
您需要了解的 5 个最佳开源法学硕士 [2023 年 12 月]
已发表: 2023-12-19概括:
通过 2023 年排名前 5 的开源大型语言模型 (LLM) 探索人工智能创新的前沿。从 Falcon 突破性的 180B 参数到 BLOOM 的多语言能力,深入研究塑造未来的尖端功能。 了解 Llama 2、GPT-NeoX-20B 和 MPT-7B 的优势和潜在应用,使企业能够在不断发展的 AI 领域安全扩展。
介绍
人工智能 (AI) 世界正在快速变化,其中很大一部分变化来自大型语言模型 (LLM)。 这些不仅仅是常规工具; 他们就像技术新阶段的领导者。 将它们视为真正的智能系统,正在改变我们使用手机、计算机和其他小工具的方式。
企业可以选择开源 LLM(大型语言模型)软件,而不是依赖 ChatGPT、Claude.ai 或 Phind 等外部聊天机器人服务来解决隐私和安全问题。 在您的计算机上运行开源 LLM 可确保敏感数据和机密信息保持在企业的控制范围内,从而最大限度地降低暴露于外部实体的风险。 这种方法在交互可能由人类审查或用于训练未来模型的平台上尤其重要。 通过在本地利用开源LLM软件,企业可以保持更高水平的数据安全性和机密性,解决与外部应用程序相关的潜在隐私问题。
令人兴奋的是,许多法学硕士都是开源的。 这意味着任何有兴趣和一些技术技能的人都可以使用它们、改变它们,甚至改进它们。 这就像拥有一个超级聪明的人工智能朋友,你可以向他学习并教授新技巧。

2023 年排名前 5 位的开源法学硕士
在这篇博客中,我们将介绍其中五个令人惊叹的开源法学硕士。 每一个都有其独特之处,为人工智能世界带来了新的想法和能力。
猎鹰法学硕士

Falcon LLM 是由阿布扎比技术创新学院 (TII) 开发的突破性大型语言模型 (LLM)。 它旨在推动应用程序和用例,确保我们世界的未来弹性。 该套件目前包含 Falcon 180B、40B、7.5B 和 1.3B 参数 AI 模型,以及精心策划的 REFINEDWEB 数据集。 他们共同提出了多样化且全面的解决方案。
以下是其主要特征、优势和潜在用途的全面细分,以及供进一步探索的相关来源:
主要特征:
- 海量:Falcon 180B 拥有 1800 亿个参数,拥有令人印象深刻的学习和性能能力,超过了其他几个开源法学硕士。
- 高效训练:在包含 3.5 万亿代币的精细数据集上进行训练,确保准确性和质量,同时优化资源使用。
- 开源可用性:代码和培训数据可在 Hugging Face 上公开获取,从而提高透明度和社区贡献。
- 卓越的性能:Falcon 在各种基准测试中均优于 GPT-3,同时需要更少的训练和推理资源,使其成为更高效的选择。
- 模型多样:TII提供各种Falcon版本,包括180B、40B、7.5B、1.3B参数AI模型,针对长篇故事写作等特定任务的专用模型。
优势:
- 高质量的数据管道:TII严格的数据过滤和重复数据删除流程确保Falcon的训练数据准确可靠。
- 多语言功能:Falcon 可以有效地处理多种语言,尽管它的主要重点是英语。
- 微调潜力:Falcon 可以针对特定任务进行微调,进一步增强其性能和适应性。
- 社区驱动的开发:开源性质允许协作改进和研究,加速 Falcon 的开发。
潜在应用:
- 自然语言处理(NLP):Falcon 可以在各种 NLP 任务中表现出色,例如文本摘要、情感分析和对话生成。
- 创意内容生成:该模型可以帮助作家和艺术家生成不同的创意格式,如诗歌、剧本和音乐作品。
- 教育和研究:个性化学习体验、教育内容生成和研究支持都是潜在的应用。
- 商业和营销:Falcon 可以为智能聊天机器人提供支持、个性化营销活动并有效分析客户数据。
其他资源:
- Falcon LLM网站:https://www.tii.ae/news/abu-dhabi-based-technology-innovation-institute-introduces-falcon-llm-foundational-large
- 抱脸猎鹰模型卡:https://huggingface.co/spaces/tiiuae/falcon-180b-demo
- TII Falcon 博客文章:https://huggingface.co/tiiuae/falcon-180B
- Falcon-180B 上的 YouTube 视频:https://www.youtube.com/watch?v=9MArp9H2YCM
美洲驼2

Llama 2 是由 Meta AI 和 Microsoft 开发的开源大型语言模型,展示了生成从诗歌到代码、回答问题和翻译语言等各种内容的卓越能力。 它在推理和编码基准方面优于其他法学硕士,通过强化学习强调安全性并提供“负责任的使用指南”。 虽然仍处于开发阶段,但用户应意识到潜在的不准确性、有偏差的输出以及需要技术专业知识才能实现最佳使用。 负责任的利用对于释放 Llama 2 彻底改变各个领域的全部潜力至关重要。
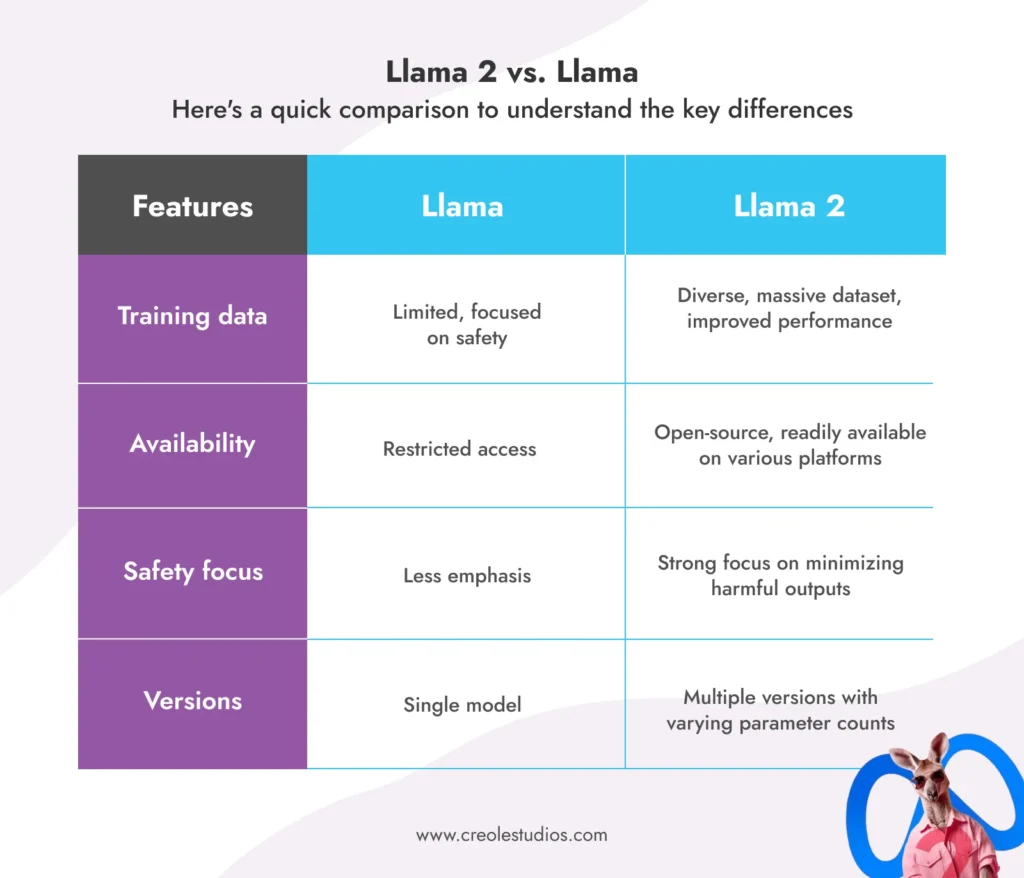
Llama 2 建立在原版 Llama 的基础上,在几个方面超越了其前身:
- 多样化训练:在更大且多样化的数据集上进行训练,确保更好地理解不同任务并提高性能。
- 开放可用性:与其前身的有限访问不同,Llama 2 可以随时在 AWS、Azure 和 Hugging Face 等平台上用于研究、开发甚至商业应用程序。
- 安全重点:Meta 通过采取措施尽量减少错误信息、偏见和有害输出,将安全放在首位。
- 增强训练:提供不同版本,参数数量从70亿到700亿,满足不同的需求和资源。
美洲驼 2 与美洲驼:
以下是一个快速比较,以了解主要差异:
Llama 2 的潜在应用:
- 聊天机器人和虚拟助手:改进的对话功能可以实现更自然、更有吸引力的交互。
- 文本生成和创意内容:生成不同的创意格式,如诗歌、脚本或代码,为作家和艺术家提供帮助。
- 代码生成和编程:帮助开发人员完成代码完成和错误检测等任务。
- 教育和研究:个性化学习体验、生成教育内容并协助研究人员完成各种任务。
- 业务和营销:通过聊天机器人增强客户服务、个性化营销活动并分析客户数据。
限制和注意事项:
- 与所有法学硕士一样,Llama 2 仍在开发中,可能会生成不准确或有偏差的输出。
- 负责任且合乎道德的使用对于避免潜在的滥用和偏见至关重要。
- 不同的版本需要不同的计算资源,因此选择正确的版本非常重要。
资源:
- Meta AI LLAMA 网站:https://ai.meta.com/blog/large-language-model-llama-meta-ai/
- 关于 LLAMA2 的 Meta AI 博客文章:https://ai.meta.com/blog/large-language-model-llama-meta-ai/
- Hugging Face LLAMA2 模型卡:https://huggingface.co/models?search=llama
布鲁姆法学硕士

Bloom LLM 诞生于全球社区的共同努力,已成为开源人工智能领域的真正力量。 以下是其主要功能、潜在应用及其独特之处的全面细分:
什么是 BLOOM LLM?
BLOOM 是一个庞大的多语言法学硕士,拥有 1760 亿个参数,并接受了惊人的 46 种语言和 13 种编程语言的培训。 BLOOM 是通过 Hugging Face 和来自 70 多个国家的研究人员为期一年的合作项目开发的,体现了开源人工智能的精神。

BLOOM 的主要特点:
- 多语言能力:以多达 46 种语言生成连贯且精确的文本,超越了典型的以英语为中心的模型。
- 开源访问:源代码和培训数据都是公开的,从而促进透明度和社区驱动的改进。
- 自回归文本生成:无缝扩展和完成文本序列,使其成为各种创意和信息任务的理想选择。
- 海量参数数量:BLOOM 拥有 1760 亿个参数,跻身最强大的开源 LLM 之列,提供卓越的性能。
- 全球合作:该模型的开发体现了国际合作在推进人工智能技术方面的力量。
- 免费访问:任何人都可以通过 Hugging Face 平台访问和使用 BLOOM,从而实现尖端 AI 工具的民主化。
- 工业规模培训:使用大量计算资源对大量文本数据进行培训,确保稳健的性能。
BLOOM 的潜在应用:
- 多语言交流:通过翻译文本和生成特定语言的内容来促进跨文化交流。
- 创意写作和内容生成:以诗歌、脚本、代码、音乐作品等多种形式协助作家和艺术家。
- 教育和研究:个性化学习体验、生成教育材料并支持各个领域的研究工作。
- 业务和营销:通过多语言聊天机器人增强客户服务、个性化营销活动并有效分析数据。
- 开源人工智能开发:作为开源人工智能进一步研究和开发的基础,促进社区创新。
BLOOM 有何独特之处?
- 多语言关注:与许多主要关注英语的法学硕士不同,BLOOM 的多语言能力为全球沟通和理解开辟了新的可能性。
- 开放性和透明度:公众对代码和培训数据的访问允许更广泛地参与改进和利用模型。
- 协作开发:该模型通过全球协作创建,展示了开源人工智能在弥合地理和文化障碍方面的潜力。
限制和注意事项:
- 与所有法学硕士一样,BLOOM 仍处于开发阶段,可能会生成不准确或有偏差的输出。 负责任且合乎道德的使用至关重要。
- 有效利用 BLOOM 需要一些技术知识并了解其功能。
- 该模型的大尺寸可能需要大量的计算资源来执行某些任务。
资源:
- BigScience BLOOM 网站:https://huggingface.co/bigscience/bloom-intermediate
- Hugging Face BLOOM 模型卡:https://bigscience.huggingface.co/blog/bloom
- BLOOM 上的 BigScience 博客文章:https://huggingface.co/bigscience/bloom
- GitHub 上的 BLOOM 模型卡存储库:https://github.com/bigscience-workshop/model_card
GPT-NeoX-20B

这是另一个崭露头角的开源法学硕士,展示了非凡的能力和潜力。 以下是其主要特性、优势和潜在应用的详细介绍:
什么是 GPT-NeoX-20B?
- GPT-NeoX-20B 由 EleutherAI 开发,是一个在 Pile(海量文本和代码数据集)上训练的 200 亿参数自回归语言模型。
- 其架构借鉴了 GPT-3,但进行了重大优化,以提高性能和效率。
- GPT-NeoX-20B 在多个领域表现出色:
- 少样本推理:在需要理解和应用有限示例中的信息的任务上表现得非常好。
- 长文本生成:即使对于很长的序列,也能生成连贯且语法正确的文本。
- 代码生成和分析:可以理解和生成代码,协助开发人员完成各种任务。
GPT-NeoX-20B 的优点:
- 开源:模型的代码和权重是公开的,鼓励社区贡献和研究。
- 高效训练:利用 DeepSpeed 库进行高效训练,与其他法学硕士相比,需要更少的计算资源。
- 强大的小样本学习:在数据有限的任务上表现出色,使其能够适应不同的场景。
- 长文本生成:即使对于冗长的序列也能生成连贯且语法正确的文本,非常适合创意写作和内容生成。
- 代码生成和分析:理解并生成代码,可能有助于开发人员进行错误检测、代码完成和其他任务。
GPT-NeoX-20B 的潜在应用:
- 个人助理和聊天机器人:增强理解和响应复杂问题和请求的能力。
- 创意写作和内容生成:协助作家和艺术家生成不同的创意形式,如诗歌、剧本、音乐作品等。
- 教育和研究:个性化学习体验、生成教育内容并支持各个领域的研究。
- 软件开发:协助开发人员完成代码完成、错误检测和代码分析等任务。
- 开源人工智能研究:作为开源人工智能进一步研究和开发的基础,促进创新。
限制和注意事项:
- 与所有法学硕士一样,GPT-NeoX-20B 仍在开发中,有时会生成不准确或有偏差的输出。 负责任且合乎道德的使用至关重要。
- 充分利用其潜力可能需要一些技术知识并了解其功能。
- 模型的大小可能需要大量的计算资源来执行某些任务。
资源:
- EleutherAI GitHub 存储库:这是 GPT-NeoX-20B 的官方存储库,您可以在其中找到源代码、训练脚本和预训练模型。 (来源:https://github.com/EleutherAI/gpt-neox)
- Hugging Face 模型卡:Hugging Face 模型卡提供了 GPT-NeoX-20B 的全面概述,包括其功能、限制和基准测试结果。 (来源:https://huggingface.co/EleutherAI/gpt-neox-20b)
- EleutherAI 博客文章:EleutherAI 的这篇博客文章介绍了 GPT-NeoX-20B,讨论了其架构和训练过程,并重点介绍了其一些潜在应用。 (来源:https://www.opensourceforu.com/2022/04/eleutherai-releases-gpt-neox-20b-a-20-billion-parameter-ai-language-model/)
MPT-7B

MPT-7B是 MosaicML Pretrained Transformer 的缩写,是由 MosaicML Foundations 开发的功能强大的开源 LLM。 它拥有 70 亿个参数,并接受了 1 万亿个代币的海量数据集的训练,使其成为 LLM 领域的有力竞争者。 以下是其主要功能和潜在应用的细分,以及一些供进一步探索的相关来源:
主要特征:
- 商业许可:与许多开源模型不同,MPT-7B 获得商业用途许可,为企业利用其功能打开了大门。
- 广泛的训练数据:MPT-7B 在 1 万亿个代币的多样化数据集上进行训练,确保了跨各种任务的稳健性能和适应性。
- 长输入处理:该模型可以在不影响准确性的情况下处理极长的输入,使其成为总结冗长文档等任务的理想选择。
- 速度和效率:MPT-7B 针对快速训练和推理进行了优化,可及时提供结果,这对于实际应用至关重要。
- 开源代码:该模型高效的开源培训代码提高了透明度并促进社区为其开发做出贡献。
- 卓越对比:与 7B-20B 参数范围内的其他开源模型相比,MPT-7B 表现出了卓越的性能,甚至可以与 LLaMA-7B 的质量相媲美。
潜在应用:
- 预测分析:MPT-7B 可以分析大型数据集以识别模式和趋势,为业务决策提供信息并优化运营。
- 决策支持:该模型可以根据分析的数据提供见解和建议,从而协助复杂的决策过程。
- 内容生成和摘要:MPT-7B可以生成不同的创意文本格式,如诗歌、脚本或代码,或有效地总结长文档。
- 客户服务聊天机器人:通过理解自然语言和上下文,MPT-7B 可以为智能聊天机器人提供支持,以改善客户服务体验。
- 研究与开发:该模型可以通过分析数据、生成假设和协助创造性探索来支持各个领域的研究工作。
其他资源:
- MosaicML MPT-7B 网站:https://www.mosaicml.com/blog/mpt-7b
- Hugging Face MPT-7B 模型卡:https://huggingface.co/mosaicml/mpt-7b
- MPT-7B 上的 MosaicML 博客文章:https://www.mosaicml.com/blog/mpt-7b
利用 Creole Studios 的开源法学硕士
开源大型语言模型 (LLM) 正在重塑人工智能,为企业提供灵活性和创新。 它们非常适合创建新技术解决方案和降低开发成本。 然而,数据隐私和针对特定业务需求的定制等挑战可能很复杂。
Creole Studios 是您应对这些挑战的理想合作伙伴。 我们在人工智能和机器学习方面的专业知识意味着我们可以帮助您的企业高效、安全地利用开源法学硕士的全部潜力。 我们专注于创建符合您独特目标的定制解决方案,确保您在快速发展的人工智能领域保持领先地位。
与 Creole Studios 合作,利用开源法学硕士的力量改变您的 AI 之旅。