
NoSQL 數據庫:Impala
已發表: 2023-03-03NoSQL 是一個術語,用於描述不使用傳統關係數據庫結構的數據庫。 相反,NoSQL 數據庫通常旨在提供更簡單、更具可擴展性的解決方案。
Impala 是一個 NoSQL 數據庫,旨在為管理大型數據集提供快速、可擴展的解決方案。 Impala 基於 Google Bigtable 數據模型並使用列式存儲格式。 Impala 可作為開源項目使用,並受 Cloudera 支持。
Apache Impala 是一個開源的 SQL 查詢引擎,安裝在 Hadoop 集群上,對存儲在系統上的數據執行大規模並行處理 (MPP)。 這個開源項目最初於 2012 年開發,被稱為“Microsoft Formula 1”。
Impala 平台使用戶能夠對存儲在 HDFS 和 Apache HBase 中的Hadoop 數據執行低延遲 SQL 查詢,而無需移動或轉換數據。
Impala 是基於 SQL 的嗎?
Impala 是一個基於 SQL 的查詢引擎,運行在 Apache Hadoop 上。 它允許用戶使用 SQL 查詢存儲在 HDFS 和 HBase 中的數據。 與 Hive 和 Pig 等其他Hadoop 查詢引擎相比,Impala 提供高性能和低延遲。
Impala 分析 MPP 數據庫提供業內最快的洞察時間。 它與 CDH 集成在一起,可以通過 Cloudera Enterprise 訪問。 適用於 Apache Hadoop 的 MPP 數據庫(例如 Impala)使用 HDFS 來提供更快的洞察時間。
Impala 是一個數據庫
我相信這是一個數據庫。
Impala 是 Etl 工具嗎?
Impala 不是一個 ETL 工具,它是一個 SQL 查詢引擎,可用於在數據經過某個流程清理後進行 SQL 查詢。
Apache Impala 的用途是什麼?
使用類似 SQL 的查詢,我們可以使用 Impala 從各種來源讀取數據。 在訪問存儲在Hadoop 分佈式文件系統中的數據時,Apache Impala 的性能優於 Hive 和其他 SQL 引擎。 我們使用 Impala 將數據存儲在 Hadoop HBase、HDFS 和 Amazon S3 中。
19 家在其技術堆棧中使用 Apache Impala 的公司
Apache Impala 是一種流行的數據處理引擎,適用於各種大型企業。 據報導,包括 Stripe、Agoda 和 Expedia.com 在內的 19 家科技公司都在使用 Apache Impala。 Impala 平台靈活高效,能夠快速有效地處理大型數據集。 這個工具的廣泛使用證明了它的用處,以及它在數據處理方面的用處。
Sql Hive 和 Impala 有什麼區別?
Hive 的目標是處理需要多次轉換和連接的長時間運行的查詢。 由於其低延遲和處理較小查詢的能力, Impala 查詢處理引擎是交互式計算的理想選擇。 除了短期和長期查詢外,Spark 還支持短期和長期查詢。
Hive 更適合長時間運行的批處理作業
這些工具的主要目的不是處理批次。 Hive 比 Impulsa 更適合長期的批處理工作,Impulsa 可以處理較小的數據集。
Impala 是數據庫嗎
Impala 是一種以柱狀格式存儲數據的數據庫。 它旨在可擴展並為大型數據集提供高性能。
在 Impala 初始版本中,支持以下核心列數據類型:STRING、VARCHAR、VARCHar2、INT 和 FLOAT 而不是數字,並且不支持 BLOB 類型。 Impala SQL-92 包括一些 SQL 標準的標準增強,但它並沒有包含所有這些。 當數據太大而無法在單個服務器上生成、操作和分析時,Impala 的性能優於其他數據倉庫,並且具有更高的可擴展性。 加載 Impala 時無需刪除數據文件的原始位置,因為它是輕量級的。 了解性能測試、可擴展性和多節點集群配置的第一步通常是收集大量數據。 Cloudera Impala 針對大型數據集中的數據加載和批量讀取進行了優化,讓您事半功倍。 HDFS 的多兆字節塊大小允許 Impala 跨多個聯網服務器並行處理大量數據。
您無需規劃規範化索引以及創建它們所需的時間和精力,而是在 Impala 中完成。 Impala 的查詢引擎可以處理來自數據倉庫的大量數據。 它分析集群並在節點之間分配任務,以減少消耗的資源量。 數據倉庫的分區是 Impala 中一個熟悉的概念。 分區減少了磁盤 I/O 並增加了 Impala 中的查詢可擴展性。 需要數據文件,因為您將無法訪問 Impala 中的任何內置表。 INSERT 是可用選項之一。
要構建兩個玩具表,請使用價值聲明。 如果你一直在使用面向批處理的軟件,你可以試一試。 您可以將 SQL-on- hadoop 技術合併到 Apache Hive 配置中。 Impala 中的 Hive 表不會以耗時的方式加載或轉換。
Impala:一個強大的 Hadoop 數據管理工具
SQL 語法是 Impala 用戶所熟悉的,它可以查詢存儲在 HDFS 和 Apache HBase 中的數據。 這樣就可以使用Hadoop和Impulsa,而不是傳統的關係型數據庫。 此外,由於其功能,它是一個強大的數據管理工具。 此外,它處理大型數據集的能力令人印象深刻,並且可以輕鬆處理它們。

大數據中的 Impala
Impala 是一個在 Apache Hadoop 上運行的開源 MPP SQL 查詢引擎。 它對存儲在 HDFS 和 HBase 中的數據提供快速、交互式的 SQL 查詢。 Impala 旨在通過為存儲在 HDFS 和 HBase 中的數據提供快速、交互式的 SQL 接口來提高 Apache Hadoop 的性能。
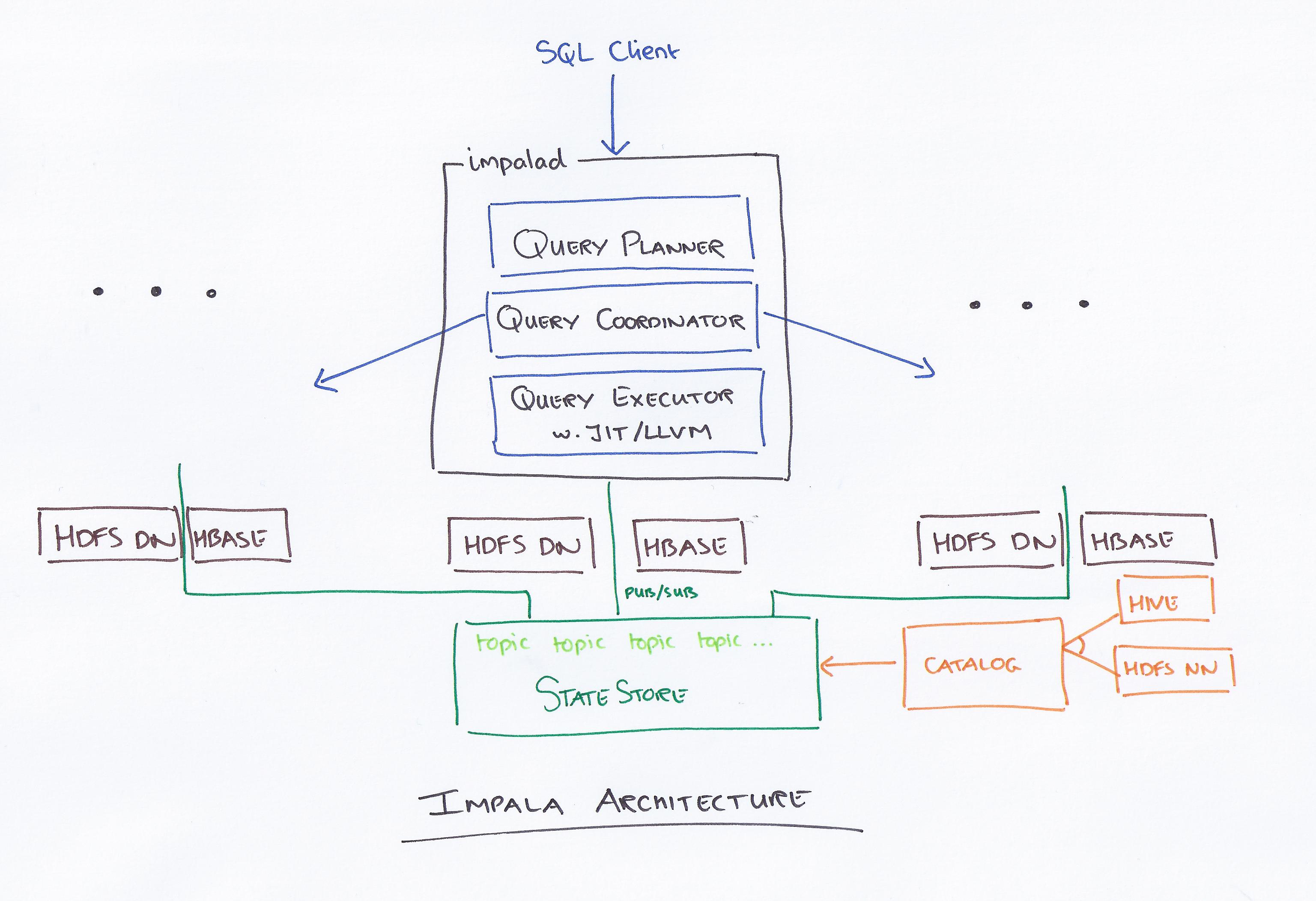
以Cloudera為首的Impala是一個新的查詢系統。 Hadoop有HDFS和HBase,可以查詢存儲在那裡的PB級大數據。 該技術基於Hive和內存進行計算,同時兼顧數據倉庫,提供實時批處理和多並發處理。 客戶端向 impalad 網絡中的節點發送查詢請求,其中返回查詢 Id 以供後續客戶端操作使用。 在分析器創建過程的第一步,會生成一個單機執行計劃(單機計劃、分佈式執行計劃),同時也會執行SQL,比如連接順序的改變、謂詞下推等。 所有節點都保留一份最新的元數據信息,以確保您不會被排除在外。 在使用Hadoop、Hive或Impurbia之前,您必須先安裝必要的數據處理軟件。
Impala 的配置文件可以更改。 每個節點都在 Impala 中執行配置更改。 所有節點負責將 MySQL 驅動程序包連接到數據庫。 節點改變 Bigtop 的 Java 路徑。
Hive 和 Impala 的比較
除了這三個主要差異之外,還有一些小差異。 在 Hive 中,有一個 HiveQL 的子集,而在 Implicit 中,有一個 HiveQL 的子集。 Hive和Impala分別用於數據倉庫和交互式查詢。 與 Impala 不同,Hive 不適合交互式計算。
Hadoop 中的 Impala 是什麼
Impala 是一個開源 SQL 查詢引擎,用於存儲在 Hadoop 集群中的數據。 它旨在為存儲在 HDFS、HBase 或任何其他Hadoop 數據源中的數據提供快速、交互式的 SQL 查詢。
Impala 使用了廣泛的熟悉的 Hadoop 組件。 INSERT 只能寫入 Impala 可以讀取的類型的數據,而 SELECT 可以讀取 Impala 可以讀取的類型的數據。 使用 Avro、RCFile 或 SequenceFile 文件格式時,數據將加載到 Hive 中。 除了表和列統計之外,還可以使用表統計和列統計。 如果所有 DDL 和 DML 語句是通過 catalogd 守護進程發送的,則它們會使用 Impala 1.2 和更高版本中的 catalogd 守護進程自動更新。 INVALIDATE METADATA 方法返回元存儲中已訪問的所有表的元數據。 數據文件存儲在新表的目錄中,並且在 Impala 運行時無論文件名如何都被讀取。
總體而言,Apache Hive 作為數據倉庫平台表現良好,而 Impala 更適合併行處理。 Hive 是容錯的,而 Impulsa 不是。
阿帕奇黑斑羚
Apache Impala 是一種用於 Apache Hadoop 的快速交互式 SQL 查詢引擎。 它使用戶能夠對存儲在 HDFS 和 Apache HBase 中的數據發出低延遲 SQL 查詢,而無需數據移動或轉換。
Impala 的架構概念使其能夠比任何其他查詢引擎更有效地處理使用 HDFS 的交互式查詢。 Hive 由於其磁盤 I/O 操作而慢得多,但 Apache 快得多,因為它是一個完全不同的引擎。 Impulsa 和 Presto 之間沒有區別,因為 Impulsa 使用更快的技術而 Presto 使用類似的架構。 對於 Parquet 文件,Impala 表現最好。 根據分析師的查詢確定應該對哪些數據進行分區。 使用 Compute Stats Statistics,您的查詢將變得更加容易,尤其是當它們涉及多個表(連接)時。 我們的 Impala 目錄服務器每週崩潰四次,我們的查詢花費了太長時間才能完成。
此外,我們創建的文件數量極大地影響了我們的查詢性能。 因此,我們開始管理我們的分區並將它們合併為大約 256MB 的最佳文件大小。 據說每個分區只有一個文件(除非它的大小> 256MB)。 應從隱式支持的所有數據類型中選擇最合適的列類型。 要限制並發查詢的數量或用戶訪問的 Y 內存,請使用 Impala Admission Control。 如果一個查詢持續超過 30 分鐘,它就被認為是死的。
大數據的最佳引擎:Impala
Impala引擎是專門為大型集群設計的Hadoop數據處理引擎。 與 Hadoop 的標準 MapReduce 引擎相比,它使用的能源和消耗的資源要少得多。 Implicit 採用分佈式文件系統 HDFS 作為其主要數據存儲介質,依靠 HDFS 的冗餘來防止逐個節點的硬件或網絡中斷。 表示表數據的數據文件在物理上由熟悉的 HDFS 文件格式和壓縮編解碼器表示。
並行處理查詢引擎
並行處理查詢引擎是一種數據庫引擎,旨在並行處理查詢。 這可以通過使用多個處理器、多個內核或多台機器來完成。 並行處理可以極大地提高查詢引擎的性能,尤其是對於復雜的查詢。
多處理器計算機用於將復雜的查詢轉換為可以並發執行的執行計劃,使其能夠一次處理大量數據。 高性能需要高效的執行,例如良好的查詢響應時間或高查詢吞吐量。 它是通過使用高效的並行執行技術和查詢優化來實現的。
並行處理:Etl 的未來?
高級查詢可以轉換為執行計劃,該執行計劃可以由多處理器計算機使用並行查詢處理有效地執行。 並行處理採用並行和分佈式數據相結合的技術,以及並行數據庫系統提供的各種執行技術。 ETL中的並行查詢處理是通過將分配給transfer的每個源表中的記錄集劃分成大小相同的chunk,然後循環對每個源表進行數據轉換過程,連續選擇數據,逐個chunk .