
您需要了解的 5 個最佳開源法學碩士 [2023 年 12 月]
已發表: 2023-12-19概括:
透過 2023 年排名前 5 名的開源大型語言模型 (LLM) 探索人工智慧創新的前沿。從 Falcon 突破性的 180B 參數到 BLOOM 的多語言能力,深入研究塑造未來的尖端功能。 了解 Llama 2、GPT-NeoX-20B 和 MPT-7B 的優勢和潛在應用,使企業能夠在不斷發展的 AI 領域安全擴展。
介紹
人工智慧 (AI) 世界正在快速變化,其中很大一部分變化來自大型語言模型 (LLM)。 這些不僅僅是常規工具; 他們就像是科技新階段的領導者。 將它們視為真正的智慧系統,正在改變我們使用手機、電腦和其他小工具的方式。
企業可以選擇開源 LLM(大型語言模型)軟體,而不是依賴 ChatGPT、Claude.ai 或 Phind 等外部聊天機器人服務來解決隱私和安全問題。 在您的電腦上執行開源 LLM 可確保敏感資料和機密資訊保持在企業的控制範圍內,從而最大限度地降低暴露於外部實體的風險。 這種方法在互動可能由人類審查或用於訓練未來模型的平台上尤其重要。 透過在本地利用開源LLM軟體,企業可以保持更高水準的資料安全性和機密性,解決與外部應用程式相關的潛在隱私問題。
令人興奮的是,許多法學碩士都是開源的。 這意味著任何有興趣和一些技術技能的人都可以使用它們、改變它們,甚至改進它們。 這就像擁有一個超級聰明的人工智慧朋友,你可以向他學習並教授新技巧。

2023 年排名前 5 位的開源法學碩士
在這篇部落格中,我們將介紹其中五個令人驚嘆的開源法學碩士。 每一個都有其獨特之處,為人工智慧世界帶來了新的想法和能力。
獵鷹法學碩士

Falcon LLM 是由阿布達比技術創新學院 (TII) 開發的突破性大型語言模型 (LLM)。 它旨在推動應用程式和用例,確保我們世界的未來彈性。 該套件目前包含 Falcon 180B、40B、7.5B 和 1.3B 參數 AI 模型,以及精心策劃的 REFINEDWEB 資料集。 他們共同提出了多樣化且全面的解決方案。
以下是其主要特徵、優勢和潛在用途的全面細分,以及進一步探索的相關來源:
主要特徵:
- 海量:Falcon 180B 擁有 1800 億個參數,擁有令人印象深刻的學習和性能能力,超過了其他幾個開源法學碩士。
- 高效訓練:在包含 3.5 兆代幣的精細資料集上進行訓練,確保準確性和質量,同時優化資源使用。
- 開源可用性:程式碼和培訓數據可在 Hugging Face 上公開獲取,從而提高透明度和社群貢獻。
- 卓越的表現:Falcon 在各種基準測試中均優於 GPT-3,同時需要較少的訓練和推理資源,使其成為更有效率的選擇。
- 模型多元:TII提供各種Falcon版本,包括180B、40B、7.5B、1.3B參數AI模型,針對長篇故事寫作等特定任務的專用模型。
優勢:
- 高品質的資料管道:TII嚴格的資料過濾和重複資料刪除流程確保Falcon的訓練資料準確可靠。
- 多語言功能:Falcon 可以有效地處理多種語言,儘管它的主要重點是英語。
- 微調潛力:Falcon 可以針對特定任務進行微調,進一步增強其性能和適應性。
- 社群驅動的發展:開源性質允許協作改進和研究,加速 Falcon 的發展。
潛在應用:
- 自然語言處理(NLP):Falcon 可以在各種 NLP 任務中表現出色,例如文字摘要、情緒分析和對話生成。
- 創意內容生成:此模型可以幫助作家和藝術家產生不同的創意格式,如詩歌、劇本和音樂作品。
- 教育與研究:個人化學習經驗、教育內容產生和研究支持都是潛在的應用。
- 商業和行銷:Falcon 可以為智慧聊天機器人提供支援、個人化行銷活動並有效分析客戶數據。
其他資源:
- Falcon LLM網址:https://www.tii.ae/news/abu-dhabi-based-technology-innovation-institute-introduces-falcon-llm-foundational-large
- 抱臉獵鷹模型卡:https://huggingface.co/spaces/tiiuae/falcon-180b-demo
- TII Falcon 部落格文章:https://huggingface.co/tiiuae/falcon-180B
- Falcon-180B 上的 YouTube 影片:https://www.youtube.com/watch?v=9MArp9H2YCM
美洲駝2

Llama 2 是由 Meta AI 和 Microsoft 開發的開源大型語言模型,展示了產生從詩歌到程式碼、回答問題和翻譯語言等各種內容的卓越能力。 它在推理和編碼基準方面優於其他法學碩士,透過強化學習強調安全性並提供「負責任的使用指南」。 雖然仍處於開發階段,但使用者應意識到潛在的不準確性、偏差的輸出以及需要技術專業知識才能實現最佳使用。 負責任的利用對於釋放 Llama 2 徹底改變各個領域的全部潛力至關重要。
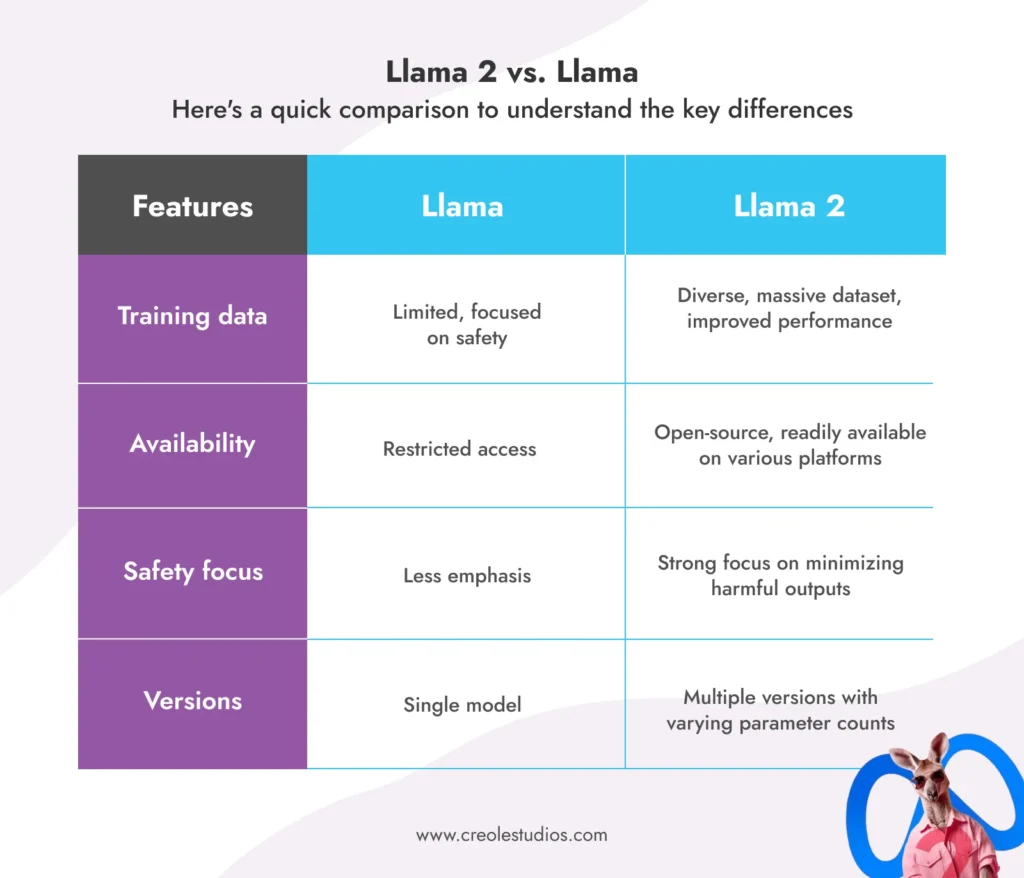
Llama 2 建立在原版 Llama 的基礎上,在幾個方面超越了其前身:
- 多樣化訓練:在更大且多樣化的資料集上進行訓練,確保更好地理解不同任務並提高效能。
- 開放可用性:與其前身的有限存取權不同,Llama 2 可以隨時在 AWS、Azure 和 Hugging Face 等平台上用於研究、開發甚至商業應用程式。
- 安全重點:Meta 透過採取措施盡量減少錯誤訊息、偏見和有害輸出,將安全放在首位。
- 增強訓練:提供不同版本,參數數量從70億到700億,滿足不同的需求和資源。
美洲駝 2 與美洲駝:
以下是一個快速比較,以了解主要差異:
Llama 2 的潛在應用:
- 聊天機器人和虛擬助理:改進的對話功能可以實現更自然、更有吸引力的互動。
- 文字生成和創意內容:產生不同的創意格式,如詩歌、腳本或程式碼,為作家和藝術家提供幫助。
- 程式碼產生和程式設計:幫助開發人員完成程式碼完成和錯誤偵測等任務。
- 教育與研究:個人化學習體驗、產生教育內容並協助研究人員完成各種任務。
- 業務和行銷:透過聊天機器人增強客戶服務、個人化行銷活動並分析客戶數據。
限制和注意事項:
- 與所有法學碩士一樣,Llama 2 仍在開發中,可能會產生不準確或偏差的輸出。
- 負責任且合乎道德的使用對於避免潛在的濫用和偏見至關重要。
- 不同的版本需要不同的運算資源,因此選擇正確的版本非常重要。
資源:
- Meta AI LLAMA 網址:https://ai.meta.com/blog/large-language-model-llama-meta-ai/
- 關於 LLAMA2 的 Meta AI 部落格文章:https://ai.meta.com/blog/large-language-model-llama-meta-ai/
- Hugging Face LLAMA2 模型卡:https://huggingface.co/models?search=llama
布魯姆法學碩士

Bloom LLM 誕生於全球社群的共同努力,已成為開源人工智慧領域的真正力量。 以下是其主要功能、潛在應用及其獨特之處的全面細分:
什麼是 BLOOM LLM?
BLOOM 是一個龐大的多語言法學碩士,擁有 1760 億個參數,並接受了驚人的 46 種語言和 13 種程式語言的培訓。 BLOOM 是透過 Hugging Face 和來自 70 多個國家的研究人員為期一年的合作計畫開發的,體現了開源人工智慧的精神。

BLOOM 的主要特點:
- 多語言能力:以多達 46 種語言產生連貫且精確的文本,超越了典型的以英語為中心的模型。
- 開源存取:原始程式碼和培訓數據都是公開的,從而促進透明度和社群驅動的改進。
- 自回歸文字生成:無縫擴展和完成文字序列,使其成為各種創意和資訊任務的理想選擇。
- 海量參數數量:BLOOM 擁有 1,760 億個參數,躋身最強大的開源 LLM 之列,提供卓越的效能。
- 全球合作:此模型的發展體現了國際合作在推動人工智慧技術方面的力量。
- 免費存取:任何人都可以透過 Hugging Face 平台存取和使用 BLOOM,從而實現尖端 AI 工具的民主化。
- 工業規模培訓:使用大量計算資源對大量文字資料進行培訓,確保穩健的效能。
BLOOM 的潛在應用:
- 多語言交流:透過翻譯文本和產生特定語言的內容來促進跨文化交流。
- 創意寫作與內容生成:以詩歌、劇本、程式碼、音樂作品等多種形式協助作家和藝術家。
- 教育與研究:個人化學習體驗、產生教育材料並支持各領域的研究工作。
- 業務與行銷:透過多語言聊天機器人增強客戶服務、個人化行銷活動並有效分析數據。
- 開源人工智慧開發:作為開源人工智慧進一步研究和開發的基礎,促進社群創新。
BLOOM 有何獨特之處?
- 多語言關注:與許多主要關注英語的法學碩士不同,BLOOM 的多語言能力為全球溝通和理解開闢了新的可能性。
- 開放性和透明度:公眾對程式碼和培訓資料的存取允許更廣泛地參與改進和利用模型。
- 協作開發:該模型透過全球協作創建,展示了開源人工智慧在彌合地理和文化障礙方面的潛力。
限制和注意事項:
- 與所有法學碩士一樣,BLOOM 仍處於開發階段,可能會產生不準確或偏差的輸出。 負責任且合乎道德的使用至關重要。
- 有效利用 BLOOM 需要一些技術知識並了解其功能。
- 該模型的大尺寸可能需要大量的計算資源來執行某些任務。
資源:
- BigScience BLOOM 網址:https://huggingface.co/bigscience/bloom-intermediate
- Hugging Face BLOOM 模型卡:https://bigscience.huggingface.co/blog/bloom
- BLOOM 上的 BigScience 部落格文章:https://huggingface.co/bigscience/bloom
- GitHub 上的 BLOOM 模型卡儲存庫:https://github.com/bigscience-workshop/model_card
GPT-NeoX-20B

這是另一個嶄露頭角的開源法學碩士,展現了非凡的能力和潛力。 以下是其主要特性、優勢和潛在應用的詳細介紹:
什麼是 GPT-NeoX-20B?
- GPT-NeoX-20B 由 EleutherAI 開發,是一個在 Pile(海量文字和程式碼資料集)上訓練的 200 億參數自回歸語言模型。
- 其架構借鑒了 GPT-3,但進行了重大優化,以提高效能和效率。
- GPT-NeoX-20B 在多個領域表現出色:
- 少樣本推理:在需要理解和應用有限範例中的資訊的任務上表現得非常好。
- 長文本生成:即使對於很長的序列,也能產生連貫且語法正確的文本。
- 程式碼產生與分析:可以理解和產生程式碼,協助開發人員完成各種任務。
GPT-NeoX-20B 的優點:
- 開源:模型的程式碼和權重是公開的,鼓勵社群貢獻和研究。
- 高效訓練:利用 DeepSpeed 庫進行高效訓練,與其他法學碩士相比,需要更少的運算資源。
- 強大的小樣本學習:在數據有限的任務上表現出色,使其能夠適應不同的場景。
- 長文本生成:即使對於冗長的序列也能產生連貫且語法正確的文本,非常適合創意寫作和內容生成。
- 程式碼產生和分析:理解並產生程式碼,可能有助於開發人員進行錯誤偵測、程式碼完成和其他任務。
GPT-NeoX-20B 的潛在應用:
- 個人助理和聊天機器人:增強理解和回應複雜問題和請求的能力。
- 創意寫作與內容生成:協助作家和藝術家產生不同的創意形式,如詩歌、劇本、音樂作品等。
- 教育與研究:個人化學習體驗、產生教育內容並支持各領域的研究。
- 軟體開發:協助開發人員完成程式碼完成、錯誤偵測和程式碼分析等任務。
- 開源人工智慧研究:作為開源人工智慧進一步研究和開發的基礎,促進創新。
限制和注意事項:
- 與所有法學碩士一樣,GPT-NeoX-20B 仍在開發中,有時會產生不準確或偏差的輸出。 負責任且合乎道德的使用至關重要。
- 充分利用其潛力可能需要一些技術知識並了解其功能。
- 模型的大小可能需要大量的計算資源來執行某些任務。
資源:
- EleutherAI GitHub 儲存庫:這是 GPT-NeoX-20B 的官方儲存庫,您可以在其中找到原始程式碼、訓練腳本和預訓練模型。 (圖片來源:https://github.com/EleutherAI/gpt-neox)
- Hugging Face 模型卡:Hugging Face 模型卡提供了 GPT-NeoX-20B 的全面概述,包括其功能、限制和基準測試結果。 (圖片來源:https://huggingface.co/EleutherAI/gpt-neox-20b)
- EleutherAI 部落格文章:EleutherAI 的這篇部落格文章介紹了 GPT-NeoX-20B,討論了其架構和訓練過程,並重點介紹了其一些潛在應用。 (資料來源:https://www.opensourceforu.com/2022/04/eleutherai-releases-gpt-neox-20b-a-20-billion-parameter-ai-language-model/)
MPT-7B

MPT-7B是 MosaicML Pretrained Transformer 的縮寫,是由 MosaicML Foundations 開發的強大的開源 LLM。 它擁有 70 億個參數,並接受了 1 兆個代幣的海量資料集的訓練,使其成為 LLM 領域的有力競爭者。 以下是其主要功能和潛在應用的細分,以及一些進一步探索的相關來源:
主要特徵:
- 商業許可:與許多開源模式不同,MPT-7B 獲得商業用途許可,為企業利用其功能打開了大門。
- 廣泛的訓練資料:MPT-7B 在 1 兆個代幣的多樣化資料集上進行訓練,確保了跨各種任務的穩健性能和適應性。
- 長輸入處理:該模型可以在不影響準確性的情況下處理極長的輸入,使其成為總結冗長文件等任務的理想選擇。
- 速度和效率:MPT-7B 針對快速訓練和推理進行了最佳化,可及時提供結果,這對於實際應用至關重要。
- 開源程式碼:此模型高效的開源培訓程式碼提高了透明度並促進社群為其開發做出貢獻。
- 卓越對比:與 7B-20B 參數範圍內的其他開源模型相比,MPT-7B 表現出了卓越的性能,甚至可以與 LLaMA-7B 的品質相媲美。
潛在應用:
- 預測分析:MPT-7B 可以分析大型資料集以識別模式和趨勢,為業務決策提供資訊並優化營運。
- 決策支援:此模型可以根據分析的數據提供見解和建議,從而協助複雜的決策過程。
- 內容生成與摘要:MPT-7B可以產生不同的創意文字格式,如詩歌、腳本或程式碼,或有效地總結長文件。
- 客戶服務聊天機器人:透過理解自然語言和上下文,MPT-7B 可以為智慧聊天機器人提供支持,以改善客戶服務體驗。
- 研究與發展:此模型可以透過分析數據、產生假設和協助創造性探索來支持各領域的研究工作。
其他資源:
- MosaicML MPT-7B 網址:https://www.mosaicml.com/blog/mpt-7b
- Hugging Face MPT-7B 模型卡:https://huggingface.co/mosaicml/mpt-7b
- MPT-7B 上的 MosaicML 部落格文章:https://www.mosaicml.com/blog/mpt-7b
利用 Creole Studios 的開源法學碩士
開源大型語言模型 (LLM) 正在重塑人工智慧,為企業提供靈活性和創新。 它們非常適合創建新技術解決方案和降低開發成本。 然而,資料隱私和針對特定業務需求的客製化等挑戰可能很複雜。
Creole Studios 是您應對這些挑戰的理想合作夥伴。 我們在人工智慧和機器學習方面的專業知識意味著我們可以幫助您的企業高效、安全地利用開源法學碩士的全部潛力。 我們專注於創建符合您獨特目標的客製化解決方案,確保您在快速發展的人工智慧領域保持領先地位。
與 Creole Studios 合作,利用開源法學碩士的力量改變您的 AI 之旅。