
Pig:Apache Hadoop 的高级平台
已发表: 2023-02-22Pig 是一个高级平台,用于创建在 Apache Hadoop 上运行的程序。 术语“Pig”指的是平台的基础设施层,它由编译器和执行环境以及一组高级运算符组成。 Pig 的基础设施层为开发人员提供了一组工具来创建、维护和执行他们的 Pig 程序。 Pig 是一个开源项目,是Apache Hadoop 生态系统的一部分。 Pig 的编程模型是基于数据流的,这使得编写处理大量数据的程序变得容易。 Pig 程序由一系列在有向无环图中执行的运算符组成。 Pig 是处理大量数据的绝佳选择,因为它可扩展、高效且易于使用。
作为 NoSQL 解决方案,您需要特定的预定义方法来分析和访问数据。 SQL(UNION、INTERSECT 等)是一种常见的查询表达式,在大数据领域中使用得并不多。 因为 Hive 针对批处理和大数据处理进行了优化,所以最好接触每一行。 Hive 在操作上花费的时间和金钱远少于 Hadoop,后者具有规模优势。 即使是开发系统上的小查询也可能比 RDBMS 上的类似查询慢 ORDERS 个数量级。 Hive 不缓存查询结果。 重新提交重复查询是 MapReduce 中的常见做法。
Hive有两种类型:1)Hive不是数据库; 相反,它是一个查询引擎,支持特定于查询数据的 SQL 部分 b) Hive 是一个支持 SQL 的数据库 c) Hive 是一个特定于 SQL 的数据库。 Hive 是一个基于 SQL 的 Hadoop 数据仓库系统,包括 Pig 和 Python 等; Hive 用于存储Hadoop 数据。
Pig 是 SQL 吗?
这个问题没有正确或错误的答案,因为它取决于个人意见。 有些人可能认为 pig 是一个 sql,而其他人则可能不这样认为。 pig是不是sql,归根结底还是由个人决定。
如今, Apache Hive和 Pig 这两个术语正迅速成为大数据的同义词。 借助这些工具,数据开发人员和分析人员可以使用它们来降低 MapReduce 的复杂性,同时仍保持高水平的数据完整性。 Hive 是一种数据仓库基础设施,也称为 ETL(提取、加载和转换)工具。 Apache Hive、Pig 和 SQL 是三种流行的数据分析和管理工具。 您必须了解哪个平台最适合您的需求,以及您应该多久使用一次。 让我们看看在这三种技术的上下文中使用 Hive、Pig 和 SQL 的三种不同方式。 尽管 Apache Hive 和 Apache Pig 占据主导地位,SQL 仍然是大数据管理和分析领域的王者。 因为每个人都执行特定的功能,所以他们的要求是根据业务量身定制的。 Apache Pig 基于脚本并需要特殊知识,而 Apache Hive 是开发人员唯一的原生数据库解决方案。
猪是一种多才多艺的动物,具有很大的灵活性。 例如,Pig 可以处理包含 JSON 或 XML 数据的日志文件,从而允许您读取数据。 也可以在 Pig 中存储来自 Web 服务的数据。
地图数据类型、元组和包数据类型可以互换使用。 他们能够处理来自任何来源的数据。
Pig 是 Etl 工具吗?
这个问题没有明确的答案,因为它取决于您如何定义 ETL 工具。 一般来说,ETL 工具是一种软件应用程序,可帮助您从一个或多个来源提取数据,将其转换为与目标系统兼容的格式,并将其加载到该系统中。 有人会说 pig 是一个 ETL 工具,因为它可以执行所有这些功能。 其他人可能会争辩说 pig 不是 ETL 工具,因为它不是专门为数据转换而设计的。 最终,这个问题的答案取决于您自己对 ETL 工具的定义。

如何使用 Pig 进行 Etl 处理?
Pig 应用程序可以被描述为一个 ETL 事务模型,它描述了一个过程如何从一个对象中提取数据并将其转换为基于规则集的数据存储。 用户定义 Pig 的用户定义函数 (UDF),以便从文件、流和其他来源摄取数据。
什么是 Pig 工具?
称为 Pig 的平台或工具处理大型数据集。 该库包含用于在 MapReduce 过程中处理数据的高级抽象。 Pig Latin 是一种高级脚本语言,在编码过程中用于开发数据分析代码。
Pig和Sql有什么区别?
SQL Pig Latin和 Apache Pig 是过程语言。 SQL 是一种本质上是声明性的脚本语言。 是否使用模式完全取决于 Apache Pig。 无需架构即可存储数据(值类型存储在 $、$ 等中)。
Pig 是 Hadoop 的一部分吗?
Pig Hadoop 应用程序是一种高级编程语言,可用于分析海量数据集。 Yahoo! 的 Pig Hadoop 项目是最早的 Hadoop 项目之一。 通常,它在运行 Hadoop 时执行大量数据管理工作。
在大数据分析领域,Pig Hadoop 是一种高级编程语言。 为了使用 Apache Pig 分析数据,我们必须首先使用 Pig Latin 编写脚本。 将转换为MapReduce 任务的脚本。 这是通过使用 Apache Pig 扩展 Pig Engine 实现的。 按照以下步骤,您可以在 Linux/CentOS/Windows 上安装 Apache Pig(通过 VM 或 Cloudera)。 第一步是下载并安装 Apache Pig。 第二步是使用 bashrc 文件更改 Apache Pig 环境变量。
在第 3 步中,确定Pig 版本。 该文件移动后可以保存在其他目录中。 第五步是通过单击 Pig 命令启动 Grunt Shell(用于运行 Pig Latin 的脚本)。
为什么 Pig Latin 是最好的数据分析高级脚本语言
Pig Latin 数据分析代码是用高级脚本语言编写的。 它是一种类似于 SQL 的语言,旨在并行处理数据流。
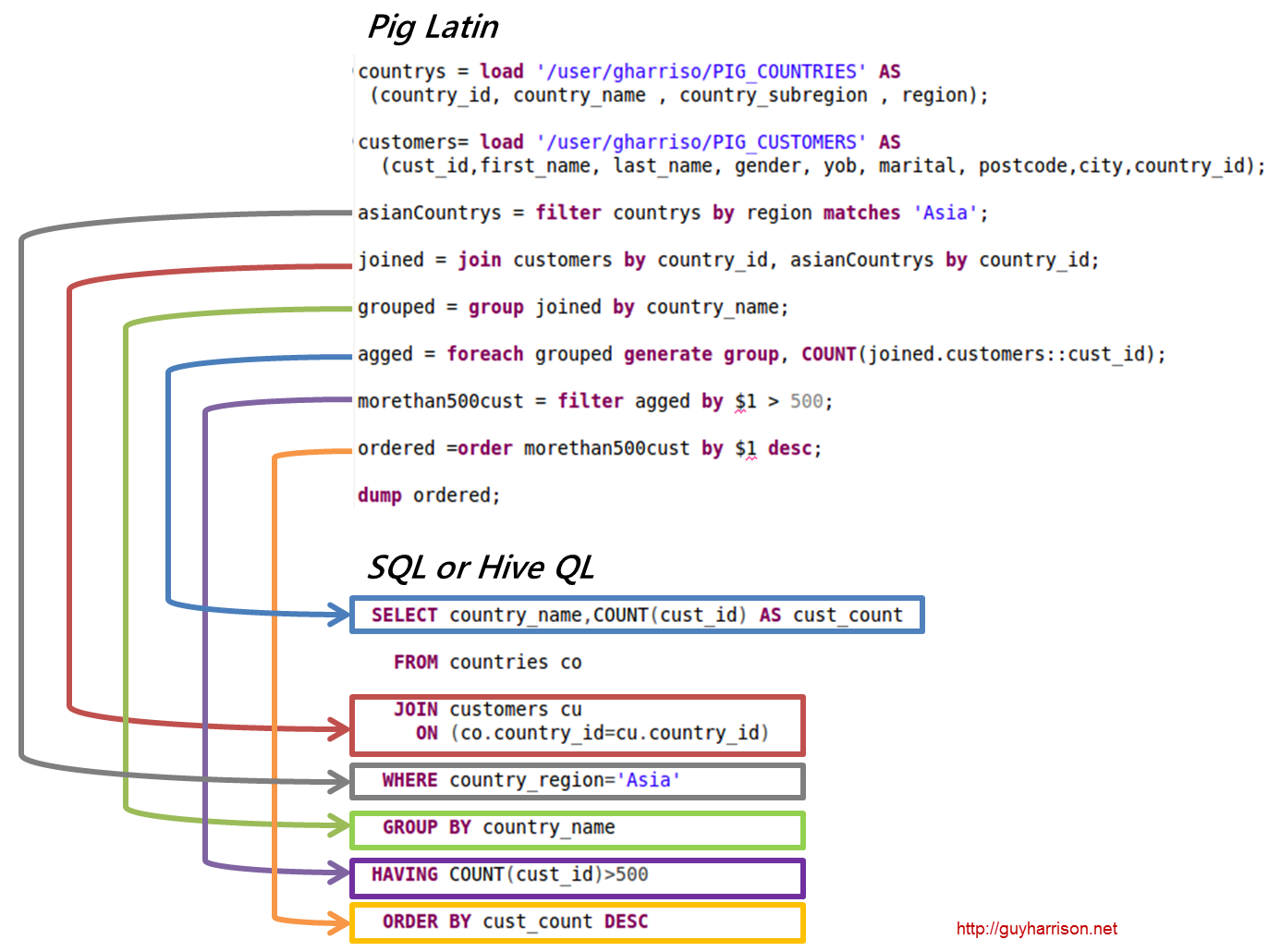
Apache Pig 示例
Pig 是一个高级平台,用于创建在 Apache Hadoop 上运行的程序。 这个平台的语言叫做 Pig Latin。 Pig 可以在 MapReduce、Tez 或 Spark 中执行其 Hadoop 作业。 Pig Latin 将编程从 Java MapReduce 惯用语中抽象为一种符号,使 MapReduce 编程更容易。 例如,下面的 Pig Latin 语句等同于上面的 Java MapReduce 代码: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); 倾倒一个;