
MapReduce:大數據集的編程模型
已發表: 2023-01-08MapReduce 是一種編程模型和相關實現,用於在集群上使用並行分佈式算法處理和生成大型數據集。
我們正在改變我們使用新技術處理大量數據的方式。 Hadoop、NoSQL 和 Spark 等數據倉庫是該領域最傑出的參與者之一。 DBA 和基礎設施工程師/開發人員屬於新一代專業人士,他們專門管理高度複雜的系統。 Hadoop 不是數據庫,而是一個軟件生態系統,它允許以海量文件的形式進行並行計算。 該技術在支持大數據的海量處理需求方面提供了顯著優勢。 對於大型數據事務,Hadoop 集群平均可能只需要三分鐘即可處理大型事務,而在集中式關係數據庫系統中通常需要 20 小時。
mapreduce 集群是一種具有並行算法和編程模型的集群,可以像普通集群一樣處理和生成大數據集。
Apache Hadoop 生態系統旨在支持分佈式計算,並提供可靠、可擴展且隨時可用的環境。 該項目的 MapReduce 模塊是一種編程模型,用於處理駐留在 Hadoop(分佈式文件系統)上的龐大數據集。
該模塊是Apache Hadoop開源生態系統的一個組件,用於查詢和選擇Hadoop分佈式文件系統(HDFS)中的數據。 可以使用可用於進行此類選擇的 MapReduce 算法來為各種查詢選擇數據。
使用 MapReduce,可以運行大數據處理任務。 您可以使用任何編程語言構建 MapReduce 程序,包括 C、Ruby、Java、Python 等。 這些程序可以同時用於運行 MapReduce 程序,使其在大規模數據分析中非常有用。
Mongodb 中 Mapreduce 的用途是什麼?
MongoDB 中的地圖是一種數據處理編程模型,使用戶能夠執行大型數據集並從中生成聚合結果。 MapReduce 是 MongoDB 用於減少地圖的方法。 該函數分為兩個部分:映射函數和縮減函數。
使用 MongoDB 的MapReduce 工具,可以組織和聚合大型數據集。 在 MongoDB 中,此命令使用 MongoDB 中的兩個主要輸入:map 函數和 reduce 函數,以處理大量數據。 要定義示例,請按照以下步驟操作。 我們將定義 map 函數、reduce 函數和示例。
MapReduce 將使用默認排序方法比較字符串以對輸出進行排序,無論您是否使用默認方法。 要改變數據的排序方式,您必須首先創建一個排序算法,然後使用映射器類來實現它。
SpiderMonkey 是一種廣泛使用的 JavaScript 引擎。 它適用於小規模應用,但也有一些局限性。 例如,SpiderMonkey 沒有排序算法。 這樣一來,如果要使用Mapmapper對數據進行排序,就必須先創建自己的排序算法,並在Reduce類中實現。
儘管很受歡迎,但 SpiderMonkey 並不使用排序算法。 SpiderMonkey 還有其他限制,但這一限制值得注意。 例如,SpiderMonkey 沒有很好的垃圾收集器,因此如果您的程序開始變慢,您可能需要採取一些措施使其更快。
為什麼要使用 Mapreduce 函數?
MapReduce 函數在多種情況下都很有用。 該方法在某些情況下可用於批量數據處理。 如果您需要由單個應用程序或進程處理大量數據,它也很有用。 MapReduce 函數還可用於處理分佈在分佈式系統中多個節點上的數據。 通過使用 MapReduce 功能,來自節點的數據可以組合成單個輸出。 MapReduce 應用程序通常用於處理大量數據,儘管它可能需要處理非常大的數據量。
為什麼叫Mapreduce?
關於為什麼將其稱為 MapReduce,存在一些理論。 一個是它是文字遊戲,因為 map-reduce 算法涉及將問題分解成更小的部分(映射),然後解決這些部分並將它們放回一起(減少)。 另一種說法是,它引用了 Google 員工在 2004 年撰寫的一篇名為“MapReduce:大型集群上的簡化數據處理”的論文。 在論文中,作者使用術語“map”和“reduce”來描述他們提出的處理模型的兩個主要階段。
然而,重要的是要注意 MapReduce 模型僅在有限的基礎上使用。 它不適合大型數據集,必須並行化才能正常運行。 在解決這些問題時,Apache Spark 有一個強大的 MapReduce 替代方案。 Spark集群計算系統基於Hadoop,作為一個通用的計算平台。 該工具可用於加速傳統的數據分析任務,如數據挖掘和機器學習,以及更複雜的數據處理任務,如數據倉庫和大數據分析。 該軟件是使用 Erlang 構建的,Erlang 是一種可擴展且容錯的編程語言。 它可以處理大量數據並且可以同時在多台機器上運行。 此外,Spark 採用並行機制,允許多個節點同時執行相同的任務。 總的來說,它具有自動化大規模數據分析任務並使其更具可擴展性的潛力。 如果您需要並行處理和處理大型數據集,它是 MapReduce 的絕佳替代方案。
Mapreduce 和聚合之間有什麼區別?
在處理大數據時,mapreduce 是從大量數據中提取數據的重要方法。 截至目前,MongoDB 2.2 包含新的聚合框架。 在功能方面,聚合類似於 mapreduce,但在理論上,它似乎更快。
在這種情況下,MongoDB 聚合和 MapReduce 在分片設置中的 Docker 容器上運行。 聚合器管道性能優於 mapreduce,因為它允許更快、更輕鬆的導航。 問題的工作原理如下:tweet 在 Twitter 標籤中計算瑞典語代詞,如“den”、“denne”、“denna”、“det”、“han”、“hon”和“hen”(區分大小寫)。 一個用戶有多少個推特賬號? 已發出超過 400 萬條推文。 在這個實驗中,我們將首先創建一個 MongoDB 數據庫並啟用分片。 Twitter 流被導入數據庫,並使用 MapReduce 和聚合管道執行查詢。
Mapreduce:終極數據聚合工具
mapReduce 程序從集合中讀取文檔列表並使用一組預定義的函數處理它們。 mapReduce 操作生成準備處理的文檔流,這些文檔將在 reduce 階段進行處理。 可以在各種情況下結合 mapsreduce 和聚合。 $group 聚合運算符是一種可用於在單個字段中對文檔進行分組的工具。 當使用 $merge 聚合運算符合併多個文檔時,可以創建一個新文檔。 $accumulator 聚合運算符可用於將多個 map-reduce 操作的結果表示為單個文檔。
MongoDB 中的映射減少
Mongodb mapreduce是一種針對大數據集的數據處理技術。 它是分析數據的強大工具,提供了一種以並行和分佈式方式處理和聚合數據的方法。 MapReduce 已廣泛用於各種領域的數據分析,包括網絡流量分析、日誌分析和社交網絡分析。

使用mapReduce 命令時,您可以對集合運行 map-reduce 聚合操作。 map 函數可以將任何文檔轉換為零個或多個其他文檔。 在從 4.2 到更早版本的 MongoDB 版本中,每個 emit 只能容納最大 BSON 文檔大小的一半。 不再支持 MapReduce 中使用的已棄用的 BSON 類型 JavaScript 代碼,並且該代碼不能再用於其功能。 MongoDB 4.4 現在不再包含已棄用的具有作用域的 BSON 類型 JavaScript 代碼(BSON 類型 15)。 scope 參數指定 reduce 函數允許訪問哪些變量。 為了減少輸入,MongoDB 將 BSON 文檔大小限制為其最大大小的一半。
返回到服務器的大型文檔可能會被返回,然後在後續的縮減中合併,這可能會破壞需求。 MongoDB 4.2 是最新版本。 此選項可用於創建新的分片集合以及 map-reduce 以創建具有相同集合名稱的新集合。 finalize 函數接收鍵值和來自 reduce 函數的縮減值作為參數。 配置 out 參數有三個選項。 此選項除了創建新集合外,對副本集的次要成員不起作用。 NonAtomic: false 選項只能在集合已經存在時提供,傳遞具有明確的規範。
如果新文檔上的鍵與現有文檔上的鍵相同,則對新文檔和現有文檔都使用 reduce 函數會產生結果。 當 collectionName 是已設置的現有未硬集合時,map-reduce 不起作用。 在這種情況下,如果 nonAtomic 為真,MongoDB 將無法鎖定其數據庫。 只有使用此選項的副本集的次要成員才能脫離集合。 不需要自定義函數來重寫 map-reduce 操作。 cust_id 用於通過cust_id 方法計算$group 階段組的值字段。 $merge 階段使用可用的聚合管道運算符將 $merge 階段的結果組合到輸出集合中。
例如,$out 階段可用於寫入集合 agg_alternative_1 的輸出。 每個輸入文檔都可以使用地圖功能進行處理。 訂單中的每個項目都與一個新的對象值相關聯,該對象值包含 1 的數量和訂單中的項目數量。 在 reducedVal 中,count 字段表示數組元素生成的 count 字段的總和。 如果 finalize 函數修改 reducedVal 對像以包含名為 avg 的計算字段,則修改後的對象將返回給用戶。 $unwind 階段使用 items 數組字段將文檔分解為每個數組元素的文檔。 $project 階段通過包含兩個字段 -id 和 value 來重塑輸出文檔以反映 mapreduce 的輸出。
如果不存在與新結果具有相同鍵的現有文檔,它將覆蓋現有文檔。 如果您指定 out 參數,如果您要將結果寫入集合,mapReduce 將返回一個文檔作為以下格式的輸出。 如果輸出是內聯寫入的,則返回結果文檔數組。 每個文檔包含兩個字段:源文檔的名稱和接收文檔的名稱。 當在 -id 字段中輸入鍵值時,將創建一個值字段以減少或確定鍵的值。
Mongodb 中的 Emit 是什麼?
作為一個map函數,map函數可以隨時調用emits(key,value)生成包含key和value的輸出文檔。 MongoDB 4.2 及更早版本中的單個 emit 只能容納 MongoDB BSON 文件最大大小的一半。 從 MongoDB 4.4 版本開始,該限制被移除。
為什麼 Mongodb 是靈活和可擴展數據的最佳選擇
由於缺乏嚴格的模式,MongoDB 經常與 NoSQL 聯繫在一起。 由於它沒有嚴格的模式,數據可以以任何對應用程序方便的格式存儲。 數據庫的靈活性在向上或向下擴展時提供了一個重要的優勢,因為這意味著數據可以以適合應用程序需求的方式存儲。
帶有 ER 圖的數據圖可用於可視化各種數據之間的關係。 ER圖描繪了代表數據集合的一系列節點,它們之間的連接充當標識符。
關係在 MongoDB 中沒有強制執行,因為它不是關係數據庫。 ER 圖描繪了數據中存在的關係,它也有助於可視化它們。
MongoDB 是靈活且可擴展的數據的絕佳選擇。 它的靈活性使其能夠以對應用程序有意義的方式存儲數據,其可擴展性使其能夠快速輕鬆地處理大型數據集。
Map-reduce Mongodb 示例
在 MongoDB 中,map-reduce 是一種數據處理範例,用於從集合中聚合數據。 它類似於函數式編程中的 map 和 reduce 函數。
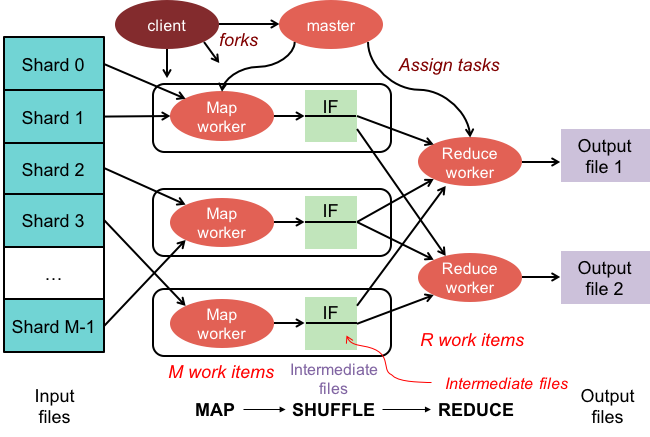
Map-reduce 操作有兩個階段:
1. 映射階段對集合中的每個文檔應用一個映射函數。 映射函數為每個輸入文檔發出一個或多個對象。
2. reduce 階段對 map 階段發出的文檔應用 reduce 函數。 reduce 函數聚合對象並生成單個對像作為輸出。
例如,考慮一個文章集合。 我們可以使用 map-reduce 來計算每篇文章中的單詞數。
首先,我們定義一個映射函數,它為每個文檔發出一個鍵值對,其中鍵是文章 ID,值是文章中的單詞數。
接下來,我們定義一個 reduce 函數,對每個鍵的值求和。
最後,我們對集合執行 map-reduce 操作。 結果是包含聚合數據的文檔。
在mongosh中,有一個數據庫。 mapReduce() 方法是 mapReduce 命令的包裝器。 本節中提供了幾個示例,例如沒有自定義聚合表達式的聚合管道替代方案。 通過使用 Map-Reduce 到聚合管道轉換示例,可以使用自定義表達式轉換地圖。 可以更改 map-reduce 操作,而無需使用可用的聚合管道運算符定義自定義函數。 map 函數可用於處理輸入中的每個文檔。 每個項目都有自己的對象值,該對象值與包含數字 1、訂單數量和項目列表的新值相關聯。
如果當前文檔中的鍵與新文檔中的鍵相同,則該操作將覆蓋該文檔。 您可以使用聚合管道運算符而不是定義自定義函數來重寫 map-reduce 操作。 $unwind 階段按 items 數組字段分解文檔,從而為每個數組元素生成一個文檔。 當 $project 階段重塑輸出文檔時,map-reduce 輸出被鏡像。 操作會覆蓋與新結果具有相同鍵的現有文檔。
Hadoop中的Mapper函數是什麼?
作為一個 reducer,你必須結合來自 mappers 的數據來生成一個統一的答案。 當一組映射輸出被接受為輸入時,會產生 Reduce 輸出,每個映射輸出代表生成結果的一個子集。
映射器用於將數據劃分為可管理的塊,然後根據塊的大小將每個塊分配給任務。 輸入數據由映射器函數接收,其中有參數指示要執行的任務。
一系列項目對應於映射器在輸出中映射的數據塊。 結果,map 輸出被轉發到 reducer,reducer 將其轉換為 reduce 輸出。
錯誤也由映射器函數處理。 在這種情況下,映射器將返回錯誤輸出,這不是映射輸出。 因為 reducer 無法處理這些數據,所以 mapper 會返回一個錯誤信息。
Hadoop生態系統
Hadoop 生態系統是一個處理和存儲大數據的平台。 它由許多組件組成,每個組件在數據的處理和存儲中都扮演著特定的角色。 該生態系統最重要的組件是 Hadoop 分佈式文件系統 (HDFS)、MapReduce 框架和Hadoop Common 庫。