
是 Spark 用於 Nosql
已發表: 2023-02-05Spark 是處理數據,尤其是大型數據集的強大工具。 它旨在快速高效,並且支持多種數據格式,包括NoSQL 數據庫。 NoSQL 數據庫正變得越來越流行,因為它們非常適合處理大量數據。 Spark 可以幫助您高效地查詢和操作 NoSQL 數據。
為了有效地工作,使用 Apache Spark 和 NoSQL( Apache Cassandra和 MongoDB)管理應用程序的數據庫至關重要。 此博客的目標是提供使用 NoSQL 後端開發 Apache Spark 應用程序的技巧。 這是一個主題公園,TCP/IP sPark 在 CassandraLand 和 MongoLand 都有遊樂設施。 當我們嘗試查詢 DOE 數據時,我們的 Spark 應用程序開始自旋偏離軸心。 這裡的教訓是,當您查詢 Cassandra 時,鍵序列很重要。 CassandraLand 還提供 Partitioner 過山車,這是其最受歡迎的景點之一。 當客戶享受他們的過山車之旅時,乘車運營商可以通過保留他們的信息來跟踪每天乘坐過山車的人。
在第一課中,我們將介紹如何管理 MongoDB 連接。 當您需要更新有關公園的信息時,例如能源部的新公園成員身份,您可以使用mongo 索引。 應該使用 MongoDB 和 Spark 來確保正確管理您的連接,以及特定情況下的索引。
Apache Spark 是一種流行的分佈式處理系統,它是開源的,專為處理大數據工作負載而構建。 除了內存緩存和優化的查詢執行之外,此功能還支持對大量數據進行快速分析查詢。
使用幾乎相同的代碼,它更加高效和通用,允許它同時處理批處理和實時數據。 因此,較舊的大數據工具由於缺乏此功能而變得越來越過時。
Spark 是什麼類型的數據庫?
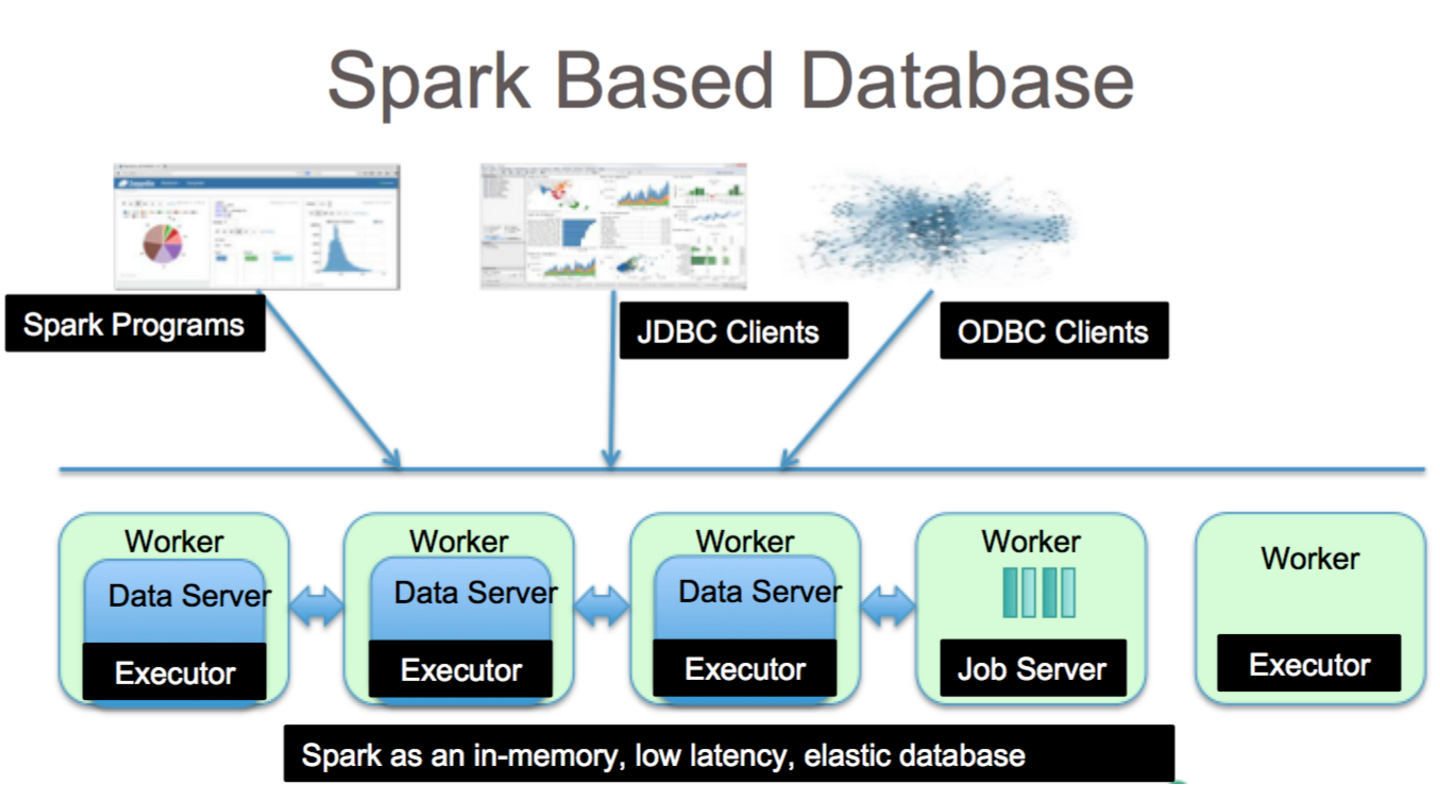
Apache Spark 是一個數據處理框架,可以處理來自各種數據存儲庫的數據,包括 (HDFS)、NoSQL 數據庫和關係數據庫。
儘管關係數據庫已經出現了無數次炒作週期,但無論 NoSQL 數據庫的最新進展和興起如何,它們都將繼續流行。 隨著時間的推移,在關係數據庫中存儲數據變得越來越困難。 在本文中,我們將了解在全球範圍內利用關係數據庫的強大功能所取得的一些重大進展。 首次發佈時,Spark 和大數據分析之間的接口很少。 很多人為了運行這個功能強大但比較慢的程序寫了很多代碼。 用戶將能夠輕鬆地將這兩個模型結合到Spark SQL數據庫中。 它還接受來自各種來源的各種數據格式。
Apache Spark 開源項目是最活躍的,有數百名貢獻者參與其中。 除了作為一個免費的開源項目,Spark SQL 已經開始在主流行業中流行起來。 除了 Spark SQL 之外,大約三分之二的 Databricks Cloud 客戶(運行 Spark 的託管服務)使用其他編程語言。 在我們的第一個案例研究結束後,我們將在這個實踐案例研究中演示如何將數據塊應用到案例中。 Spark DataFrame是一組以相同模式分佈的行(行類型)。 數據集中的每一列都標有名稱。 DataFrame 的 API 允許開發人員集成過程代碼和關係代碼。
Spark 還可以處理 UDF 等高級功能。 關係數據庫中的表類似於數據框數據庫中的數據框,但涉及更多優化。 它們的操作方式與 Spark 的原生分佈式集合 (RDD) 相同。 總的來說, Spark SQL 查詢比 Shark 查詢更快,與 Impulsa 相比更具競爭力。 在查詢 3a 中,查詢選擇性導致其中一個表非常小,Impala 和 Impala 之間存在顯著差異。

它是使用 Spark SQL 進行數據分析的絕佳工具。 可以通過 HiveQL 語法以及 Hive SerDes 和 HiveDF 訪問 HiveQL 語法、Hive SerDes 和 HiveDF。 Hive metastores 、SerDes 和 UDF 已經實現。 儘管 Spark 是一個數據庫,但它也是一個 NoSQL 數據庫。 因此,當您在 Spark 中創建託管表時,您將能夠使用各種符合 SQL 的工具來存儲您的數據。 通過 jdbc.org 的連接器連接到 JDBC,SQL 表達式可用於訪問 Spark 中的表。 因此,您還可以使用 Tableau、Talend 和 Power BI 等第三方工具。 使用 Spark 的能力非常適合數據分析,它是適用於廣泛行業的有用工具。
Spark Sql:兩全其美
它通過包括兩個主要組件彌合了前面提到的兩個模型(過程模型和關係模型)之間的差距。 因此,您可以使用 DataFrame API 對外部數據源和 Spark 的內置分佈式集合運行大規模關係操作。
數據庫中的spark是什麼? 它是一個使用機器學習、交互式查詢處理和實時工作負載的開源框架。 該公司沒有自己的存儲系統; 相反,除了自己的存儲系統之外,它還對其他存儲系統(例如 HDFS、Amazon Redshift、Amazon S3、Couchbase 等)進行分析。 在結構化數據處理方面,Spark SQL 不僅僅是一個數據庫; 它也是一個模塊。 其中絕大部分是在 DataFrame 上編寫的,DataFrame 是與 SQL 查詢結合使用的編程抽象。
“sparksql”的SQL sql類型是什麼? Hive SQL 支持 HiveQL 語法,以及 Hive SerDes 和 UDF,允許您訪問之前創建的 Hive 倉庫。 在 Spark SQL 中使用現有的 Hive 元存儲、SerDes 和 UDF 並不困難。
Mongodb 可以運行 Spark 嗎?
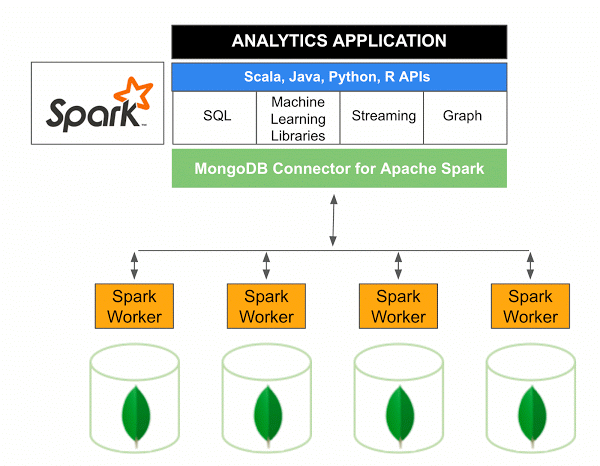
適用於 Apache Spark 的 MongoDB Connector 10.0 版包括通過新的 Spark Data Sources API V2支持 Spark Structured Streaming 以及新的 Spark Data Sources API V2 的實現。
用於 Spark 的 MongoDB 連接器是一個開源項目,允許您使用 Scala 從 MongoDB 寫入數據並從 MongoDB 讀取數據。 由於連接器的實用方法,簡化了 Spark 和 MongoDB 之間的交互,使其成為創建複雜分析應用程序的強大組合。 使用其內置的複制和分片功能,Spark 可以在使用MongoDB 數據庫的各種工作負載中實施。
Spark:構建數據豐富的應用程序的快速方法
借助Spark這個強大的工具,您可以快速開發更多功能的應用程序。 通過合併 MongoDB,開發人員可以利用單一數據庫技術加快開發過程。 此外,Spark 是雲原生的,包括對NoSQL 數據存儲的支持,使其成為數據密集型應用程序的理想選擇。