
為什麼最終一致性對數據存儲至關重要
已發表: 2022-11-17最終一致性是數據存儲的一個屬性,其中寫入存儲的數據可能無法立即讀取。 存儲最終可能會提供數據供讀取,但不保證一定會這樣做。 表現出最終一致性的數據存儲系統可能出於各種原因這樣做,包括需要提高性能或確保面對網絡分區時的可用性。
實現文檔數據存儲實現比實現關係模型要困難得多。 此外,機上存儲數據比 RDBMS 數據更難轉換。 害怕或沒有意識到他們的錯誤後果的開發人員和架構師錯過了這個機會。 他們將把原子事務應該包含的內容分解成邏輯部分,忘記了複製和延遲是事物,並將第三方系統拖入其中。 在某個時候,所有系統都將外包,隨著部門最終解散,其他人將接管。
因此,NoSQL 數據庫經常支持漸進一致性而不是恆定一致性。 不需要強數據一致性,因為它們不支持數據庫事務。 通過確保所有更新同時交付給所有副本,始終可以實現最終一致性。
最終一致性指的是主節點和輔助節點之間的複製過程,以及您的應用程序可能並不總是讀取數據最新的事實,因此主讀取成為必經之路。
當 NoSQL 數據庫使用最終一致性模型時,它們不提供與 SQL 數據庫相同級別的數據一致性。 如果數據不一致,這會使它們不適用於銀行和 ATM 交易等需要即時完整性的交易。
最終一致性在 Nosql 中意味著什麼?
最終一致性是一種保證,如果沒有對數據進行新的更新,最終所有對該數據的訪問都將返回最後更新的值。 這與強一致性形成對比,強一致性要求每次讀取都收到最新的寫入。
最終一致行為的概念在 20 世紀 70 年代後期首次受到關注。 亞馬遜在十年前發布了 DynamoDB,這引發了該術語的流行。 數據庫 NoSQL 已開髮用於支持社交媒體和流媒體服務。 輕鬆管理圖片、視頻、音頻等非結構化數據。 使用 Volt Active Data 模型,可以確保跨多個數據庫實時復制數據。 數據平台立即一致並防止不一致的寫入和讀取。 因此,他們非常有能力通過快速處理這個過程來滿足 5G 的延遲要求。
一致性可能是分佈式系統的一個有價值的特性。 它確保值在一致的基礎上被多個節點存儲和訪問,無論這些節點是否同時更新。 對於域名系統等系統而言,能夠保持一致的數據視圖至關重要。
項目完成後的一致性有時很難實現。 由於可用的方法多種多樣,因此很難確保所有節點都收到相同的更新。 一致性的價值是不可否認的,使用它的系統從長遠來看可能會更可靠。
Cassandra 中的最終一致性是什麼?

Cassandra 通過一致的存儲系統實現所有這些功能,該存儲系統可以滿足生產中的性能、可靠性、可擴展性和可用性要求。 最後,一致意味著所有更新最終都與所有副本共享。
一致性是 Cassandra 可以通過其可調一致性實現的。 如果 N 是節點數,則 R=w <=N 結果應該是一致的。 為了達到一致性,每一列和每一列的字段都由Cassandra備份。 這種狀態背後有一種機制可以使其保持一致。 如果 N 始終是實數,則 R + W 是實數。 客戶端必須選擇適當的一致性級別(零、任意、一、法定人數或無)。 一致性不會立即發生,因為儘管複製因子為 1:1,寫入仍會緩沖在您將它們發送到的節點上。
Cassandra 採用一致性哈希,這意味著當使用相同的算法和哈希函數參數對一組鍵進行哈希處理時,哈希函數總是產生相同的結果。
這很關鍵,因為它允許您將一個密鑰保存在多個存儲桶中,而不必擔心它與任何東西發生衝突。
因此,一致性哈希被認為效率更高,因為它允許 Cassandra 在相同的空間量中存儲更多的數據。
如果你想實現強一致性,你必須確保你的寫入和讀取計數是一致的。 Cassandra 的一致性建立在這樣的假設之上,即所有客戶端讀取始終通過自動獲取最新的寫入數據來保持最新。 一致性哈希用於確保如果使用相同的算法和哈希函數參數將兩個不同的密鑰哈希在一起,哈希函數始終會產生相同的結果。 將密鑰保存在多個存儲桶中至關重要,因為衝突不是問題。 Cassandra 具有更高的性能,因為它可以通過一致性哈希在相同數量的空間中保存更多數據。
Cassandra 中的默認一致性級別是多少?
只需調用 QUBEDBUILDER 即可使用 Java 驅動程序。 設置 ConsistencyLevel 以確保每次插入的一致性級別都在 insertInto 中設置。 寫入和讀取時,為所有操作分配一致性級別 1。
如何使用 Cassandra 確保數據一致性
這樣做的主要原因是密鑰在散列之前不會存儲在桶中。 Cassandra 還將密鑰和指向存儲桶的指針存儲在表的同一行中。 Cassandra 比較鍵的行和鍵值上方的值的指針,以確定哪一行對應於哪個鍵。 如果兩者都為真,Cassandra 將在指針處從桶中取值。 一個鍵的值無論被詢問多少次,總是存儲在同一行中,只要它存儲在同一行中即可。 當多次重複讀數時,數據保持不變。 如果您想更改當前會話的一致性級別,只需使用 cassandra shell (CQLSH) 中的 CONSISTENCY命令。 如果你想看看你在一致性水平上有多遠,你可以使用 CONSISTENCY; 從外殼。 [電子郵件保護] | Consistency:一致性當前的一致性級別是一級。
什麼是 Nosql 中的更新一致性

NoSQL 中的更新一致性是在NoSQL 數據庫中跨多個節點更新數據的過程。 此過程確保數據庫中的所有節點都具有相同的數據,並且數據在所有節點之間是一致的。

Nosql 中的更新一致性是什麼?
相同複製數據庫系統 [1] 中相同數據副本的一致性,與數據如何更改相反,只是一個選擇問題。 當給定數據對象的讀數與之前的更新不一致時,就會發生這種情況。
什麼是數據庫中的更新一致性?
數據庫系統中的一致性概念要求任何給定的數據庫事務只允許以允許的方式修改受影響的數據。 寫入數據庫的數據必須遵守所有定義的規則,例如約束、級聯、觸發器以及這些規則的任意組合。
最終一致性 MongoDB

最終一致性是一個技術術語,表示您正在閱讀的數據並不總是一致的; 然而,隨著時間的推移,它會有所改善。 這樣做的唯一方法是使用任何可以從輔助源讀取的 readPreferences 從輔助源讀取。
作為第一步,我將回顧一些違反因果一致性保證的實際 MongoDB 代碼示例。 大多數讀寫方法將在第一次嘗試中使用來解決這個問題。 因此,我們將研究 Mongo 中的邏輯時鐘和相關會話。 我們將為此應用程序使用 Mongo C# 驅動程序,但我不想管它。 如果來自查詢的數據已被確認,則大多數副本集成員必須簽署多數讀取。 當我們使用多數讀後跟多數寫時,看起來我們可以解決“Read Your Write”問題。 輔助服務器維護最近多數寫入的內存快照。
Mongodb 的 Readconcern 設置
客戶端必須確定應該允許讀取多少數據才能滿足 readConcern,然後才能開始滿足 readConcern。 在 MongoDB 中,最好將 readConcern 設置為 maxRead。
最終一致性與強一致性
它以比其他技術更低的延遲提供最新數據,但它也需要高度的持久性。 因為數據庫可能不會在所有節點上都有更新的數據,所以最終一致性可能會提供低延遲,但可能不會總是用陳舊的數據回复讀取請求。
一致性通常是指數據庫處理事務同時保持數據完整性的能力。 符合 ACID 法規的數據庫系統通常速度慢、難以擴展,並且維護和操作的成本高得令人望而卻步。 一些 RDBMS 系統減輕了 ACID 保證。 NoSQL 數據庫的基本保證稱為其 NoSQL 算法。 因此,該基礎可用於提高可用性,同時還允許放寬嚴格的標準。 因此,NoSQL 數據庫需要大量的一致性才能更加穩定。 當 DynamoDB 的最終一致性由環形拓撲決定時,它就變成了 Cassandra。
為了處理一致的結果,Redis 中使用了主從拓撲。 ScyllaDB 是一家位於荷蘭的實時大數據數據庫公司。 此外,它可用於為每個操作(讀取或寫入)指定一致性級別。 由於協調器節點上的數據可能已更改,但尚未記錄並存儲在所有必需的副本上,因此 ScyllaDB 集群提供一致的結果。
計算機系統一致性最重要的方面之一是它的一致性。 無論數據如何存儲,都可以以這種方式處理數據,因為它確保了一致性。 因此,例如,金融機構經常採用隨著時間的推移保持一致的系統。 由於此過程,大多數交易將盡快完成。 一筆交易最多可能需要 24 小時來處理,但我們不能保證這一點。 這種現像是由最終將存在的一致系統的一般模式引起的。
數據一致性:如何根據您的需要選擇正確的類型
說到數據,有兩種類型:強數據和弱數據。
因為節點中的所有數據都是一致的,無論它駐留在何處,它始終是相同的。 此方法是最可靠的數據一致性方法,但可能難以實施。
缺乏一致性表示無法保證所有節點同時擁有相同的數據。 這種一致性更容易損壞,但有時也更有效。
最終一致性卡桑德拉
最終一致性是分佈式系統中使用的一致性模型。 在最終一致的系統中,操作可能需要一些時間才能傳播並在所有節點上變得可見。 當寫入操作在發出它的節點上持久時,它被認為是成功的。 當讀取操作返回最近的寫入操作時,它被認為是成功的。 最終一致性通常用於分佈在多個數據中心的系統中。 在這些系統中,由於增加的延遲和潛在的故障,保持強一致性是不切實際的。 最終一致性允許系統即使在出現故障時也能繼續運行。 Cassandra 是一個使用最終一致性的分佈式數據庫。 Cassandra 旨在以高可用性處理大量數據。 Cassandra 被世界上一些最大的公司使用,包括 Facebook、Netflix 和 Instagram。
它是一個開源的 NoSQL 數據庫,具有高度可用和可擴展的架構。 需要跨集群複製數據才能在 Cassandra 中實現高可用性。 有兩種複制策略可用:SimpleStrategy 和 NetworkTopology。 每行數據如何由副本表示的一致性反映了它們的最新程度和同步程度。 一致性級別表示在協調器可以成功將數據發送回客戶端之前,有多少副本節點必須響應最近的一致數據。 根據客戶端指定的一致性級別,我們可以為每個寫入查詢設置一致性級別,也可以為每個全局查詢設置一致性級別。 寫作時,請記住一致性級別 (CL)。
5.1只有一個replica節點返回數據,5.2所有數據中心51%的replica節點返回數據。 我們首先為 Cassandra 寫入和讀取定義了所需的一致性級別 (CL)。 因此,無論最近一次寫入和下一次寫入之間需要多長時間,您都會將最近寫入的數據讀入集群。 為了保證一致性,我們可以指定一個全局或者寫查詢的一致性級別。 以下是 CL on read 的幾個示例,您可以在下圖中看到。
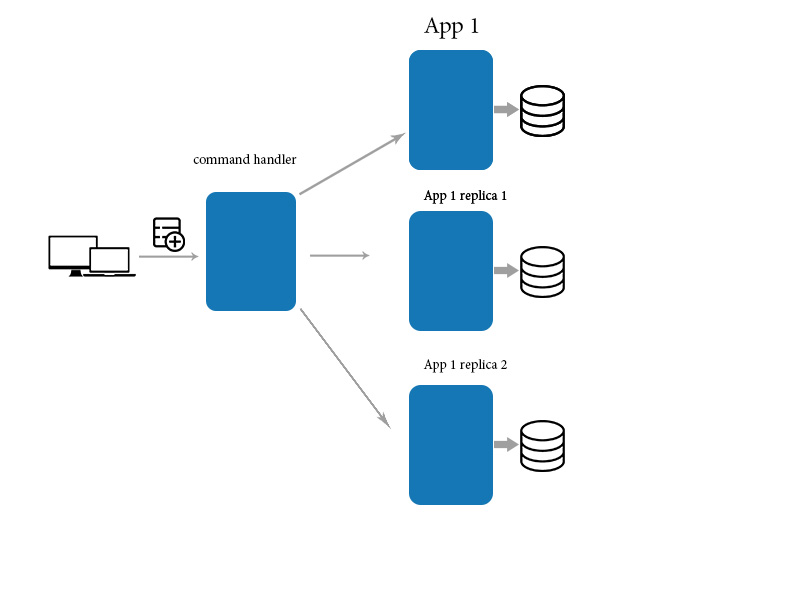
什麼是微服務中的最終一致性
實際上,最終一致性是一種通過異步通信來維護數據一致性和可用性,以及確保解決特定流程中的錯誤而不必恢復到流程之前狀態的方法。
在大多數情況下,我們都遇到過軟件系統中數據不一致的問題。 它基於去中心化的方法,並受到大自然的啟發。 隨著雲計算、彈性計算和存儲越來越流行,容器技術和編排越來越流行,大量新的應用正在使用微服務架構風格構建。 當原子事務跨越多個服務時,它們被視為每個服務級別的簡單原子本地事務鏈。 當由於特定情況導致此鏈中的一筆交易失敗時,它實質上會觸發撤消操作。 補償電話或交易也可能失敗。 數據一致性和集成是數據管理中最常見的兩種方法,它們是 Kafka 和 CDC。
CDC 適合大型分佈式架構,因為它不太注重性能。 CDC 在模式更改方面缺乏靈活性是最重要的缺點之一。 這極大地限制了服務數據庫模式的演進。