
Hadoop HDFS 和 NoSQL:大數據的強大組合
已發表: 2023-01-05Hadoop 是一個開源框架,允許使用簡單的編程模型跨計算機集群分佈式處理大型數據集。 HDFS 是Hadoop 分佈式文件系統,它提供了一種可擴展和容錯的方式來存儲數據。 NoSQL 數據庫是一類新型數據庫,旨在為傳統關係數據庫提供可擴展、靈活且高性能的替代方案。
Hadoop 和 HDFS 之間的主要區別在於,Hadoop 是一個用於存儲、處理和分析數據的開源框架,而 HDFS 是一個允許用戶訪問 Hadoop 數據的文件系統。 因此,HDFS 是一個Hadoop 模塊。
SQL 和 Hadoop 都可以通過多種方式管理數據。 Hadoop 框架用於組裝軟件組件,而 SQL 框架用於組裝數據庫。 對於大數據,考慮每種工具的優缺點至關重要。 Hadoop 平台只存儲一次數據,而 Hadoop 存儲的數據集數量要多得多。
Hadoop 不是數據庫,而是一種允許進行大規模並行計算的軟件。 該技術允許 NoSQL 數據庫(例如 HBase)在幾乎沒有性能下降的情況下將數據分佈到數千台服務器上。
Hadoop 存儲數據的方式與關係存儲不同。 分佈式服務器是使用它最多的應用程序之一。 雖然它是Hadoop 數據庫,但它不符合關係數據庫的資格,因為它在 HDFS(分佈式文件系統)中存儲文件。
Nosql 和 Hdfs 有什麼區別?
它是一個文件系統,也簡稱為文件系統。 很明顯,此應用程序提供了許多功能。 你從哪裡得到這些 NOSQL 的東西? 我們將能夠使用它實時處理大量數據,因為它不需要我們使用關係數據庫或其他功能。
在 Hadoop 中運行的 HBase 存儲管理器提供低延遲的隨機讀寫。 HBase 系統採用自動分片功能,其中大表是動態分佈的。 每個Region Server負責服務一組Region,只有一個Region Server能夠服務一個Region(即HMaster和HRegion是HBase提供的兩個主要服務。HBase表的HRegion組件負責處理表數據的子集。當一個Region Server啟動時,它被分配到每個Region。因此,master不參與讀寫操作。
在處理非結構化和海量數據方面,MongoDB 和 Cassandra 等 NoSQL 數據庫比傳統的關係數據庫脫穎而出。 具有大數據工作負載(例如大數據)的企業更喜歡使用這些工具來快速處理和分析大量不同的非結構化數據。 MongoDB 將數據存儲在集合中,而hadoop 將數據存儲在稱為 HDFS 的不同文件系統中。 由於這種差異,擁有不同的體系結構是有利的。 在 MongoDB 中查詢數據也比搜索單個文件快得多。 此外,由於 mongodb 是為大容量環境設計的,它非常適合以相對較低的成本處理大量數據。 建議需要大數據解決方案的企業使用 NoSQL 數據庫。 它們在處理速度和分析方面優於傳統數據庫,非常適合大規模數據分析和管理。
Hadoop 是 Nosql 數據庫嗎?
Hadoop 不是傳統的關係數據庫管理系統。 它是一個分佈式文件系統,有助於跨商用服務器集群存儲和處理大型數據集。 Hadoop 旨在從單個服務器擴展到數千台機器,每台機器都提供本地計算和存儲。
新技術正在徹底改變超大規模數據的使用。 大數據基礎架構有眾多參與者,包括 Hadoop、NoSQL 和 Spark。 DBA 和基礎架構工程師/開發人員現在為他們工作,以管理新一代 DBA 和基礎架構工程師中的複雜系統。 因為 Hadoop 是一個軟件生態系統而不是數據庫,所以它允許以高效且有效的速度計算大量數據。 它為其處理的大量數據提供的好處已經改變了大數據處理的遊戲規則。 大型數據事務,例如在集中式關係數據庫系統上需要 20 小時才能完成的事務,在 Hadoop 集群上只需三分鐘即可完成。
有不止一種 SQL 語言可供選擇。 純文檔數據庫MongoDB是NoSQL數據庫的一種; 寬列數據庫 Cassandra 是另一個; 圖形數據庫 Neo4j 是另一個。 此功能由 SQL- on-Hadoop創建。 SQL-on-Hadoop 是一類新的分析工具,它將已建立的 SQL 查詢與 Hadoop 數據框架相結合。 SQL-on-Hadoop 允許企業開發人員和業務分析師通過允許運行 SQL 熟悉的查詢來與 Hadoop 在商品計算集群上進行協作。 SQL-on-hadoop的優勢。 SQL-on-Hadoop 的眾多優勢,加上其易用性,非常值得企業數據開發人員和分析師投入時間和資源。 首先,他們可以在商品計算集群上使用 Hadoop,這將使他們能夠快速輕鬆地開始大數據分析。 SQL-on-Hadoop 還允許他們利用熟悉的 SQL 查詢,使他們更容易學習大數據分析。 此外,SQL-on-Hadoop 提供了 Hadoop 的 map/reduce 功能以及它提供的豐富的數據分析功能。
Nosql 數據庫興起
因此,NoSQL 數據庫因其可擴展性、讀/寫性能和數據靈活性而變得越來越流行。 市場上有幾個很好的 NoSQL 數據庫示例,包括 DynamoDB、Riak 和 Redis。
Hive 是一個輕量級的模塊化 NoSQL 數據庫,具有出色的性能指標。 它是用純 Dart 編程語言編寫的,由於其簡單性而受到開發人員的歡迎。
Hadoop和數據庫有什麼區別?

RDBMS 不存儲和處理數據,而 Hadoop 更願意將數據作為分佈式文件系統來存儲和處理。 另一方面,RDBMS 是一種結構化數據庫,它以行和列的形式存儲數據,可以使用 SQL 更新並以各種表格形式呈現。
大數據技術和工具的採用正在快速增長。 開源 Hadoop 發行版在分佈式文件系統上運行,並允許交換和處理大型數據集。 RDB 是一種基本的數據庫管理系統,所有數據庫管理系統(如 Microsoft SQL Server、Oracle 和 MySQL)都以最簡單的形式使用它。 儘管被歸類為一種進化,但 RDBMS 更像是任何其他標準數據庫,而不是一項重大任務。 它不是數據庫,而是可以容納和處理大量數據文件的分佈式文件系統。 雖然像 Hadoop 這樣的系統可以提供更好的性能,但也有一些很少被討論的缺點。 您必須考慮如何管理您的 Hadoop 集群、安全性、Presto 或您使用的任何其他界面。
大多數關係數據庫系統,例如 SQL Server 和 Oracle,都更易於使用。 大多數組織都面臨著一個主要問題,即沒有足夠的技能人員可以有效地操作 Hadoop,而且人才成本很高。 如果您有 10,000 名員工,您將需要大量數據來跟踪所有員工。 這些信息可以通過 Presto 以多種方式存儲。 日期分區可以用來存儲一個人每天的位置。 另一方面,RDBMS 可以用作數據模型的示例。 使用此方法的唯一方法是您已經可以訪問前一天的數據。
關係數據庫和大數據之間的主要區別是什麼?
關係數據庫和大數據之間的主要區別在於,關係數據庫針對存儲結構化數據進行了優化,而大數據針對存儲非結構化和半結構化數據進行了優化。 關係數據庫是在關係模型之後建模的,而大數據數據庫是在分佈式模型之後建模的。 結構化數據可以在關係數據庫中以高效的方式存儲和處理。 該表包含數據並支持結構化查詢語言 (SQL) 訪問和檢索。 大數據被定義為任何非結構化或半結構化的數據。

Hadoop 和 Mongodb 有什麼區別?
因為 MongoDB 在 C 中運行,所以它比任何其他數據庫都更擅長內存管理。 Hadoop 是一組基於 Java 的軟件,它提供了一個用於存儲、檢索和處理數據的框架。 Hadoop 比 MongoDB 更有效地優化空間。
MongoDB 是一個用 C 創建的 NoSQL(Not Only SQL)數據庫。Hadoop 是一個開源軟件平台,主要由 Java 組成,可以處理大量數據。 此外,MongoDB Atlas 包括全文搜索、高級分析和直觀的查詢語言。 Hadoop 在存儲和處理大量數據方面非常有效,但它是以小批量進行的。 MongoDB 提供了多種內置的實時數據處理工具。 由於它的外部工具連接器,如 Kafka 和 Spark,MongoDB 使數據攝取和處理變得簡單。 Hadoop和MongoDB在大數據領域相對於傳統數據庫的優勢不勝枚舉。 Hadoop 是一種分佈式文件系統,可用於處理龐大的文件。 就性能而言,MongoDB 是唯一能夠替代傳統數據庫的數據庫。
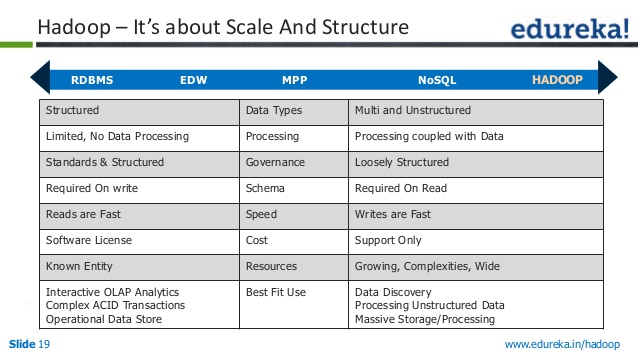
Rdbms 對比 Nosql 對比 Hadoop
數據存儲主要分為三種類型——RDBMS、NoSQL 和 Hadoop。 它們各有優缺點,因此根據您的需要選擇合適的非常重要。
RDBMS(關係數據庫管理系統)是最常見的數據存儲類型。 它易於使用且易於擴展。 但是,它不如 NoSQL 或 Hadoop 靈活,而且維護成本更高。
NoSQL(Not Only SQL)是一種越來越流行的新型數據存儲。 它比 RDBMS 更靈活,可擴展性更強。 然而,它並不那麼容易使用,而且維護起來可能更昂貴。
Hadoop 是一種專為大數據設計的數據存儲。 它的可擴展性很強,可以處理大量數據。 但是,它不像 RDBMS 或 NoSQL 那樣易於使用,而且維護成本更高。
使用Apache Hadoop平台可以大大改進企業存儲、處理和分析數據的方法。 數據湖可以在相同的硬件和軟件上運行多種類型的分析工作負載,也可以大規模管理數據量。 分析師現在可以使用 Apache Impala 和 Apache Spark 等工具隨時隨地與數據進行有效交互。 Hadoop 與關係數據庫管理系統 (RDBMS) 不同,它不具備與數據庫相同的功能,而更像是一個能夠處理海量數據的分佈式文件系統。 可以輕鬆有效地處理的數據量稱為數據量Volume。 換句話說,可以優化的是特定時間段內的總數據量過程。 它能夠存儲和處理來自廣泛來源的數據,並為分析做好準備。
在少量情況下,RDBMS 只能管理結構化和半結構化數據。 Hadoop 無法處理來自各種來源或任何結構化結構的數據。 響應時間、可擴展性和成本是需要考慮的其他一些重要因素。
為什麼 Rdbms 仍然是最受歡迎的數據庫管理系統
世界上使用最廣泛的數據庫管理系統是RDBMS。 它提供了廣泛的功能,並且非常可靠。 關係數據庫最適合存儲需要多個用戶訪問的數據。
NoSQL 數據庫越來越受歡迎,部分原因是它們比關係數據庫具有性能優勢。 它們還允許您存儲不需要與多個用戶共享的大量數據。
Hadoop 數據庫
在商用硬件集群上,Hadoop 存儲大數據。 如有必要,您可以選擇更改任何不起作用或滿足您需求的功能。 相反, NoSQL 數據庫管理系統是一種用於存儲結構化、半結構化和非結構化數據的數據庫管理系統。
Hdfs是數據庫嗎
HDFS 文件系統是一種在商用硬件上運行的分佈式文件系統。 使用此功能可以將單個 Apache Hadoop 集群配置為支持數百(甚至數千)個節點。 Apache Hadoop,其中還包括 MapReduce 和 YARN,由幾個主要組件組成。
Hadoop 分佈式文件系統 (HDFS) 提供對數據的高性能訪問,它是Hadoop 操作系統的一個組件。 集群的主名稱節點負責跟踪集群文件數據的存儲位置。 除了管理文件訪問外,Name 節點還管理對文件的訪問,例如讀取、寫入、創建、刪除等。 雅虎引入了 Hadoop 分佈式文件系統作為其在線廣告投放和搜索引擎要求的一部分。 HDFS 協議公開了一個文件系統命名空間以存儲用戶數據。 DataNodes可以在正常的文件操作期間相互通信,因為它們相互通信。 Hadoop 分佈式文件系統 (HDFS) 是許多開源數據湖的一個組件。 eBay、Facebook、LinkedIn 和 Twitter 使用 HDFS 來分析大量數據。 如果發生節點或硬件故障,HDFS 需要進行數據複製才能正常運行。
Hadoop 數據庫示例
Hadoop 數據庫是使用 Hadoop 分佈式文件系統 (HDFS) 作為其底層存儲的數據庫。 Hadoop 數據庫通常用於存儲太大而無法放在單個服務器上的大量數據。
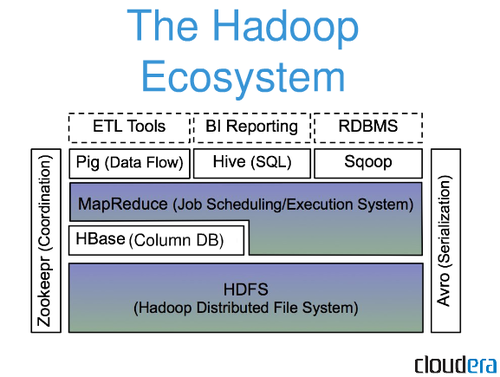
Apache Hadoop 是一種用於在商用硬件上以分佈式方式存儲和處理大型數據集的開源框架,用於各種應用程序。 它是 Google 範式的開源版本,在他們 2004 年的論文 MapReduce 中使用過。 在本文中,我們將討論大數據生態系統初學者最常問的一些問題。 Apache Hadoop 平台專注於分佈式數據處理,而不是數據庫存儲或關係存儲。 儘管存在稱為 HDFS(Hadoop 分佈式文件系統)的存儲組件,它存儲用於處理的文件,但 HDFS 屬於關係數據庫的類別。 Hive,還有HiveQL,都可以用來查詢HDFS的HDFS存儲,HDFS是內置的。
什麼是 Hadoop 的示例?
金融服務公司可以使用 Hadoop 來評估風險、建立投資模型和創建交易算法; Hadoop 還被用於協助創建和管理這些應用程序。 零售商使用這項技術通過分析結構化和非結構化數據來幫助他們更好地了解和服務客戶。
Hadoop 的多種用途
Hadoop 可用於管理大數據應用程序中的數據,例如大數據分析、實時數據分析、科學研究和數據倉庫。 因此,它是一個多功能且適應性強的平台,非常適合廣泛的應用。
Spark 是 Nosql 數據庫嗎
根據文檔,NoSQL DataFrame 是 Spark DataFrame 的數據源格式。 DataPruning 和過濾(謂詞下推)在此數據源中可用,這允許 Spark 查詢在更少量的數據上運行,並且僅加載活動作業所需的數據。
將 Apache Spark 和 NoSQL(Apache Cassandra 和 MongoDB)數據庫相互連接需要大量的戰術努力。 本博客介紹如何在 NoSQL 後端創建 Apache Spark 應用程序。 TCP/IP sPark 是一個受歡迎的主題公園目的地,在其著名的 CassandraLand 和 MongoLand 部分擁有大量遊樂設施。 當我們的 Spark 應用程序從 DOE 查找數據時,它轉動了輪子並變得沮喪。 這裡的教訓是,Cassandra 的key sequence 在抓取數據的過程中是很關鍵的。 CassandraLand 還有一個流行的過山車,叫做 Partitioner。 鼓勵乘坐過山車的客戶跟踪他們的乘坐歷史,以便運營商可以跟踪每天乘坐過山車的人。 Mongo 第 1 課 – 正確管理 MongoDB 連接 更新數據時,例如能源部新園區成員的狀態,Mongo 索引會非常有用。 在特定更新的情況下,MongoDB 和 Spark 應確保正確的連接管理和索引。
Spark:大數據的未來
Apache Spark是與Apache軟件基金會合作開發的分佈式處理系統,是一個基於Hadoop的大數據處理系統。 一個開源框架,可用於優化大型數據集並彌合過程模型和關係模型之間的差距。 此外,Spark 支持 MongoDB,使其可用於實時分析和機器學習。