
Pig:Apache Hadoop 的高級平台
已發表: 2023-02-22Pig 是一個高級平台,用於創建在 Apache Hadoop 上運行的程序。 術語“Pig”指的是平台的基礎設施層,它由編譯器和執行環境以及一組高級運算符組成。 Pig 的基礎設施層為開發人員提供了一組工具來創建、維護和執行他們的 Pig 程序。 Pig 是一個開源項目,是Apache Hadoop 生態系統的一部分。 Pig 的編程模型是基於數據流的,這使得編寫處理大量數據的程序變得容易。 Pig 程序由一系列在有向無環圖中執行的運算符組成。 Pig 是處理大量數據的絕佳選擇,因為它可擴展、高效且易於使用。
作為 NoSQL 解決方案,您需要特定的預定義方法來分析和訪問數據。 SQL(UNION、INTERSECT 等)是一種常見的查詢表達式,在大數據領域中使用得併不多。 因為 Hive 針對批處理和大數據處理進行了優化,所以最好接觸每一行。 Hive 在操作上花費的時間和金錢遠少於 Hadoop,後者俱有規模優勢。 即使是開發系統上的小查詢也可能比 RDBMS 上的類似查詢慢 ORDERS 個數量級。 Hive 不緩存查詢結果。 重新提交重複查詢是 MapReduce 中的常見做法。
Hive有兩種類型:1)Hive不是數據庫; 相反,它是一個查詢引擎,支持特定於查詢數據的 SQL 部分 b) Hive 是一個支持 SQL 的數據庫 c) Hive 是一個特定於 SQL 的數據庫。 Hive 是一個基於 SQL 的 Hadoop 數據倉庫系統,包括 Pig 和 Python 等; Hive 用於存儲Hadoop 數據。
Pig 是 SQL 嗎?
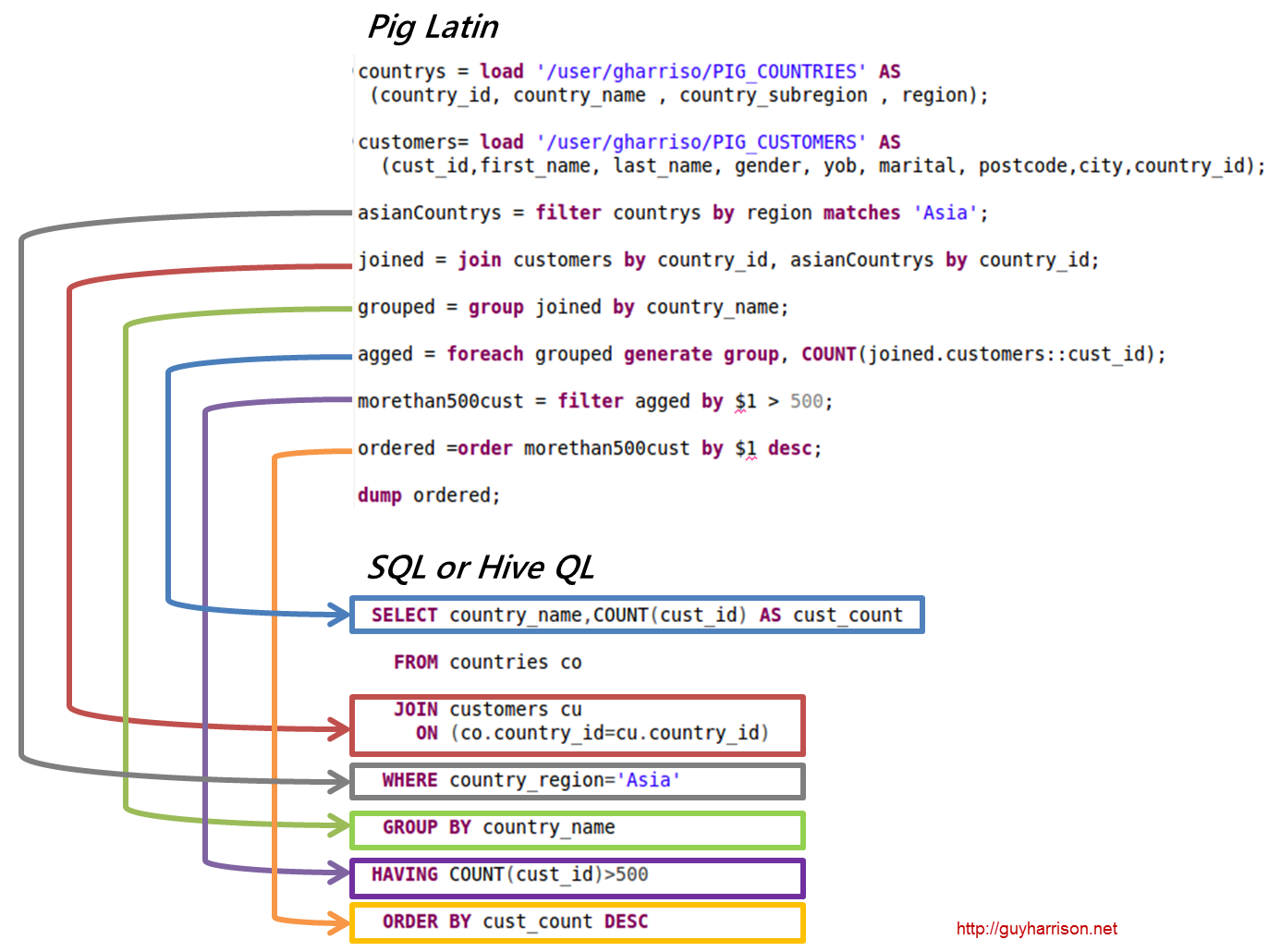
這個問題沒有正確或錯誤的答案,因為它取決於個人意見。 有些人可能認為 pig 是一個 sql,而其他人則可能不這樣認為。 pig是不是sql,歸根結底還是由個人決定。
如今, Apache Hive和 Pig 這兩個術語正迅速成為大數據的同義詞。 借助這些工具,數據開發人員和分析人員可以使用它們來降低 MapReduce 的複雜性,同時仍保持高水平的數據完整性。 Hive 是一種數據倉庫基礎設施,也稱為 ETL(提取、加載和轉換)工具。 Apache Hive、Pig 和 SQL 是三種流行的數據分析和管理工具。 您必須了解哪個平台最適合您的需求,以及您應該多久使用一次。 讓我們看看在這三種技術的上下文中使用 Hive、Pig 和 SQL 的三種不同方式。 儘管 Apache Hive 和 Apache Pig 佔據主導地位,SQL 仍然是大數據管理和分析領域的王者。 因為每個人都執行特定的功能,所以他們的要求是根據業務量身定制的。 Apache Pig 基於腳本並需要特殊知識,而 Apache Hive 是開發人員唯一的原生數據庫解決方案。
豬是一種多才多藝的動物,具有很大的靈活性。 例如,Pig 可以處理包含 JSON 或 XML 數據的日誌文件,從而允許您讀取數據。 也可以在 Pig 中存儲來自 Web 服務的數據。
地圖數據類型、元組和包數據類型可以互換使用。 他們能夠處理來自任何來源的數據。
Pig 是 Etl 工具嗎?
這個問題沒有明確的答案,因為它取決於您如何定義 ETL 工具。 一般來說,ETL 工具是一種軟件應用程序,可幫助您從一個或多個來源提取數據,將其轉換為與目標系統兼容的格式,並將其加載到該系統中。 有人會說 pig 是一個 ETL 工具,因為它可以執行所有這些功能。 其他人可能會爭辯說 pig 不是 ETL 工具,因為它不是專門為數據轉換而設計的。 最終,這個問題的答案取決於您自己對 ETL 工具的定義。

如何使用 Pig 進行 Etl 處理?
Pig 應用程序可以被描述為一個 ETL 事務模型,它描述了一個過程如何從一個對像中提取數據並將其轉換為基於規則集的數據存儲。 用戶定義 Pig 的用戶定義函數 (UDF),以便從文件、流和其他來源攝取數據。
什麼是 Pig 工具?
稱為 Pig 的平台或工具處理大型數據集。 該庫包含用於在 MapReduce 過程中處理數據的高級抽象。 Pig Latin 是一種高級腳本語言,在編碼過程中用於開發數據分析代碼。
Pig和Sql有什麼區別?
SQL Pig Latin和 Apache Pig 是過程語言。 SQL 是一種本質上是聲明性的腳本語言。 是否使用模式完全取決於 Apache Pig。 無需架構即可存儲數據(值類型存儲在 $、$ 等中)。
Pig 是 Hadoop 的一部分嗎?
Pig Hadoop 應用程序是一種高級編程語言,可用於分析海量數據集。 Yahoo! 的 Pig Hadoop 項目是最早的 Hadoop 項目之一。 通常,它在運行 Hadoop 時執行大量數據管理工作。
在大數據分析領域,Pig Hadoop 是一種高級編程語言。 為了使用 Apache Pig 分析數據,我們必須首先使用 Pig Latin 編寫腳本。 將轉換為MapReduce 任務的腳本。 這是通過使用 Apache Pig 擴展 Pig Engine 實現的。 按照以下步驟,您可以在 Linux/CentOS/Windows 上安裝 Apache Pig(通過 VM 或 Cloudera)。 第一步是下載並安裝 Apache Pig。 第二步是使用 bashrc 文件更改 Apache Pig 環境變量。
在第 3 步中,確定Pig 版本。 該文件移動後可以保存在其他目錄中。 第五步是通過單擊 Pig 命令啟動 Grunt Shell(用於運行 Pig Latin 的腳本)。
為什麼 Pig Latin 是最好的數據分析高級腳本語言
Pig Latin 數據分析代碼是用高級腳本語言編寫的。 它是一種類似於 SQL 的語言,旨在並行處理數據流。
Apache Pig 示例
Pig 是一個高級平台,用於創建在 Apache Hadoop 上運行的程序。 這個平台的語言叫做 Pig Latin。 Pig 可以在 MapReduce、Tez 或 Spark 中執行其 Hadoop 作業。 Pig Latin 將編程從 Java MapReduce 慣用語中抽象為一種符號,使 MapReduce 編程更容易。 例如,下面的 Pig Latin 語句等同於上面的 Java MapReduce 代碼: A = LOAD 'mydata' USING PigStorage(',') AS (id:int, name:chararray, age:int, gpa:float); 傾倒一個;