
為什麼 NoSQL 數據庫更適合分類應用
已發表: 2023-01-11這個問題沒有明確的答案,因為它取決於許多因素,包括組織的具體需求和員工的專業知識。 但總的來說,NoSQL 數據庫比 SQL 數據庫更適合分類學應用,原因如下: 1. NoSQL 數據庫在模式設計方面更靈活。 這意味著它們可以更輕鬆地適應數據結構的變化,例如新字段或項目之間關係的變化。 2. NoSQL 數據庫可以比 SQL 數據庫更有效地處理大量數據。 這是由於它們的水平可擴展性,允許它們將負載分散到多個服務器上。 3. NoSQL 數據庫比 SQL 數據庫更能抵抗故障。 這是因為它們旨在跨多個服務器自動複製數據,因此如果一台服務器出現故障,數據仍然可以在另一台服務器上使用。
NoSQL 系統被定義為可以存儲大量數據的分佈式非關係數據庫系統。 它們基於對敏捷性、性能和規模的需求,並且可以在各種環境中使用。 NoSQL數據庫可以橫向擴展,並且內置了面向數億甚至數十億用戶的橫向擴展。 Cameron Purdy,前 Oracle 高管和 Java 佈道者,解釋了 NoSQL 數據庫的工作原理以及它們如何變得極快。 NoSQL 數據庫可以在很短的時間內大規模處理大量數據。 它將非結構化數據存儲在多個節點和多個服務器上,同時保持持續可用性。 NoSQL 分析是否比使用 HTML 腳本的分析更好? 這是一個非常重要的決定,因為它考慮了許多因素,例如要分析的數據類型、要收集的數據量以及所需的速度。 如果你需要分析社交媒體、文本或地理數據等半結構化數據,NoSQL 類型的數據庫如 MongoDB 或 CouchDB 是最好的選擇。
可以運行 NoSQL 查詢,但速度要慢得多。 它在您的應用程序中具有很高的交易量。 SQL 數據庫比其他數據庫更穩定並確保數據完整性,使其成為重型或複雜事務的絕佳選擇。 必須嚴格遵守 ACID。
由於 NoSQL 數據庫靈活、可擴展、功能強大且易於使用,因此非常適合用戶體驗至關重要的各種現代應用程序,例如移動、Web 和遊戲。
NoSQL 數據庫比關係數據庫更適合在一個數據庫中存儲和建模結構化、半結構化和非結構化數據。
NoSQL 數據庫通常比 SQL 數據庫更快,特別是對於鍵值存儲; 但是,NoSQL 數據庫可能不完全支持 ACID 事務,這會導致數據不一致。
Sql 和 Nosql 哪個數據庫更好?
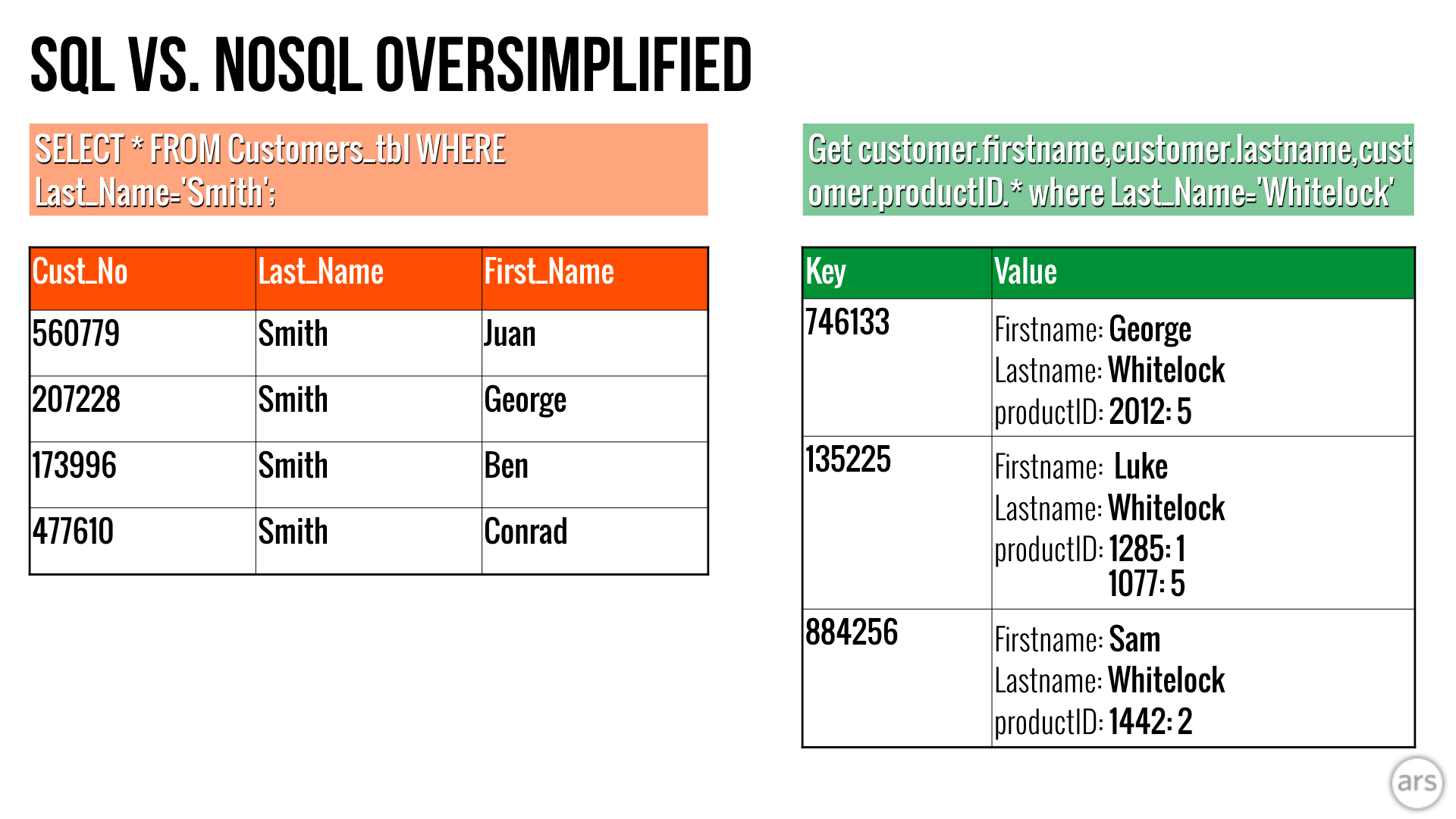
SQL 數據庫在多行事務中比 NoSQL 數據庫在非結構化數據(如文檔或 JSON)中更有效。 圍繞關係數據庫構建的遺留系統也稱為 SQL 數據庫。
數據科學,以其最基本的形式,是數據科學所有子領域的基礎。 絕大多數時候,您需要的數據存儲在數據庫管理系統 (DBMS) 中。 DBMS 的語言可用於與其交互和通信。 SQL(結構化查詢語言)是用於與 DBMS 交互的腳本語言。 近年來出現的一個新名詞是NoSQL數據庫。 非關係數據庫中的表和記錄可以被銷毀,法律不要求在其中存儲數據。 相反,數據存儲結構是針對特定要求進行設計和優化的,以滿足他們的需求。

除了列和數據庫,鍵值對也很流行,圖數據庫也是如此。 面向文檔的數據庫可以在 Python 數據庫 MongoDB 中找到。 的確,NoSQL 數據庫允許您創建更靈活的數據結構。 另一方面,SQL 數據庫具有更嚴格的結構以及更不靈活的數據類型。 從 SQL 開始,然後遷移到 NoSQL 可能是新人的最佳選擇。 您可以根據自己的數據、應用程序以及從中獲得的收益來決定哪種方式最適合您。 SQL 仍然不是最好的編程語言,也不是最好的 NoSQL 實現。 如果您傾聽您的數據,您將能夠做出最佳決定。
儘管 NoSQL 數據庫比 SQL 數據庫便宜,但它們還提供更快的查詢、更靈活的數據模型和更容易的開發。 換句話說,這在很大程度上取決於您的組織需要什麼以及需要多少數據。
哪個數據庫最適合分層數據?
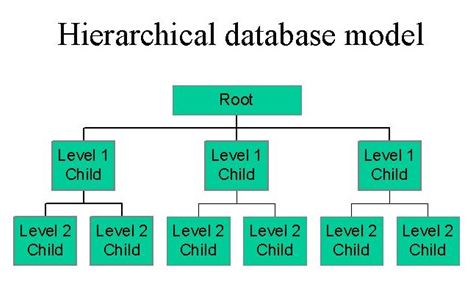
這個問題沒有明確的答案,因為它取決於應用程序的特定需求。 存儲分層數據的一些常見選擇是關係數據庫、面向對象的數據庫和XML 數據庫。
它是一種使用標準方法存儲和組織數據的軟件程序。 層次數據庫模型是一種數據模型,其中記錄作為記錄存儲,同時在父級和級別的幫助下鏈接到樹狀結構。 IMS 是使用最廣泛的數據庫之一。 使用分層數據庫可以實現基於層次結構的數據表示。 分層數據庫,例如 IBM 的信息管理系統 (IMS) 和 RDM Mobile,是最受歡迎的數據庫之一。 XML 和 XAML 是兩種比較流行的數據存儲類型,其中 XPath 和 XAML 最常用於基於分層數據模型。 創建文件時,它們分佈在整個根節點中。
數據按邏輯組織,因此很容易找到您要查找的內容。 層次結構可以通過使用保持其完整的數據查詢來保留。 許多應用程序或腳本可以訪問數據。 需要分層的表結構。 hierarchyid 函數用於創建分層數據表。 在此函數中,有兩個參數:表名和層次結構 ID。 在此示例中,我們展示瞭如何為 CompanyName 和 ProductName 表創建一個具有層次結構 ID 的表。 在hierarchy中,首先要選擇hierarchyid(name, id)。 從公司名稱。 PRODUCTS: PRODUCTS: PRODUCTS: PRODUCTS: PRODUCTS 公司名和產品名表的層級ID,用的是這裡的表。 hierarchyid 函數返回公司名稱和產品名稱表中公司和產品名稱的層次結構 ID。 對於表,使用 hierarchyid 函數返回值 5。