
Google 的 Bigtable:使用最廣泛的列式數據存儲
已發表: 2022-12-19Bigtable 是由 Google 創建的面向列的數據存儲。 它旨在以高度的靈活性處理大量數據。 Bigtable 已被谷歌使用十多年,並且是其許多服務的基礎,包括 Gmail、谷歌地圖和 YouTube。 雖然 Bigtable 不是第一個面向列的數據存儲,但它肯定是使用最廣泛和知名度最高的。
在本文中,我們將研究 Bigtable 開發的三維 NoSQL 存儲模型。 為了驗證它的結構是否正確,我們將首先從理論上看它是如何實現的,然後使用 Node.js 客戶端來實現。 Bigtable 中的存儲模型與您可能在類似數據庫中找到的方式不同。 行/列組合中的多個單元格可以按每個單元格的時間戳排序。 不是以任意順序保存單元格,每個單元格都有值和時間戳以確保單元格以有序順序保存。 對於此示例,我們將使用 Node.js 和純 JavaScript 來構建 Google Cloud Bigtable。 在本文中,我們將介紹如何使用代碼創建一個新的 Bigtable 實例。
我們首先創建一個乾淨的環境,在上面讀寫,然後拆除它。 使用 Node.js Bigtable 客戶端運行代碼時,Node.js Bigtable 客戶端可能會導致權限被拒絕錯誤並生成一個鏈接以啟用 Cloud Bigtable Admin API。 您還應該在 GCP 項目上建立一個單獨的服務帳戶來處理 Bigtable 管理員角色。 要創建 Bigtable 表,我們必須首先構建一個數據庫實例和一個表集群。 只需在 Node.js 客戶端中定義一個表 ID 和一個列族來執行此操作,就可以開始了。 可以通過在數據庫中使用 Bigtable 創建簡單的行。 查詢數據的唯一方法是使用行鍵來查詢特定的行或一組行。
儘管攝取時間與版本的存儲順序無關,但它們確實會影響它們的存儲方式。 不需要提供整個行鍵; 只需一個前綴就足夠了。 當您需要從 Bigtable 查詢多行時,我總是建議使用流式處理。 使用流式傳輸時,Bigtable 不必在發送行之前在服務器上緩衝數據,從而提高性能。 過濾器可用於限制單元格版本,僅返回具有特定係列名稱的列或具有特定限定條件的列。 如果您要保留多個版本,但出於特定目的只需要最新版本,這將特別有用。 過濾器主要用於減少查詢和發送的數據量,以提高查詢性能。
換句話說,Cloud Bigtable 是一個專為分析和運營工作負載設計的NoSQL 數據庫。 該數據庫系統是一個跨平台混合體,它使用 Hadoop 而不是採用列式數據庫的 HBase。 雲 bigtable 可用於為具有高吞吐量和可擴展性的應用程序提供支持,容量小於 10 MB。
Apache Cassandra、ScyllaDB、Apache HBase、Google BigTable 和 Microsoft Azure CosmosDB 是寬列存儲的示例。
在鍵/值存儲方面,表與關係數據庫不同。 事務只能執行一次,不支持連接。
Google Bigtable 是 Nosql 數據庫嗎?
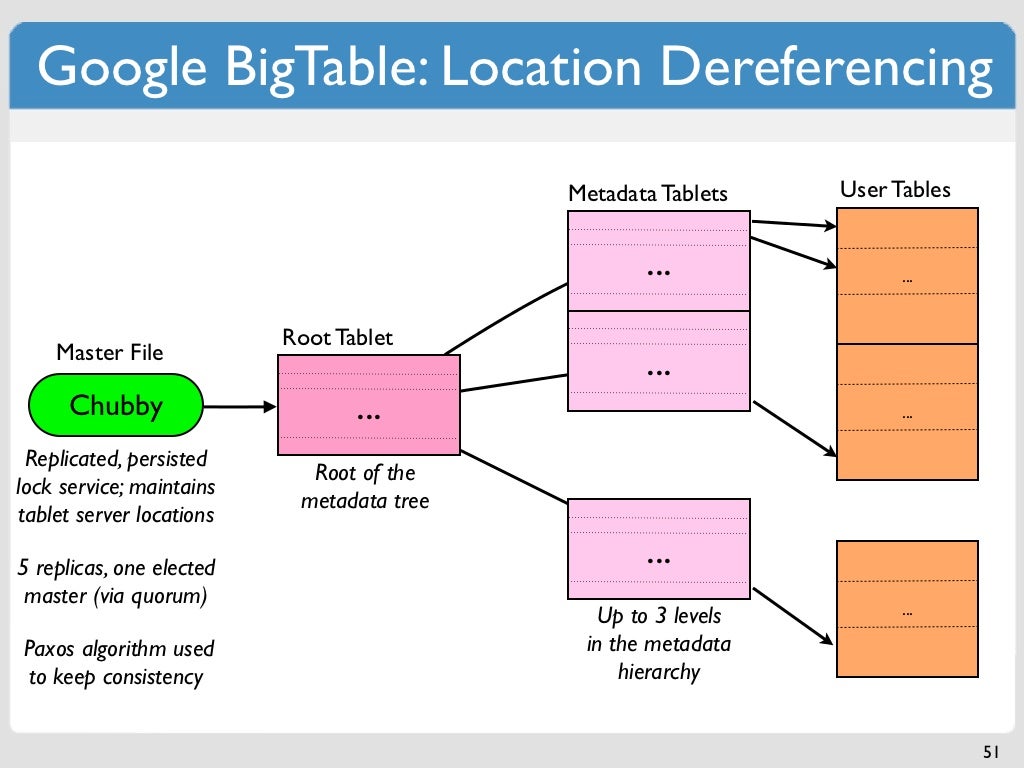
Google Bigtable 是一種 NoSQL 數據庫,專為存儲和管理大量數據而設計。 Bigtable 是一個面向列的數據庫,這意味著數據被組織成列而不是行。 這使得它非常適合存儲不斷變化的數據,例如網絡日誌或社交媒體數據。 Bigtable 還具有高度可擴展性,這意味著它可以輕鬆處理大量數據。
這種 NoSQL 數據庫可以存儲範圍廣泛的數據類型,並且極其穩定。 它還處理分片和復制,確保數據庫高度可用和可靠。 許多 Google 應用程序都使用它,包括 Google Analytics、Web 索引、MapReduce 和 Google Maps、Google Books、My Search History、Google Earth、Blogger.com、Google Code Hosting 和 Google 對於需要數據庫能夠處理大量數據的應用程序數據項的數量,Datastore 是一個不錯的選擇。
Bigtable 中的數據存儲順序是什麼?
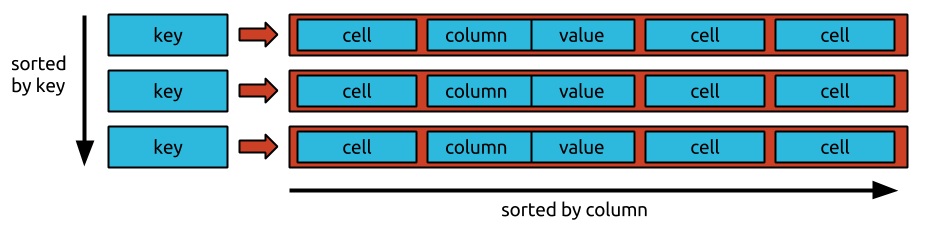
bigtable 中的數據存儲沒有特定的順序。 數據以隨機順序存儲,這使得訪問特定數據變得困難。
Google 的 Bigtable:不僅僅是為了存儲數據
數據不能以任何特定順序放置在 igtable 中。 因為 Bigtable 是一個面向行的數據庫,所以一行中的所有數據都組織在列中,然後是列。 因為數據是按時間倒序存儲的,所以請求最近的值簡單快捷,但請求最老的值困難且耗時。
由於 Bigtable 使用了 Colossus,您的數據保存在 Colossus 上,這是 Google 的內部持久文件系統,該系統位於 Google 的數據中心內。 Bigtable 是免費使用的,您不需要使用 HDFS 集群或任何其他文件系統。
可以在不使用命令 combine 創建永久表的情況下執行對外部數據源的查詢:具有查詢的表定義文件。 有一個內聯模式定義和一個查詢。 帶有查詢的 JSON 模式定義文件。
Bigtable 與數據存儲
Bigtable 和 Datastore 之間存在一些關鍵差異。 首先,Bigtable 是面向列的數據存儲,而 Datastore 是面向行的。 這意味著在 Bigtable 中,數據被組織成列,而在 Datastore 中,數據被組織成行。 其次,Bigtable沒有事務的概念,而Datastore有。 這意味著在 Bigtable 中,您無法將更改回滾到以前的狀態,而在 Datastore 中則可以。 最後,Bigtable 是為高吞吐量和低延遲而設計的,而 Datastore 是為高可用性和可擴展性而設計的。
可以使用哪個雲數據存儲來構建 Google 雲數據庫? 由於 Bigtable 支持具有復雜後端工作負載的大型工作負載,因此它適用於大型組織和企業。 與使用限制性更強的查詢語言 GQL 的 SQL 相比,數據存儲對稱為實體組的數據子集執行 ACID 事務(儘管查詢語言 GQL 更加開放)。 Google Cloud Datastore 和 Google Cloud Bigtable 是兩種截然不同的服務,它們具有許多截然不同的功能。 此外,下圖中的信息可以幫助您選擇適合您的服務提供商。 上面的答案,以及 Coursea Google Cloud Platform Big Data and Machine Learning Fundamentals 教科書中討論的內容,將作為我這篇文章的指南。
Bigtable 和 Datastore 有什麼區別?
數據存儲和數據庫有什麼區別? bigtable 和 datastore 都是為大容量數據處理和分析而設計的,而 datastore 則是為高價值的交易數據而設計的。 Datastore 也被稱為 NoSQL 數據庫,因為它不遵守傳統的 SQL 標準,允許它以更靈活和可擴展的方式保留數據。 Google Bigtable 是一種什麼樣的數據存儲? Bigtable 存儲模型將數據存儲在按鍵和值映射排序的可大規模擴展的表中。 表由行和列組成,每行描述一個實體,每列都有自己的值。 數據存儲是否已棄用? 由於 Cloud Datastore API v1beta3 已發布,因此不再可用。 儘管如此,Cloud Datastore 產品功能齊全且受支持。
大表數據庫
Bigtable 是一種分佈式存儲系統,用於管理結構化數據,旨在擴展到非常大的規模:跨越數千台商用服務器的 PB 級數據。 Bigtable 是一個面向列的數據庫,這意味著數據是按列存儲的,而不是按行存儲的。

該表是一個稀疏、密集的結構,其行和列可以達到數十億行。 bigtable 是存儲大量低延遲數據的絕佳選擇。 因為它支持低延遲的高讀寫吞吐量,所以它是適合 MapReduce 操作的數據源。 當使用 Bigtable 表時,它被分成稱為片的連續行塊,以使查詢更容易。 在谷歌使用的名為 Colossus 的文件系統中,平板電腦以 SSTable 格式存儲。 Bigtable 節點是每個 tablet 的子集,它是 Bigtable 實例的一部分。 向集群添加節點可以增加它可以處理的並發請求數。
一行包含一組鍵或值條目,它們是列族、列時間戳和鍵的組合。 Bigtable 以相同的方式處理所有數據:作為原始字節字符串。 因為Bigtable 按順序存儲突變並定期壓縮它們,所以在給定時間可以存儲的突變數量需要更多的存儲空間。 Bigtable 使用複雜的自動化算法壓縮您的數據。 因為刪除實際上是一種新類型的突變,它們在短期內需要更多的存儲空間。 谷歌專有的存儲方法使其能夠實現超過標準 HDFS 三向複製所實現的數據持久性。 除了管理對 Bigtable 表的訪問之外,您還可以通過在 Google Cloud 項目的身份和訪問管理 (IAM) 部分為用戶分配角色來管理對其他 Google Cloud 服務的訪問。 根據 Google Cloud 的默認加密策略,雲中的所有數據都使用我們用於加密數據的相同強化密鑰管理系統進行靜態加密。 使用備份,您可以保存表的架構和數據的副本,然後在將來將該數據副本恢復到新表。
Bigtable 與 Cassandra
Cassandra 和 Bigtable 使用不同的方法來確定應該由哪個處理節點執行讀寫操作。 在 Cassandra 中,分區鍵被稱為鍵,而在 Bigtable 中,行鍵被稱為鍵。 Cassandra 的負載平衡策略必須由客戶端作為流程的一部分進行審查。
分佈式數據庫是一個由多人共享的數據庫。 該公司在其係統中整合了多維鍵值存儲,使其能夠每秒處理數万個查詢 (QPS)。 本文檔的目的是比較和對比這兩個數據庫系統。 Bigtable 的主要功能包括: 創建了結構化數據分佈式存儲系統論文。 如果 Bigtable 確定數據集需要範圍重新平衡,則處理節點更改數據范圍很簡單,因為存儲層與處理層是分開的。 Bigtable 還可用於支持跨拓撲結構中最多四個集群的地理分佈式集群的異步複製。 Cassandra 的容錯能力與其可調一致性級別相關聯。
通過配置數據複製拓撲策略,您可以定義地理複製。 通常,使用 QUORUM(或某些數據中心中的 LOCAL_QUORUM)設置。 要被視為成功,操作的一致性級別設置必須滿足大多數副本節點對協調器節點的響應。 使用數據中心和機架配置,與傳統副本相比,Cassandra 的副本能夠承受更多壓力。 在進行讀寫操作時,拓撲決定了需要哪些節點來保證一致性。 一個 Bigtable 實例可以包含一個集群或一組最多四個大型副本。 Bigtable 和 Cassandra 是寬列存儲的NoSQL 數據存儲。
Bigtable 的行鍵用於按順序對錶中的全局數據進行排序。 作為 Bigtable 的節點功能的一部分,Bigtable 的節點會自動平衡關鍵範圍(也稱為平板電腦)的節點責任。 客戶端的Bigtable 服務不強制執行它發送的列數據類型。 在 Bigtable 中,表中的每一列都分配有一個家族名稱。 儘管表經常有更多的列族(每個表的最大列數為 100),但每個表至少需要一個列族。 行鍵交集由兩個單元格組成(一個列族與一個列限定符相結合)。 在Cassandra和Bigtable中,都有選擇讀寫操作的處理節點的方法。
在 Cassandra 中,分區鍵被識別,而在 Bigtable 中,使用行鍵。 了解數據中心的負載平衡策略(例如多集群策略)提供了故障轉移的可能性。 兩個數據庫都使用類似的方法來完成寫入,並針對速度進行了優化。 數據通過不可變的 SSTable 文件存儲在兩個數據庫中。 在 Cassandra 中,協調器必須在多個副本響應之前通知客戶端寫入已完成。 Bigtable 中的成功寫入只能通過一個節點的響應來確認,因為每個行鍵僅分配給一個節點。 合併後的 SSTable 中可能不包含任一數據庫中的單元格。
由於 CQL 查詢中的 WHERE 子句,在 Cassandra 中不可能返回多行。 在 Bigtable 中只需要查詢負責鍵範圍的節點。 在處理節點,可以限制可以讀取的數據量。 在compaction階段,SSTables會定期合併,Bigtable和Cassandra中存儲的數據存儲在其中。 沒有規則控制每個單元格的時間戳版本的數量,但可能有其他行大小限制。 Colossus 的複制系統提供數據持久性保證。 Bigtable 與 Cassandra 一樣,具有命令行界面和適用於許多常見編程語言的客戶端庫。
每個節點在 Bigtable 中都分配了一個 SSTable,存儲在其中的數據由該節點提供服務。 當您調整 Cassandra 集群的大小時,您不需要像使用 Bigtable 那樣考慮存儲副本。 固態硬盤 (SSD) 或硬盤驅動器 (HDD) 是Bigtable 實例最常用的存儲類型。 正如 Cassandra 所證明的那樣,實現容錯不會損失存儲密度。 可以以最少的工作量和最少的停機時間來擴展 Bigtable 實例以滿足工作負載要求。 雖然只有四個集群,但每個集群都可以在全球任何受支持的雲區域中創建。 Google 建議您使用具有代表性的數據和查詢來測試 Bigtable 的性能,以生成每個節點的 QPS 指標。
Cassandra 使用 Bigtable 託管組件執行大量管理功能。 大表備份創建表的可恢復副本,這些副本作為對象存儲在集群中。 備份消耗更少的節點資源並且比雲存儲更便宜。 另一種備份 Bigtable 的方法是使用託管數據導出到 Cloud Storage。 操作系統修補、節點恢復、節點修復、存儲壓縮監控和 SSL 證書輪換等內部維護任務都由 Bigtable 服務無縫處理。 儀表板可用於在Bigtable Google Cloud 控制台頁面中監控實例、集群和表級別的吞吐量和利用率指標。 您可以使用監控儀表板進行高級性能調優。
Bigtable 論文描述了一種支持大規模橫向擴展的數據存儲系統。 數據中的每個表被劃分為多個分區。 您可以使用行鍵或使用一系列行鍵來查詢表。 Bigtable 論文還描述了一種跨節點集群分佈表工作的方法。 Apache Cassandra 是一個開源數據庫,它基於 Bigtable 論文中的一些概念。 數據中心使用分佈式節點架構,其中存儲在服務數據的服務器之間共享。 使用 cbt 命令行界面和客戶端庫可以訪問 Bigtable 的數據存儲系統。 Bigtable 包括除 Python 之外的多種編程語言,使其易於與應用程序集成。
Google 的 Datastax Astra Cassandra 即服務:易於部署和擴展
Google 的 DataStax Astra Cassandra 即服務是學習 Cassandra 的絕佳選擇。 Kubernetes Operator 的用戶界面使配置、管理和擴展 Cassandra 部署變得簡單。
大表文檔
Bigtable 文檔是了解這個強大工具的重要資源。 它概述了 Bigtable 的特性和功能,以及有關如何使用它的詳細信息。 該文檔組織良好且易於遵循,對於任何有興趣了解此強大工具的人來說,它都是寶貴的資源。
Google Cloud Platform 負責託管 Google 的Bigtable 數據庫。 OpenTSDB 2.1及以後版本配合谷歌后端使用很簡單。 您所要做的就是創建一個 Bigtable 實例,使用 Bigtable HBase shell 設置您的 TSDB 表,然後啟動 TSD。 Bigtable 的客戶端目前處於測試階段並正在經歷各種變化。
Bigtable的高效數據佈局
Bigtable 也非常適合 MapReduce 操作。 由於其高效的數據佈局,MapReduce 可以在短時間內處理大量數據。