快速、交互式的 SQL 查询。 Impala 旨在通过为存储在 HDFS 和 HBase 中的数据提供快速、交互式的 SQL 接口来提高 Apache Hadoop 的性能。
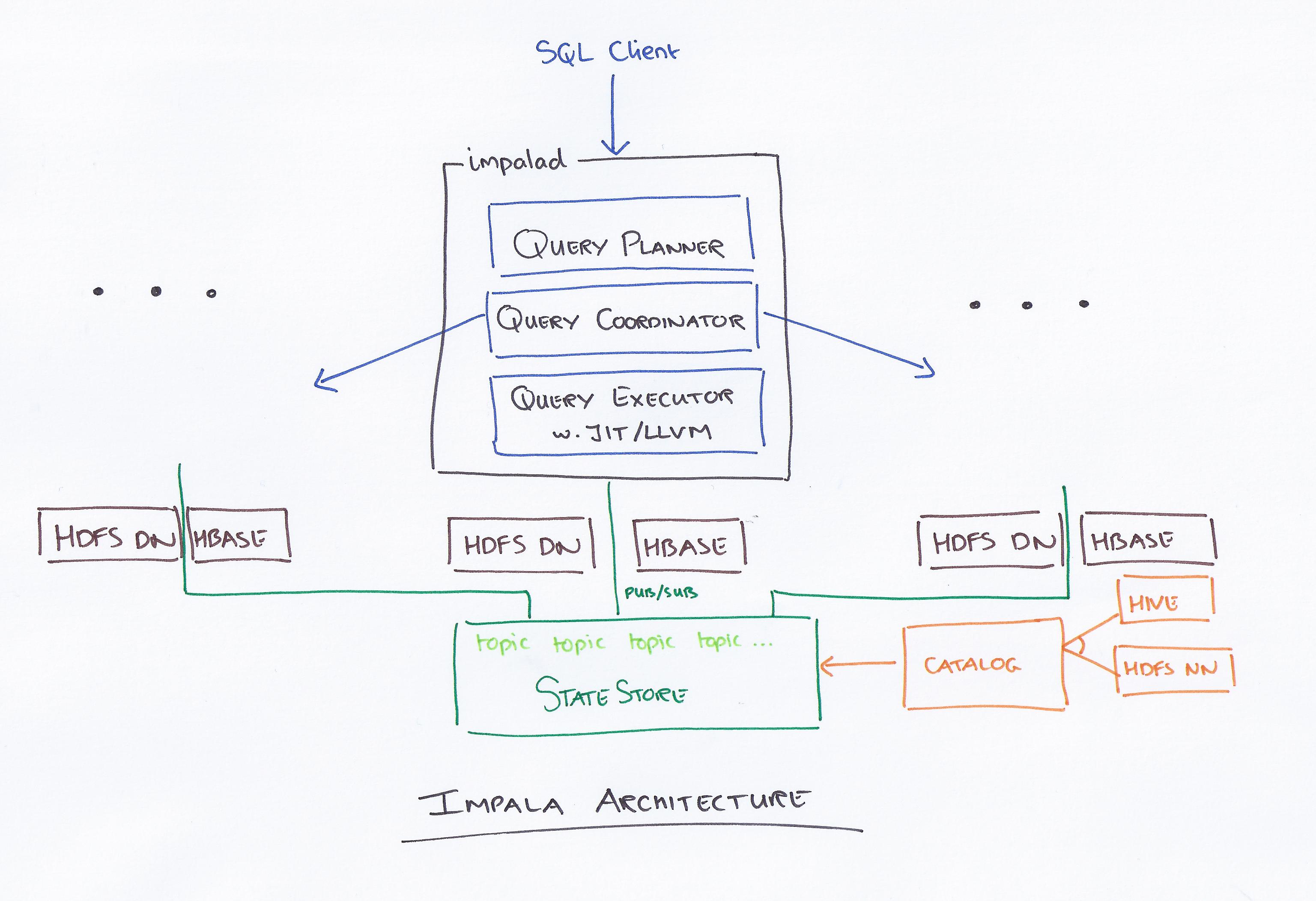
以Cloudera为首的Impala是一个新的查询系统。 Hadoop有HDFS和HBase,可以查询存储在那里的PB级大数据。 该技术基于Hive和内存进行计算,同时兼顾数据仓库,提供实时批处理和多并发处理。 客户端向 impalad 网络中的节点发送查询请求,其中返回查询 Id 以供后续客户端操作使用。 在分析器创建过程的第一步,会生成一个单机执行计划(单机计划、分布式执行计划),同时也会执行SQL,比如连接顺序的改变、谓词下推等。 所有节点都保留一份最新的元数据信息,以确保您不会被排除在外。 在使用Hadoop、Hive或Impurbia之前,您必须先安装必要的数据处理软件。
Impala 的配置文件可以更改。 每个节点都在 Impala 中执行配置更改。 所有节点负责将 MySQL 驱动程序包连接到数据库。 节点改变 Bigtop 的 Java 路径。
Hive 和 Impala 的比较
除了这三个主要差异之外,还有一些小差异。 在 Hive 中,有一个 HiveQL 的子集,而在 Implicit 中,有一个 HiveQL 的子集。 Hive和Impala分别用于数据仓库和交互式查询。 与 Impala 不同,Hive 不适合交互式计算。
Hadoop 中的 Impala 是什么
Impala 是一个开源 SQL 查询引擎,用于存储在 Hadoop 集群中的数据。 它旨在为存储在 HDFS、HBase 或任何其他Hadoop 数据源中的数据提供快速、交互式的 SQL 查询。
Impala 使用了广泛的熟悉的 Hadoop 组件。 INSERT 只能写入 Impala 可以读取的类型的数据,而 SELECT 可以读取 Impala 可以读取的类型的数据。 使用 Avro、RCFile 或 SequenceFile 文件格式时,数据将加载到 Hive 中。 除了表和列统计之外,还可以使用表统计和列统计。 如果所有 DDL 和 DML 语句是通过 catalogd 守护进程发送的,则它们会使用 Impala 1.2 和更高版本中的 catalogd 守护进程自动更新。 INVALIDATE METADATA 方法返回元存储中已访问的所有表的元数据。 数据文件存储在新表的目录中,并且在 Impala 运行时无论文件名如何都被读取。
总体而言,Apache Hive 作为数据仓库平台表现良好,而 Impala 更适合并行处理。 Hive 是容错的,而 Impulsa 不是。
阿帕奇黑斑羚
Apache Impala 是一种用于 Apache Hadoop 的快速交互式 SQL 查询引擎。 它使用户能够对存储在 HDFS 和 Apache HBase 中的数据发出低延迟 SQL 查询,而无需数据移动或转换。
Impala 的架构概念使其能够比任何其他查询引擎更有效地处理使用 HDFS 的交互式查询。 Hive 由于其磁盘 I/O 操作而慢得多,但 Apache 快得多,因为它是一个完全不同的引擎。 Impulsa 和 Presto 之间没有区别,因为 Impulsa 使用更快的技术而 Presto 使用类似的架构。 对于 Parquet 文件,Impala 表现最好。 根据分析师的查询确定应该对哪些数据进行分区。 使用 Compute Stats Statistics,您的查询将变得更加容易,尤其是当它们涉及多个表(连接)时。 我们的 Impala 目录服务器每周崩溃四次,我们的查询花费了太长时间才能完成。
此外,我们创建的文件数量极大地影响了我们的查询性能。 因此,我们开始管理我们的分区并将它们合并为大约 256MB 的最佳文件大小。 据说每个分区只有一个文件(除非它的大小> 256MB)。 应从隐式支持的所有数据类型中选择最合适的列类型。 要限制并发查询的数量或用户访问的 Y 内存,请使用 Impala Admission Control。 如果一个查询持续超过 30 分钟,它就被认为是死的。
大数据的最佳引擎:Impala
Impala引擎是专门为大型集群设计的Hadoop数据处理引擎。 与 Hadoop 的标准 MapReduce 引擎相比,它使用的能源和消耗的资源要少得多。 Implicit 采用分布式文件系统 HDFS 作为其主要数据存储介质,依靠 HDFS 的冗余来防止逐个节点的硬件或网络中断。 表示表数据的数据文件在物理上由熟悉的 HDFS 文件格式和压缩编解码器表示。
并行处理查询引擎
并行处理查询引擎是一种数据库引擎,旨在并行处理查询。 这可以通过使用多个处理器、多个内核或多台机器来完成。 并行处理可以极大地提高查询引擎的性能,尤其是对于复杂的查询。
多处理器计算机用于将复杂的查询转换为可以并发执行的执行计划,使其能够一次处理大量数据。 高性能需要高效的执行,例如良好的查询响应时间或高查询吞吐量。 它是通过使用高效的并行执行技术和查询优化来实现的。
并行处理:Etl 的未来?
高级查询可以转换为执行计划,该执行计划可以由多处理器计算机使用并行查询处理有效地执行。 并行处理采用并行和分布式数据相结合的技术,以及并行数据库系统提供的各种执行技术。 ETL中的并行查询处理是通过将分配给transfer的每个源表中的记录集划分成大小相同的chunk,然后循环对每个源表进行数据转换过程,连续选择数据,逐个chunk .